Оглавление
Искусственный интеллект достиг переломного момента в кибербезопасности — модели теперь действительно полезны на практике, а не только в теории. Anthropic пишет о значительном прорыве в возможностях Claude для защиты цифровой инфраструктуры.
Переломный момент в кибербезопасности
За последний год возможности ИИ-моделей в области кибербезопасности кардинально изменились. Если ранее модели демонстрировали ограниченную эффективность для сложных задач, то сейчас ситуация изменилась:
- Claude смог воспроизвести одну из самых дорогостоящих кибератак в истории — взлом Equifax 2017 года — в симуляции
- Модель превзошла человеческие команды в кибербезопасностных соревнованиях
- Claude помог обнаружить уязвимости в собственном коде Anthropic и исправить их до релиза
В летнем конкурсе DARPA AI Cyber Challenge команды использовали языковые модели (включая Claude) для создания систем кибер-рассуждений, которые анализировали миллионы строк кода на наличие уязвимостей. Помимо искусственно внедренных уязвимостей, команды обнаружили (и иногда исправили) ранее неизвестные, несинтетические уязвимости.
То, что еще год назад казалось научной фантастикой — ИИ, способный находить реальные уязвимости в коде — стало рабочей реальностью. Особенно впечатляет, что модель среднего уровня Sonnet 4.5 обгоняет флагманскую Opus 4.1 всего через два месяца после ее релиза. Это говорит об экспоненциальном темпе прогресса в специализированных доменах.
Фокус на защитников
Команда Anthropic сознательно сосредоточилась на улучшении возможностей Claude для защитных задач, избегая улучшений, которые явно отдают предпочтение наступательным операциям. Основные направления работы:
- Обнаружение уязвимостей в кодовых базах
- Создание патчей для исправления уязвимостей
- Тестирование на слабости в симулированной развернутой инфраструктуре безопасности
Это отражает важные задачи для защитников: возможность находить небезопасный код до развертывания и обнаруживать/исправлять уязвимости в уже развернутом коде.
Результаты тестирования
Для оценки эффективности использовались отраслевые стандартные тесты, включая Cybench и CyberGym.
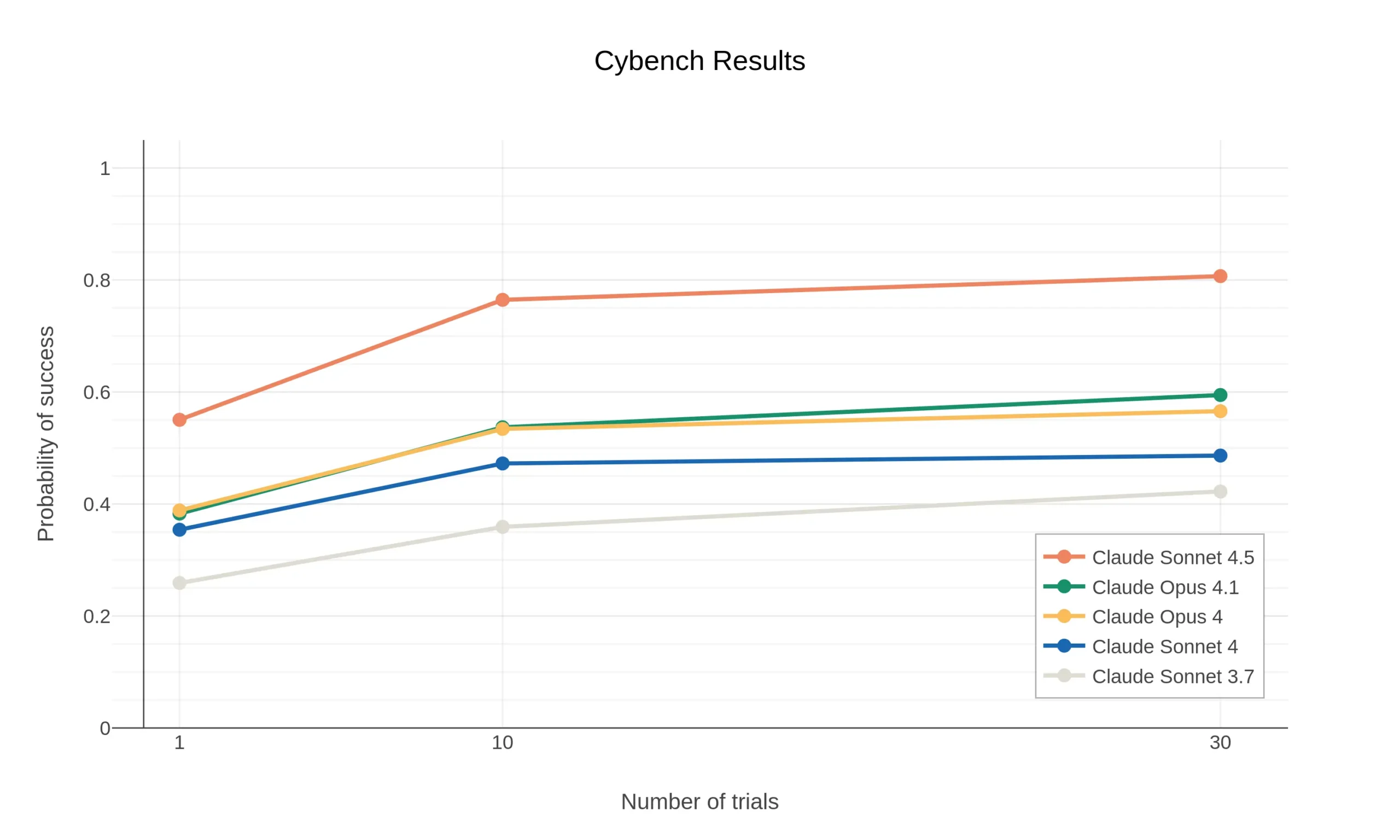
Cybench
На бенчмарке Cybench, основанном на задачах из CTF-соревнований, Claude Sonnet 4.5 показывает впечатляющее улучшение не только по сравнению с Claude Sonnet 4, но даже над моделями Claude Opus 4 и 4.1.
Наиболее поразительный результат: Sonnet 4.5 достигает более высокой вероятности успеха при одной попытке на задачу, чем Opus 4.1 при десяти попытках на задачу.
Задачи в этой оценке отражают сложные, длительные рабочие процессы. Например, одна задача включала анализ сетевого трафика, извлечение вредоносного ПО из этого трафика, декомпиляцию и дешифровку вредоносного ПО. По оценкам, это заняло бы у квалифицированного специалиста не менее часа, а возможно и дольше; Claude решил задачу за 38 минут.
При 10 попытках на оценку Cybench Claude Sonnet 4.5 успешен в 76.5% задач. Это особенно примечательно, поскольку этот показатель успеха удвоился всего за последние шесть месяцев (Sonnet 3.7, выпущенный в феврале 2025 года, имел только 35.9% успеха при 10 попытках).
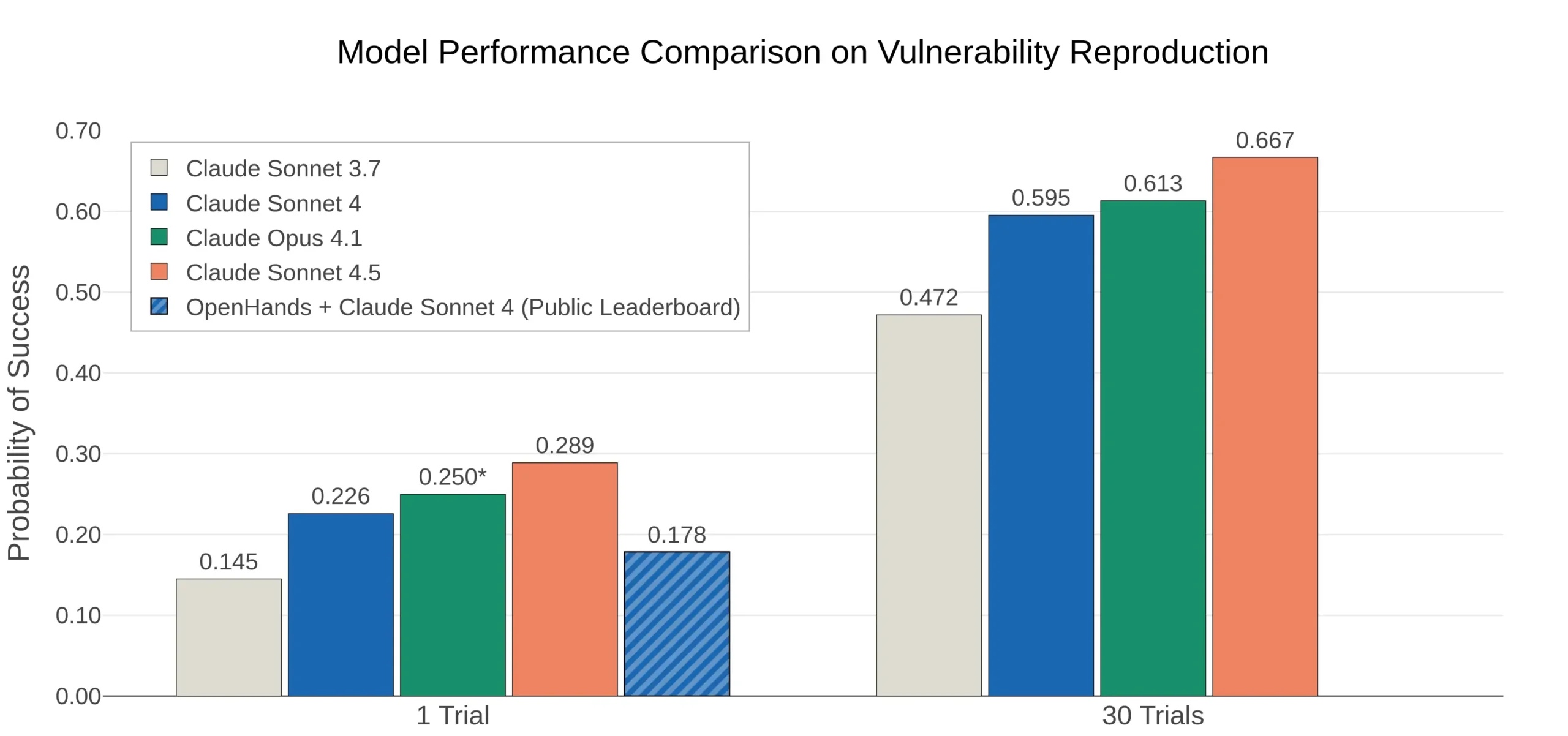
CyberGym
В другой внешней оценке Claude Sonnet 4.5 тестировался на CyberGym — бенчмарке, оценивающем способность агентов находить (ранее обнаруженные) уязвимости в реальных open-source проектах и обнаруживать новые (ранее неизвестные) уязвимости.
Команда CyberGym ранее установила, что Claude Sonnet 4 был самой сильной моделью на их публичной таблице лидеров. Claude Sonnet 4.5 показывает значительно лучшие результаты, чем либо Claude Sonnet 4, либо Claude Opus 4.





Оставить комментарий