Долгое время в научной среде считалось, что англоязычные большие языковые модели (LLM) демонстрируют наилучшее соответствие паттернам активации человеческого мозга просто в силу своей архитектуры. Однако свежее исследование, опубликованное на портале Let’s Data Science, заставляет усомниться в этой «врожденной» исключительности английского языка и пересмотреть наши взгляды на природу машинного обучения.
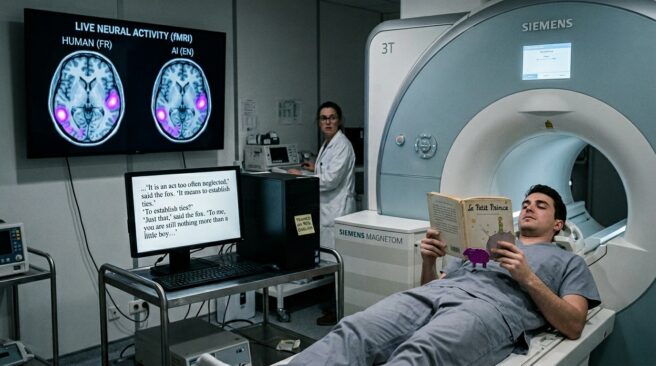
Группа исследователей под руководством Dongxin Guo проанализировала данные функциональной МРТ 112 добровольцев, читавших «Маленького принца» на английском, китайском и французском языках. Сравнивая эти показатели с внутренними репрезентациями семи различных LLM, ученые обнаружили, что ключевым фактором выравнивания (alignment) мозга и нейросети является не типология языка, а доминирующий язык в обучающей выборке модели.
Эксперимент с зеркальным результатом
Чтобы исключить влияние архитектурных различий, авторы препринта arXiv:2605.23032 провели изящный эксперимент. Они сравнили две модели с идентичной структурой: LLaMA-2-7B, обученную преимущественно на английском, и Baichuan2-7B, где приоритет отдан китайскому языку. Результат оказался симметричным: китайская модель показала наилучшее соответствие с мозгом носителей китайского языка и наихудшее — с англоязычными участниками.
Этот «разворот градиента» наглядно демонстрирует, что нейросеть подстраивается под когнитивные структуры того языка, который она видит чаще всего. Исследование также показало, что типологическая дистанция между языками влияет на деградацию выравнивания, но делает это неравномерно в разных областях мозга. Это наводит на мысли о том, насколько пластичны наши собственные языковые механизмы при столкновении с искусственными конструктами.
Исследование фиксирует корреляцию, но не объясняет, почему синтаксические зоны мозга сопротивляются выравниванию в два раза сильнее лексических. Мы научились подгонять нейросети под МРТ-снимки, манипулируя токенизацией, но так и не поняли, понимает ли модель смысл или просто виртуозно имитирует статистику нейронных разрядов. Это технологический триумф над следствием при полном игнорировании причин.
Технические нюансы и лингвистические барьеры
Особое внимание в работе уделено процессу токенизации — способу разбивки текста на фрагменты, понятные машине. Исследователи выяснили, что так называемая «плодовитость токенизатора» (tokenization fertility) объясняет примерно 60% смещения оптимального слоя кодирования при переходе от одного языка к другому. По сути, то, как мы «нарезаем» слова для модели, предопределяет, на каком уровне абстракции она будет резонировать с человеческим восприятием.
Интересно и распределение нагрузки в самом мозге:
- Области, ответственные за синтаксис (нижняя лобная извилина, IFG), показывают в 2,3 раза более крутой типологический градиент по сравнению с лексико-семантическими зонами.
- Зоны, связанные с лексикой (задняя височная доля, PTL), легче адаптируются к разным языковым моделям.
- Это подтверждает гипотезу о том, что структура предложения в ИИ и мозге расходится гораздо сильнее, чем простое понимание значений слов.
Для индустрии это означает, что погоня за универсальными мультиязычными моделями может потребовать не только расширения датасетов, но и радикального пересмотра алгоритмов токенизации. Пока же «преимущество английского языка» в ИИ выглядит скорее как побочный эффект огромных библиотек оцифрованного текста, а не как фундаментальное свойство человеческого сознания или программного кода.




Оставить комментарий