
Оглавление
Исследователи из Imperial College London и Ant Group представили фреймворк для одновременного обучения нескольких ИИ-агентов со специализированными ролями. Эта методика позволяет более надежно выполнять сложные многоэтапные задачи за счет четкого разделения обязанностей и лучшей координации.
Проблемы одиночных агентов и преимущества командного подхода
Большинство современных систем ИИ полагаются на одного агента, который должен одновременно планировать и действовать. Такой подход работает для простых задач, но терпит неудачу при длинных цепочках решений. Ошибки накапливаются, и один агент обычно не может одинаково хорошо справляться как с высокоуровневым планированием, так и с практическим использованием инструментов.
Предложенное решение — структурированная иерархия. Один агент выступает в роли проектного менеджера, который контролирует рабочий процесс, а специализированные суб-агенты обрабатывают конкретные инструменты, такие как веб-поиск или анализ данных. Исследовательская команда обнаружила, что мульти-агентные системы с четким лидером могут решать задачи почти на десять процентов быстрее, чем системы без определенных ролей.
Вертикальные иерархии работают особенно хорошо, когда главный агент делегирует задачи, а суб-агенты отчитываются о результатах. Anthropic тестирует аналогичную структуру в своем недавно представленном исследовательском агенте.
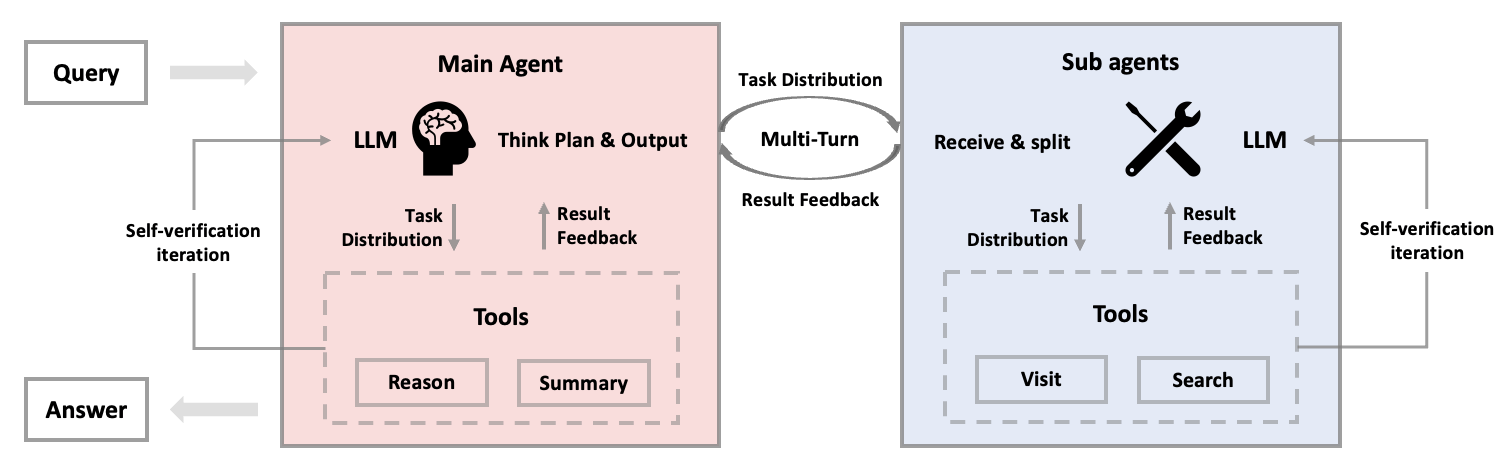
На основе пользовательского запроса главный агент разбивает работу на подзадачи, назначает их специализированным суб-агентам и интегрирует несколько раундов проверенных отзывов в окончательный ответ.
Как M-GRPO обеспечивает скоординированное обучение
Большинство систем с одним агентом сегодня используют Group Relative Policy Optimization (GRPO). Агент генерирует несколько ответов на запрос, сравнивает их и усиливает более сильные паттерны.
Мульти-агентные системы усложняют этот процесс. Агенты работают на разных частотах, обрабатывают различные задачи и могут работать на отдельных серверах. Стандартные подходы к обучению в таких условиях сталкиваются с трудностями. Многие системы заставляют всех агентов использовать одну и ту же большую языковую модель, ограничивая специализацию, хотя каждый агент работает с разными данными и обязанностями.
Исследователи выделяют три основные проблемы:
- Неравномерная рабочая нагрузка: главный агент работает непрерывно, а суб-агенты запускаются только при необходимости
- Изменчивый размер команды: в зависимости от задачи главный агент может вызвать одного или нескольких суб-агентов
- Распределенная архитектура: агенты часто работают на отдельных серверах
Новая Multi-Agent Group Relative Policy Optimization (M-GRPO) расширяет GRPO, позволяя главным и суб-агентам обучаться вместе, сохраняя при этом свои роли различными.
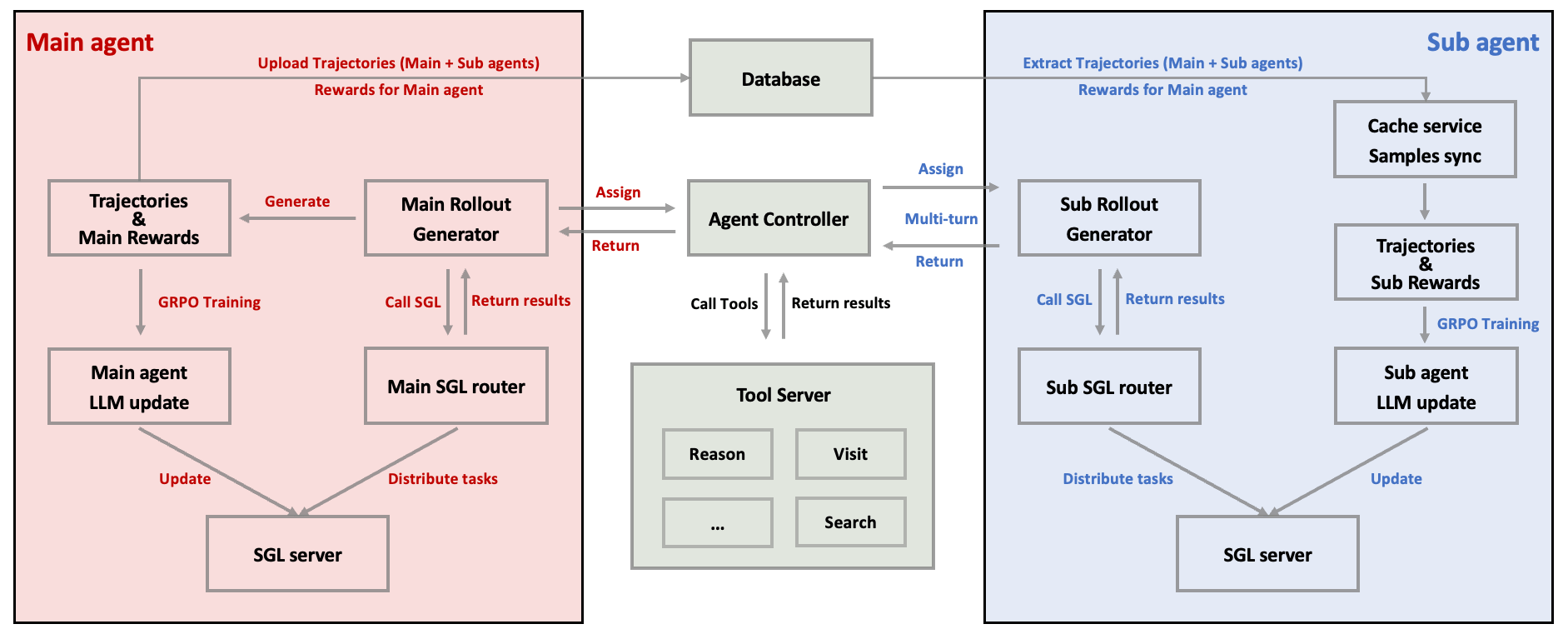
Фреймворк позволяет главным и суб-агентам обучаться независимо, синхронизируя свои результаты через общую базу данных. Центральный контроллер распределяет задачи и вызывает нужные инструменты, обеспечивая скоординированное обучение на нескольких серверах.
Каждый агент оценивается на основе своей конкретной роли. Главный агент оценивается по качеству окончательного ответа, а суб-агенты — с использованием смеси их локальной производительности и вклада в общий результат. M-GRPO вычисляет групповые относительные преимущества, сравнивая вывод каждого агента со средним значением в его группе и корректируя обучение на основе разницы.
Мы пытаемся создать сложные иерархические системы ИИ, которые имитируют человеческие команды, но при этом сталкиваемся с теми же проблемами координации, что и в реальных организациях. Главный агент становится тем самым «менеджером среднего звена», который должен одновременно планировать, делегировать и интегрировать результаты — классическая проблема управления проектами, только на скорости ИИ.
Результаты тестирования и практические примеры
Исследователи обучили свою систему M-GRPO с использованием модели Qwen3-30B на 64 GPU H800 и протестировали ее на трех бенчмарках: GAIA для задач общего ассистента, XBench-DeepSearch для использования инструментов в различных областях и WebWalkerQA для веб-навигации.
На всех бенчмарках M-GRPO превзошел как одиночных агентов GRPO, так и мульти-агентные системы с необученными суб-агентами. Он демонстрировал более стабильное поведение и требовал меньше данных для обучения для достижения высокой производительности.
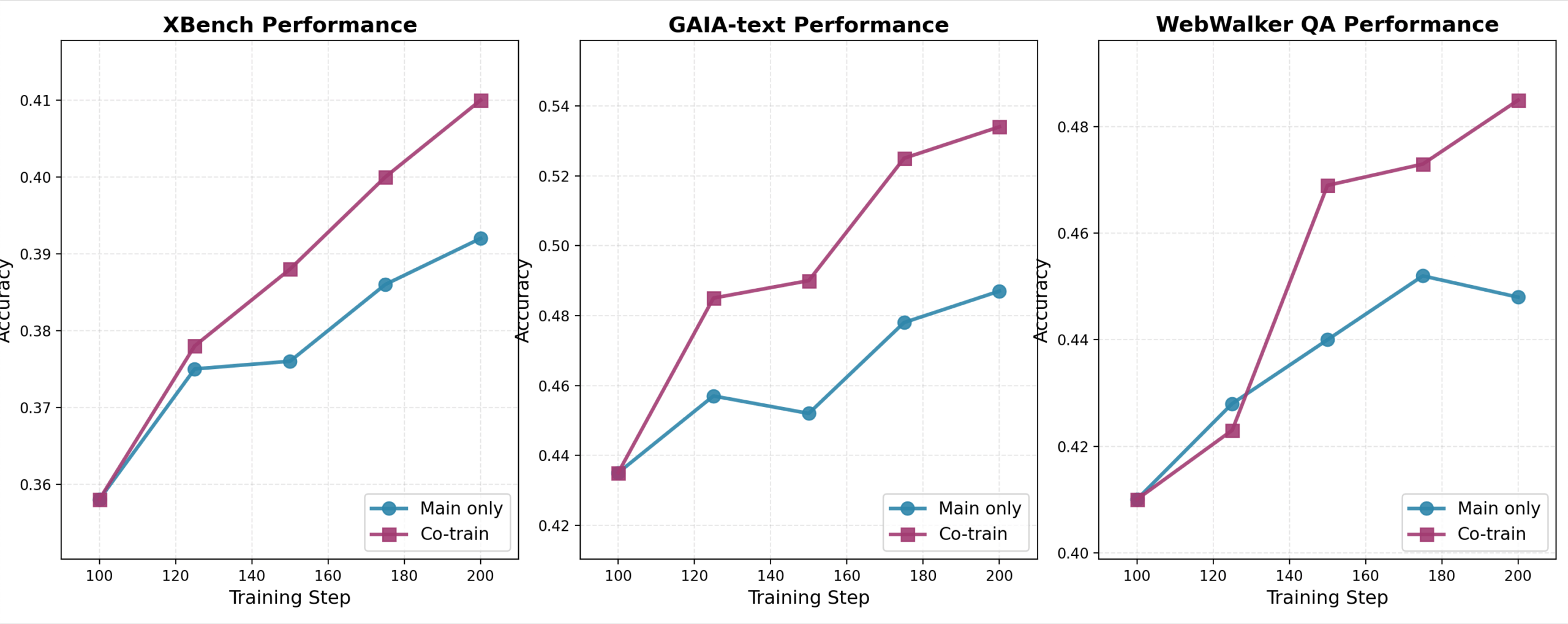
Совместное обучение главных и суб-агентов с M-GRPO последовательно превосходит обучение только главного агента на XBench, GAIA и WebWalkerQA.
Реальные примеры показывают, как это помогает. В логической задаче с кубиком Рубика обученная система выбрала правильный инструмент рассуждения для математических шагов, в то время как необученная система пыталась использовать браузер. В исследовательской задаче о инвазивных видах рыб обученный главный агент выдавал гораздо более точные инструкции. Вместо общего поиска «инвазивные виды рыбы-клоуна Ocellaris» он указал «виды, которые стали инвазивными после выпуска владельцами домашних животных».
Код и наборы данных доступны на GitHub.
По материалам The Decoder.





Оставить комментарий