
Оглавление
ИИ-агенты на основе языковых моделей (LLM) уже активно используются для автоматизации программирования и выполнения сложных задач. Однако их главная слабость — склонность к ошибкам и низкая эффективность в многоэтапных сценариях. Традиционный метод улучшения таких систем — обучение с подкреплением (reinforcement learning, RL) — требует от разработчиков глубокой переработки кода, что создает серьезный барьер для внедрения.
Исследователи из Microsoft представили решение этой проблемы — фреймворк Agent Lightning. Этот открытый инструмент позволяет добавить к существующему агенту возможности RL, практически не затрагивая его исходный код.
Как работает Agent Lightning
Ключевая идея фреймворка — отделить исполнение задач агентом от процесса обучения модели. Agent Lightning преобразует опыт агента в последовательность состояний и действий, где каждое состояние описывает текущий контекст, а каждое обращение к LLM считается отдельным действием, ведущим к новому состоянию. Это работает для любых рабочих процессов, даже самых сложных, включая сценарии с несколькими взаимодействующими агентами.
Каждый такой переход фиксирует ввод и вывод LLM, а также получаемое «вознаграждение» (reward)
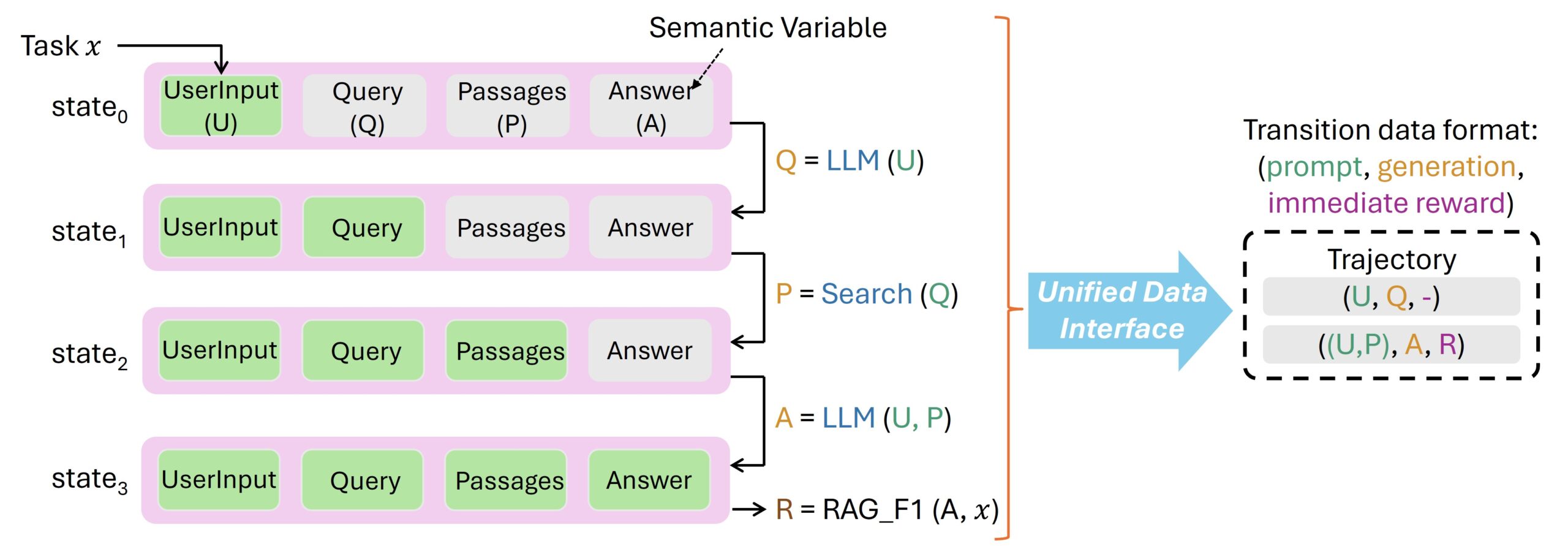
Стандартизированный формат этих данных позволяет сразу использовать их для обучения без дополнительной подготовки.
Иерархическое обучение с подкреплением
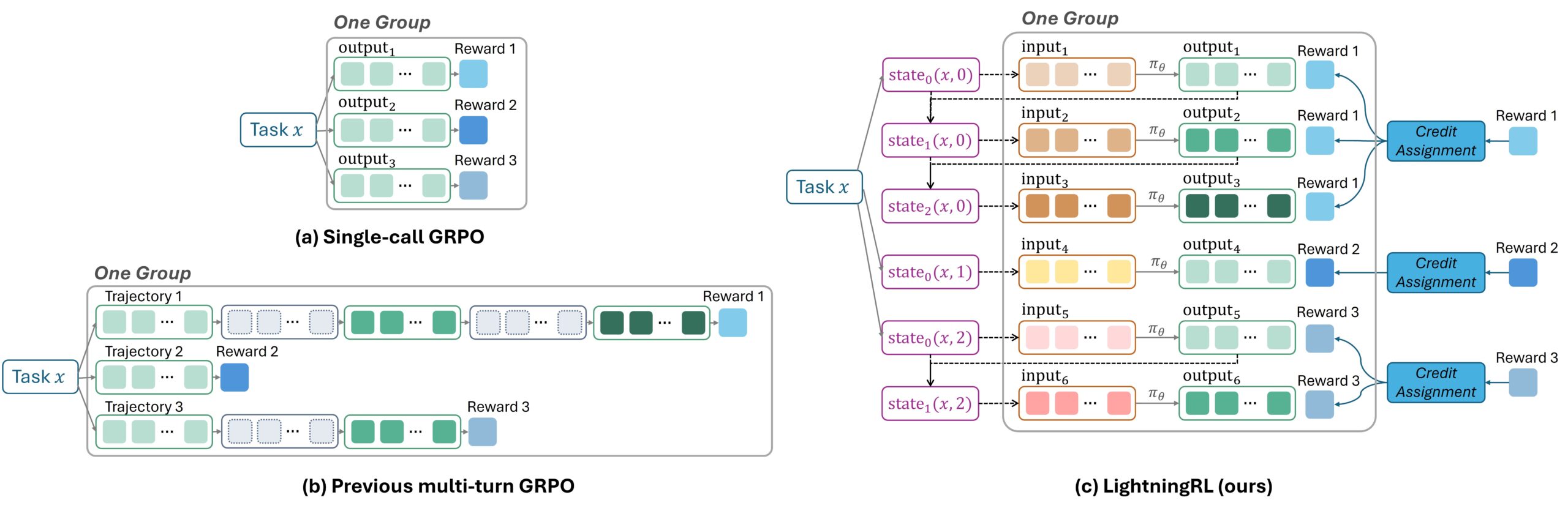
Обычный подход к RL-обучению агентов, которые делают множество запросов к LLM, заключается в объединении всего контента в одну длинную последовательность. Это сложно реализовать и может привести к деградации производительности модели.
Алгоритм LightningRL в Agent Lightning использует иерархический подход. После завершения задачи специальный модуль определяет, насколько каждое отдельное обращение к LLM повлияло на итоговый результат, и присваивает ему соответствующую оценку вознаграждения. Эти независимые шаги, теперь снабженные собственными оценками, можно использовать с любым стандартным алгоритмом одношагового RL, таким как Proximal Policy Optimization (PPO)
Это дает несколько преимуществ:
- Полная совместимость с уже существующими и широко используемыми алгоритмами RL.
- Поддержка сложных поведений, таких как использование нескольких инструментов или работа с другими агентами.
- Короткие последовательности обеспечивают эффективное и масштабируемое обучение.
Архитектура: агенты, алгоритмы и хранилище
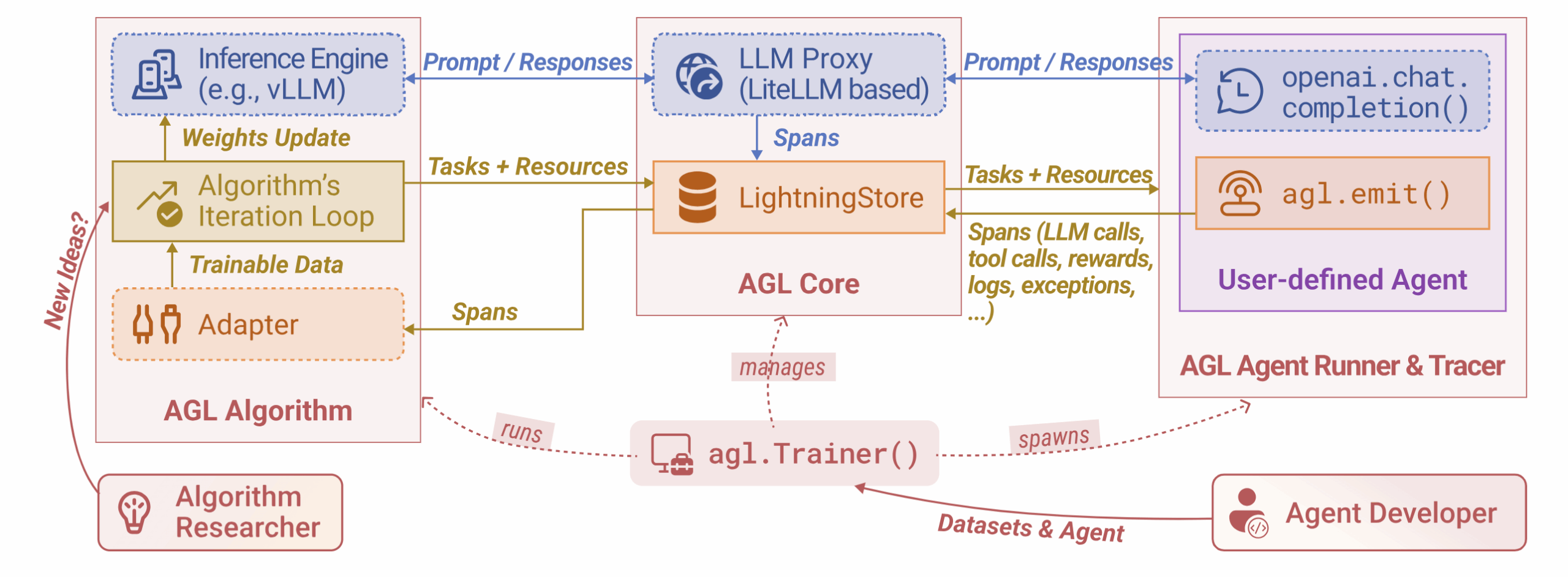
Agent Lightning выступает в роли промежуточного слоя (middleware) между алгоритмами RL и окружением агентов. Его архитектура состоит из трех основных компонентов:
Agent Runner: управляет выполнением задач агентами, распределяет работу и собирает результаты. Он работает отдельно от самих LLM, что позволяет запускать их на разных ресурсах и масштабировать систему для поддержки множества параллельных агентов.
Algorithm: отвечает за обучение моделей и размещение LLM, используемых для вывода и обучения. Этот компонент управляет всем циклом RL: распределяет задачи, контролирует их выполнение и обновляет модели на основе полученного опыта. Обычно работает на GPU.
LightningStore: центральное хранилище данных в системе. LightningStore предоставляет стандартизированные интерфейсы и общий формат данных, обеспечивая взаимодействие между всеми компонентами
Весь цикл RL состоит из двух шагов: сначала Agent Lightning собирает данные выполнения агентов (так называемые «спаны») и сохраняет их в хранилище; затем извлекает необходимые данные и отправляет их алгоритму для обучения
Главные преимущества такой декомпозиции:
- Алгоритмическая гибкость: разработчики могут легко настраивать процесс обучения, определяя разные схемы вознаграждений или экспериментируя с подходами.
- Эффективность ресурсов: каждый компонент может работать на оптимальном для него оборудовании (например, агенты на CPU, а обучение на GPU) и масштабироваться независимо.
Идея, лежащая в основе Agent Lightning, проста и элегантна: не трогать работающий код, а обернуть его в универсальный слой для сбора данных и обучения. Это классический инженерный подход к сложной проблеме — вместо того чтобы перекраивать систему под новый метод, создать для нее адаптер. В эпоху, когда каждый день появляются новые фреймворки для агентов, такая совместимость и минимальное вмешательство — огромное преимущество. Вопрос лишь в том, насколько качественно LightningRL сможет распределять «заслуги» между шагами в длинных цепочках рассуждений — именно здесь будет проверяться реальная эффективность подхода.
По материалам Microsoft Research.





Оставить комментарий