
Оглавление
Эра ИИ как простых чат-ботов завершилась — наступило время автоматизации сложных рабочих процессов от начала до конца. Особенно это касается data science, где традиционно требовалось человеческое вмешательство. Новое исследование демонстрирует, насколько современные агенты на основе больших языковых моделей могут справляться с реальными инженерными задачами.
Испытание для ИИ: от классификации изображений до прогнозирования вулканов
Исследователи протестировали систему AutoMind на платформе MLE-Bench, которая специально разработана для оценки способностей ИИ-агентов выполнять реальные инженерные задачи — кодирование, отладку и анализ данных. В отличие от синтетических тестов, этот бенчмарк проверяет способность моделей рассуждать и выполнять действия в сложных рабочих процессах.
Задача для агентов обработки данных кажется простой: на входе — сырой набор данных, на выходе — качественная модель и файл для отправки. На практике же требуется обработка данных, проектирование функций, оценка и форматирование результатов в условиях ограниченных ресурсов и времени.
AutoMind: адаптивный агент для автоматической обработки
AutoMind представляет собой систему агентов data science с расширенными знаниями, которая улучшает возможности больших языковых моделей за счет интеграции базы экспертных знаний, поиска по дереву и адаптивных стратегий кодирования.
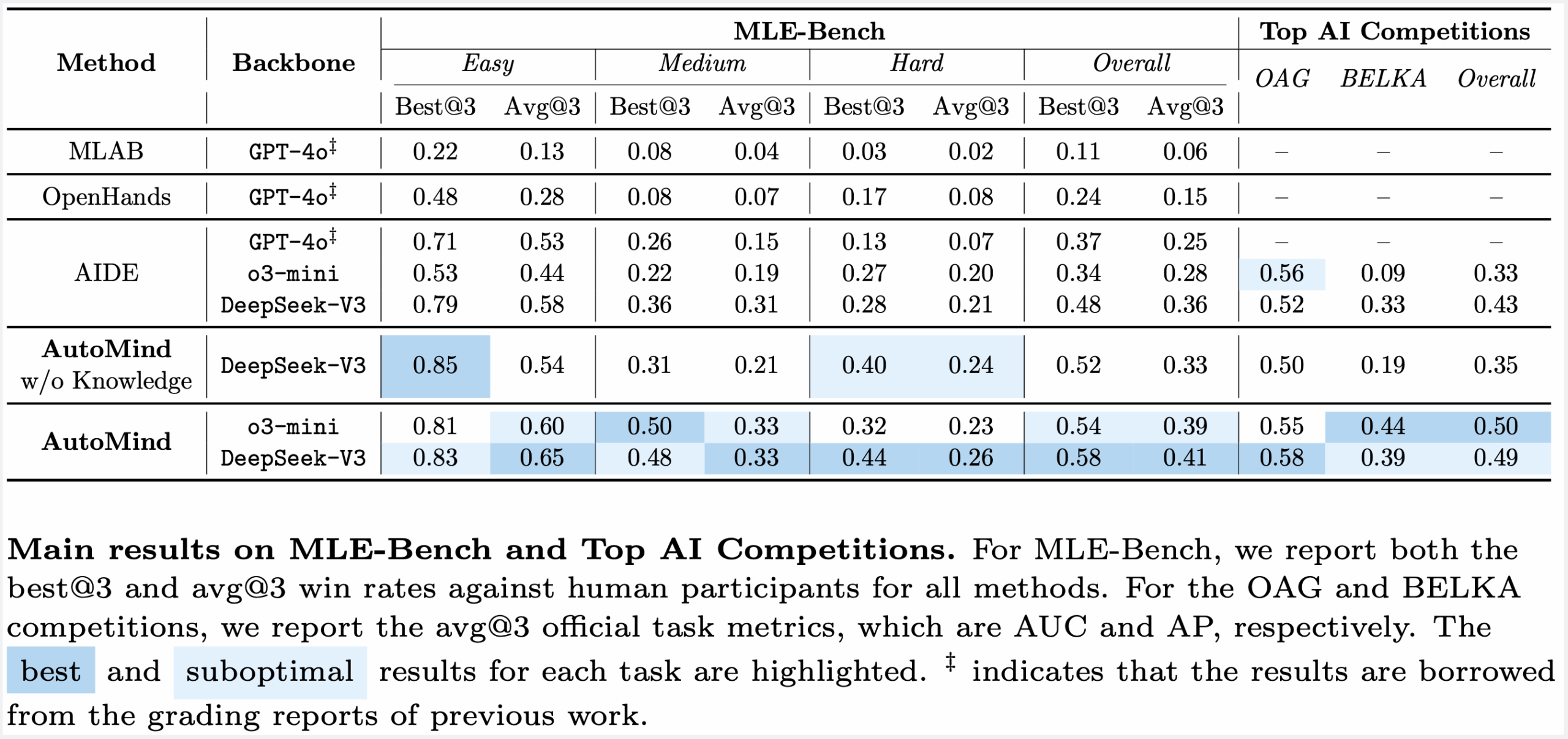
Эксперименты проводились на подмножестве AutoMind Lite, включающем 15 задач разной сложности — от простой классификации текста до сложной сегментации изображений. Все запуски выполнялись на GPU Tesla V100 32 GB.
Результаты: где ИИ преуспел, а где отстал
В качестве базовой модели использовался DeepSeek V3. Вместо грубых метрик вроде «медалей» исследователи применяли Beat Ratio — долю участников, которых превзошел ИИ-агент.
Из-за высокой вариативности результатов каждый тест запускался трижды, и в отчет попали лучшие показатели:
- 100% Beat Ratio в задачах прогнозирования извержений вулканов и очистки документов
- 95% Beat Ratio в задаче Google Quest Challenge
- 81% Beat Ratio в классификации птиц по аудио
- Слабые результаты (<20%) в распознавании речи и прогнозировании давления вентилятора
Результаты впечатляют, но не обманывайтесь — ИИ-агенты все еще остаются дорогими игрушками. 48 GPU-дней вычислений и 212 ГБ данных для решения 15 задач — это не масштабируемое решение для большинства компаний. Хотя в некоторых задачах агенты показали выдающиеся результаты, их надежность оставляет желать лучшего: тот же промпт может дать от 0.29 до 1.00 Beat Ratio. Пока это инструмент для исследований, а не для работы.
Что это значит для будущего автоматизации
Эксперименты показывают, что ИИ-агенты уже способны справляться с нетривиальными задачами data science, но их внедрение в реальные рабочие процессы требует решения проблем надежности, стоимости и предсказуемости результатов. Особенно сложными оказались задачи, требующие тонкого понимания контекста и работы с шумными данными.
Полные данные экспериментов, включая логи, решения и промежуточные результаты, доступны в runtime-пакете объемом 212 ГБ. По материалам Hugging Face.





Оставить комментарий