
Команда платформы искусственного интеллекта Salesforce нашла способ значительно сократить операционные издержки при развертывании кастомизированных больших языковых моделей. Вместо месяцев оптимизации серверных конфигураций и резервирования GPU-мощностей компания перешла на использование Amazon Bedrock Custom Model Import, что позволило сосредоточиться на моделях и бизнес-логике вместо управления инфраструктурой.
Стратегия интеграции
Переход от Amazon SageMaker Inference к Amazon Bedrock Custom Model Import потребовал тщательной интеграции с существующими MLOps-процессами Salesforce без нарушения рабочих нагрузок. Основной целью было сохранение текущих API-эндпоинтов и интерфейсов обслуживания моделей при нулевом простое и без изменений в приложениях.
Как показано на диаграмме потока развертывания, Salesforce дополнили существующий конвейер доставки моделей всего одним дополнительным шагом для использования Amazon Bedrock Custom Model Import. После сохранения артефактов модели в хранилище моделей (бакет Amazon S3), система вызывает API Amazon Bedrock Custom Model Import для регистрации модели. Эта операция занимает всего 5–7 минут в зависимости от размера модели, при этом общий процесс выпуска модели остается на уровне примерно 1 часа.
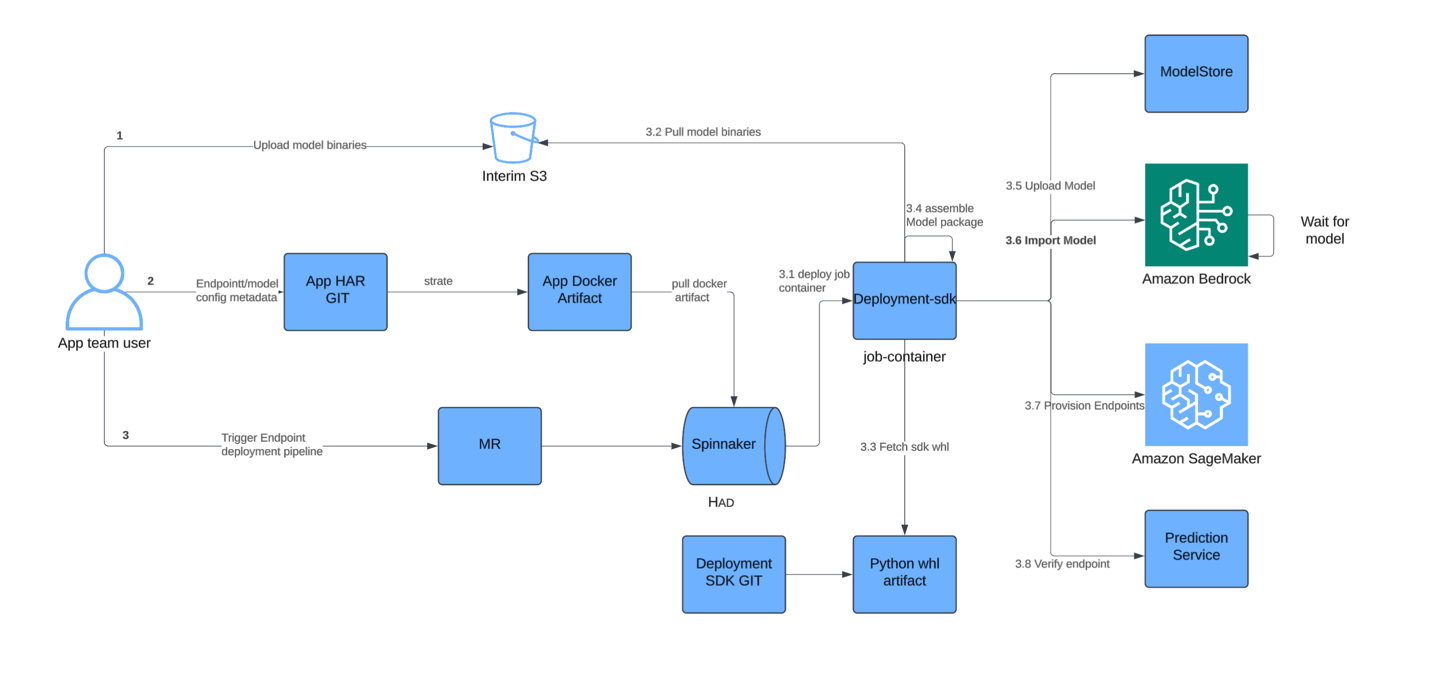
Основные изменения конфигурации включали предоставление Amazon Bedrock разрешений на кросс-аккаунтный доступ к S3-бакету с моделями и обновление политик IAM для разрешения клиентам вызовов эндпоинтов Amazon Bedrock.
Гибридная архитектура
На диаграмме потока логического вывода показано, как Salesforce сохранили существующие интерфейсы приложений, используя серверные возможности Amazon Bedrock. Запросы клиентов проходят через устоявшийся слой предварительной обработки для бизнес-логики перед достижением Amazon Bedrock, с применением постобработки к сырому выводу модели.
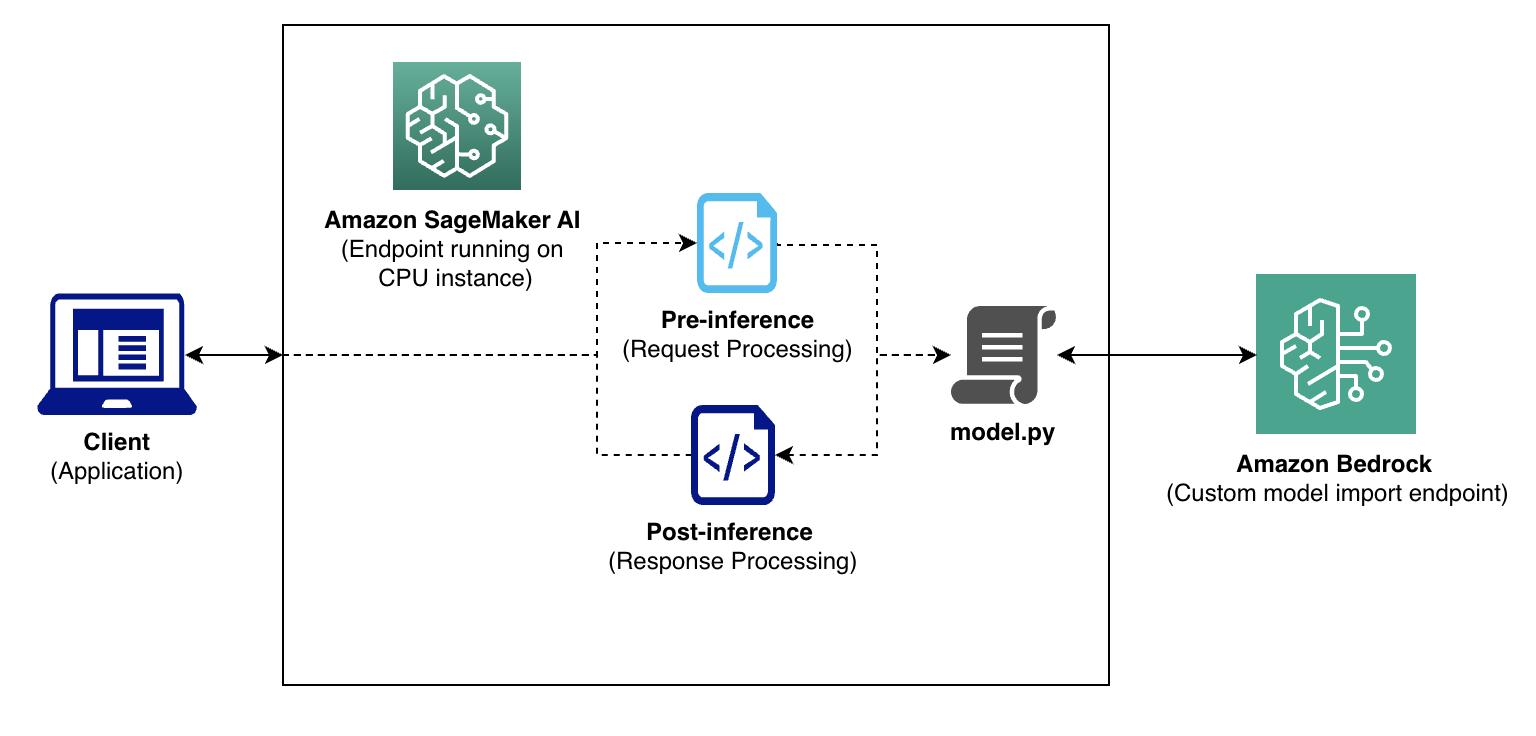
Для обработки сложных требований компания развернула легковесные SageMaker CPU-контейнеры, которые действуют как интеллектуальные прокси — выполняют пользовательскую логику model.py, перенаправляя фактический вывод на эндпоинты Amazon Bedrock. Этот подход обеспечивает обратную совместимость с существующими интеграциями при сохранении GPU-интенсивного вывода полностью серверным через Amazon Bedrock.
Переход на серверные LLM — это не просто техническое улучшение, а стратегический сдвиг в подходе к ML-инфраструктуре. Вместо того чтобы тратить месяцы на тонкую настройку серверных конфигураций и резервировать дорогостоящие GPU-ресурсы «на пик», компании получают возможность мгновенного масштабирования с оплатой только за фактическое использование. Особенно впечатляет гибридный подход Salesforce — они не стали ломать работающую систему, а элегантно интегрировали Bedrock в существующий пайплайн, сохранив инвестиции в мониторинг и логику предобработки. Это урок для всех, кто боится миграции на серверные решения из-за «потери контроля».
Тестирование масштабируемости
Для проверки производительных возможностей Amazon Bedrock Custom Model Import Salesforce провели всестороннее нагрузочное тестирование в различных сценариях параллелизма. Их методология тестирования сосредоточилась на измерении того, как прозрачное автоскейлинг Amazon Bedrock — когда сервис автоматически запускает копии моделей по требованию и масштабируется при высокой нагрузке — повлияет на реальную производительность.
Источник новости: AWS Machine Learning Blog





Оставить комментарий