
По сообщению Scale, крупные компании столкнулись с фундаментальной проблемой при использовании языковых моделей для оценки AI-агентов: результаты оценок оказываются неповторимыми во времени.
Системная проблема индустрии
Внутренние эксперименты Scale показали, что идентичные тесты могут давать расхождения в метриках до 10-15% от одного дня к другому. Такой уровень нестабильности делает невозможным доверие к результатам A/B тестирования.
Проблема затрагивает все основные модели на рынке:
- OpenAI (GPT-4 варианты): ±10–12%
- Anthropic (Claude варианты): ±8–11%
- Google (Gemini варианты): ±9–14%
Маржа ошибки в оценках достаточно велика, чтобы инвалидировать любой A/B тест. Для достижения 50% улучшения производительности агента команде может потребоваться сделать десять небольших изменений, каждое из которых должно давать ~5% прирост. Однако A/B тест не может надежно обнаружить сигнал в 5%, когда дневной шум инструмента измерения составляет 10-15%.
Технические причины нестабильности
Провайдеры API постоянно меняют компоненты моделей, но более глубокая техническая причина связана с архитектурой современных LLM и включает два ключевых концепта:
- Sparse Mixture of Experts (MoE): модели состоят из множества меньших специализированных «экспертных» подсетей, и для каждого входа запрос динамически маршрутизируется только через часть этих подсетей
- Пакетная обработка (batched inference): провайдеры обрабатывают множество пользовательских запросов одновременно в «пакете»
При сочетании этих техник результаты становятся непредсказуемыми, поскольку состав пакета может определять, к какому эксперту будет направлен ваш запрос.
Решение: когорта судей
Вместо зависимости от одного «шумного» судьи, Scale использует панель из трех LLM, которую они называют «когортой судей». Каждый судья получает немного отличающийся промпт для той же задачи, но семантически идентичный. Агрегируя выходы от этой когорты, им удается сгладить провайдерскую вариативность и получить стабильную, повторяемую метрику оценки.
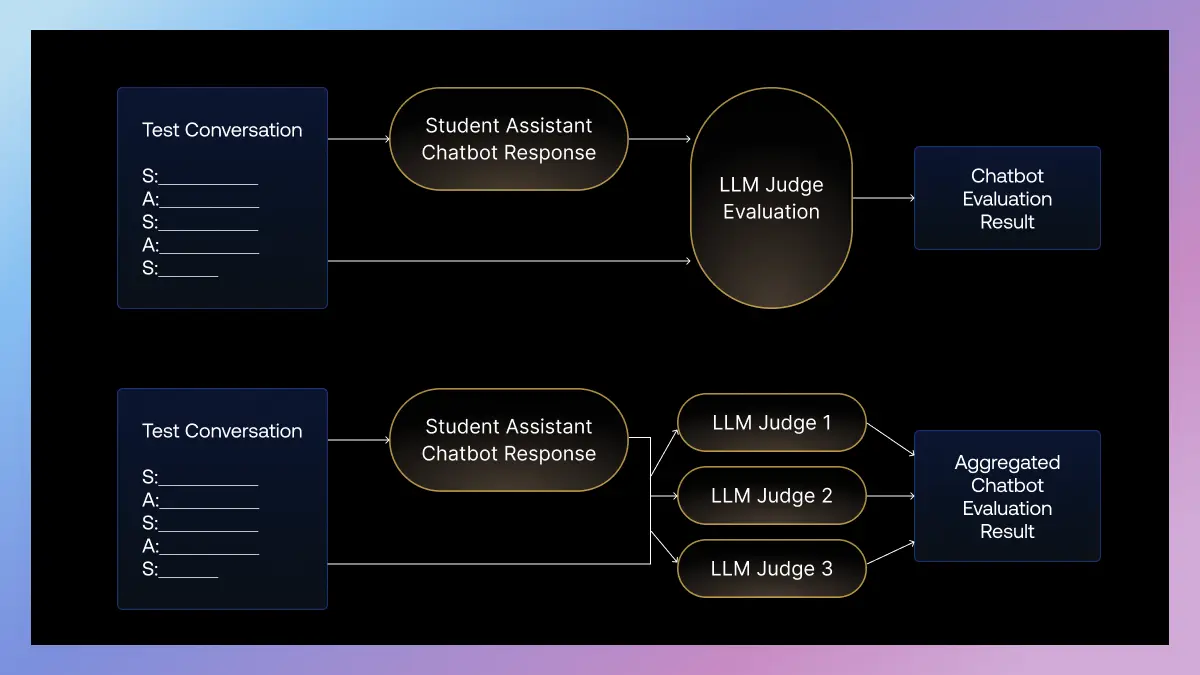
С этим методом вариативность в результатах оценок была снижена как минимум на 50% по различным измеряемым параметрам. Это позволяет отличать реальные изменения производительности от статистического шума.
Проблема вариативности LLM-оценок — это не баг, а фича архитектуры современных моделей. MoE и пакетная обработка создают фундаментальную неопределенность, которую невозможно устранить на уровне отдельного запроса. Решение Scale с когортой судей — элегантный статистический обходной путь, но он лишь маскирует системную проблему. Реальный прорыв произойдет, когда провайдеры начнут предлагать детерминированные версии моделей для корпоративных нужд — даже если это будет стоить дороже и работать медленнее.
Базовые модели, на которых мы строим, не так фундаментально стабильны, как можно было бы представить. Эта вариативность является структурной, общеотраслевой проблемой, которая может вносить неопределенность в процесс оценки, создавая риски для разработки продуктов и планирования дорожных карт. Применяя подход когорты судей, организации могут производить более надежные, повторяемые измерения, необходимые для принятия решений.





Оставить комментарий