Хрупкий фасад мышления
Учёные из Аризонского университета подвергли сомнению способность больших языковых моделей к подлинному логическому мышлению. Их исследование показывает, что техника цепочки рассуждений (chain-of-thought, CoT) — всего лишь «хрупкий мираж», работающий только на знакомых данных и рассыпающийся при малейших отклонениях. Это бросает вызов популярному нарративу о развитии ИИ-систем, масштабирующих мышление через увеличение вычислительных мощностей.
Эксперимент в контролируемой среде
Команда создала DataAlchemy — стерильную среду для тестирования рассуждений. Модели обучали простым операциям вроде ROT-преобразований букв (например, сдвиг на 13 позиций: A→N) или ротации слов (APPLE→EAPPL). После обучения их тестировали с:
- Незнакомыми правилами преобразований
- Изменённой длиной слов
- Добавлением шумовых токенов
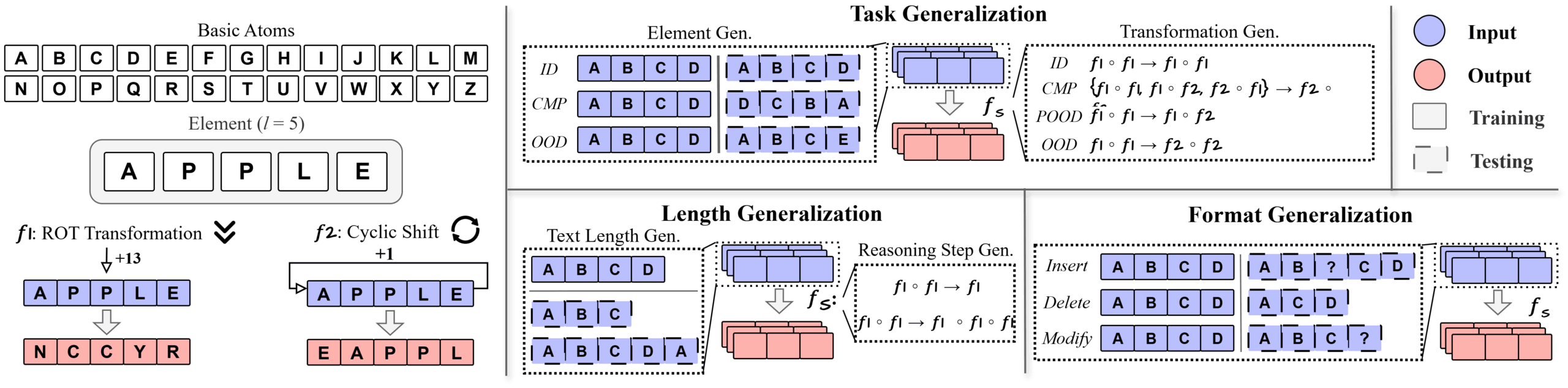
Результаты показали катастрофическое падение точности. Модели механически воспроизводили заученные шаблоны: при изменении длины слова искусственно добавляли/удаляли символы, а при появлении шумовых токенов теряли логическую цепочку. Как отмечают авторы: «LLM — не принципиальные мыслители, а сложные симуляторы рассуждающего текста».
Ирония в том, что индустрия уже вовсю продаёт «логические» способности LLM для меддиагностики и финансового анализа, хотя фундаментально они остаются статкорреляторами. Главный риск — «беглость бреда»: модели уверенно генерируют убедительные, но внутренне противоречивые выводы, как в примере с Gemini, который корректно определил 1776 как високосный год, но в следующем предложении назвал его обычным. Ключевой урок: если вы проектируете критичные системы, CoT-выводы требуют такой же верификации, как код стажёра.
Эхо сомнений в научном сообществе
Работа перекликается с другими исследованиями:
- Исследование Apple «The Illusion of Thinking» о поверхностном распознавании паттернов вместо структурного понимания
- Работа Tsinghua/SJTU, где RLVR-обучение улучшало точность, но не создавало новых стратегий решения
- Эксперименты NYU, выявившие «недостаточное мышление» при росте сложности задач
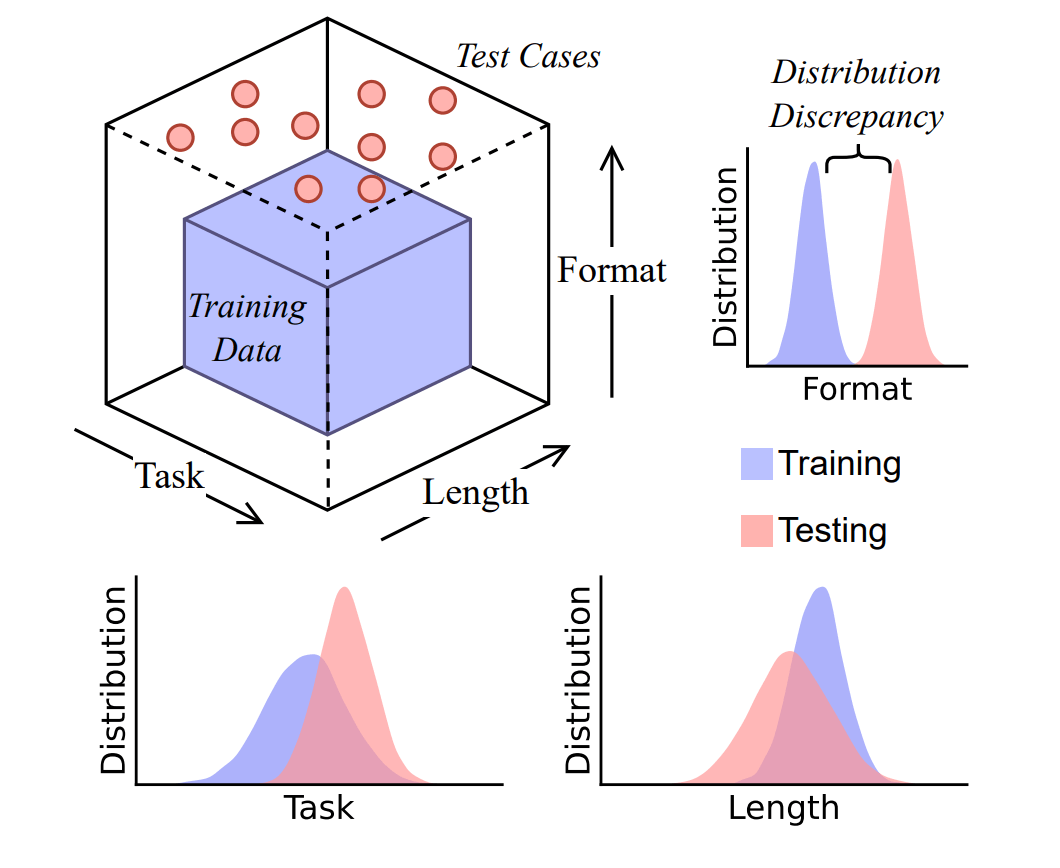
Ведущий автор Чэншуай Чжао опубликовал материалы на X и Hugging Face. Вопрос о природе «рассуждений» LLM остаётся открытым, но ясно одно: замена человеческого суждения выводом модели в ответственных сценариях — русская рулетка с тренировочными данными вместо патронов.





Оставить комментарий