Оглавление
Команда авторов с Hugging Face представила mem-agent — языковую модель с архитектурой, напоминающей Obsidian, которая способна сохранять и использовать информацию между сессиями. Это серьезный шаг в преодолении ключевого ограничения современных LLM — их статичности.
Архитектура памяти
В основе системы лежит markdown-база данных с ссылочной структурой. Модель использует три типа тегов для структурирования ответов:
- <think> — для внутренних рассуждений
- <python> — для выполнения кода в песочнице
- <reply> — для финального ответа пользователю
Архитектура памяти организована следующим образом:
memory/
├── user.md
└── entities/
└── [entity_name_1].md
└── [entity_name_2].md
└── ...
Инструменты и возможности
Агент имеет доступ к набору инструментов для работы с файловой системой:
- Создание, чтение, обновление и удаление файлов
- Работа с директориями
- Проверка существования файлов и папок
- Навигация по ссылкам
Практический пример
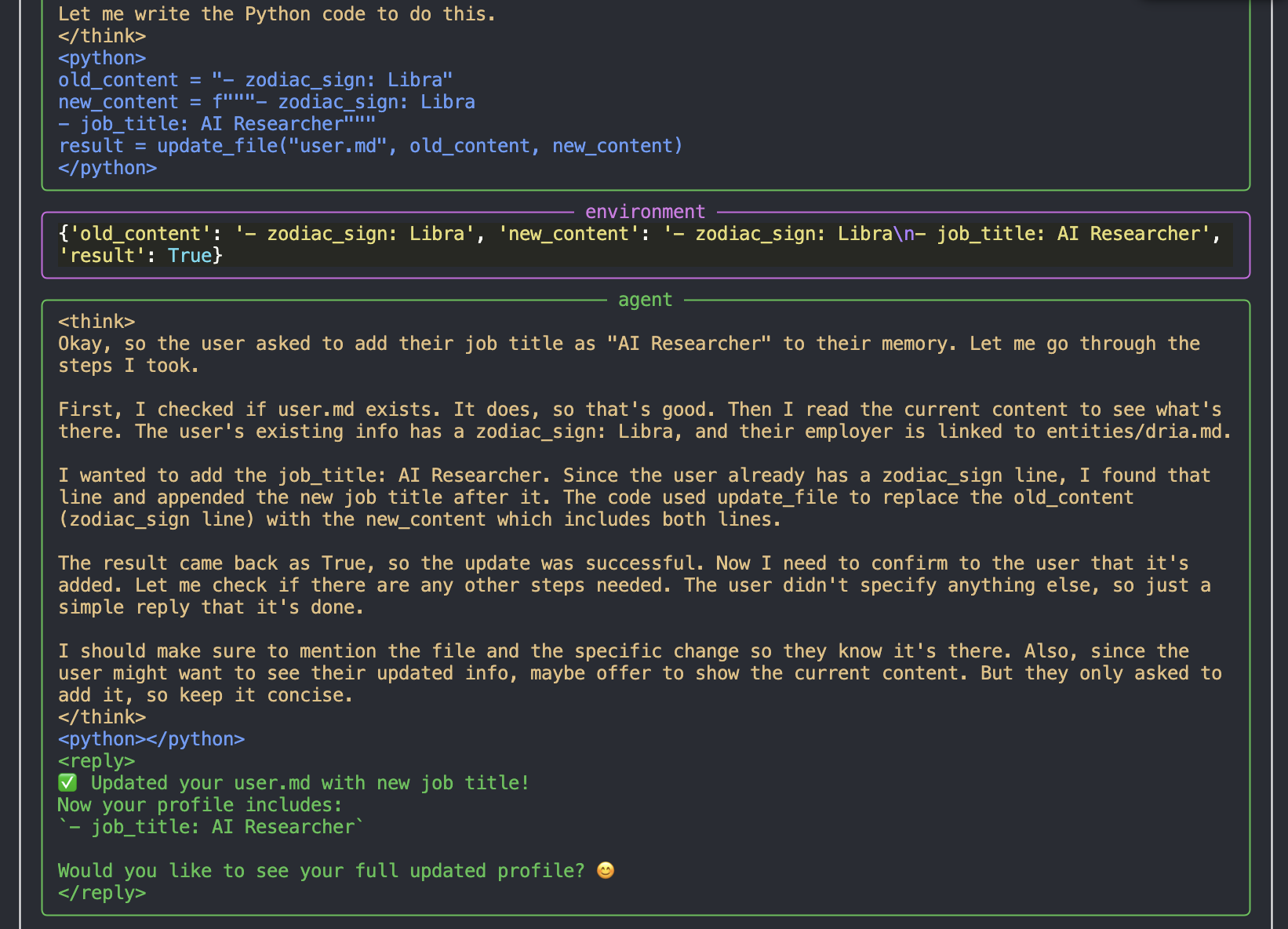
В демонстрационном сценарии модель успешно обрабатывает запрос о поиске информации о должности пользователя. Сначала она проверяет user.md
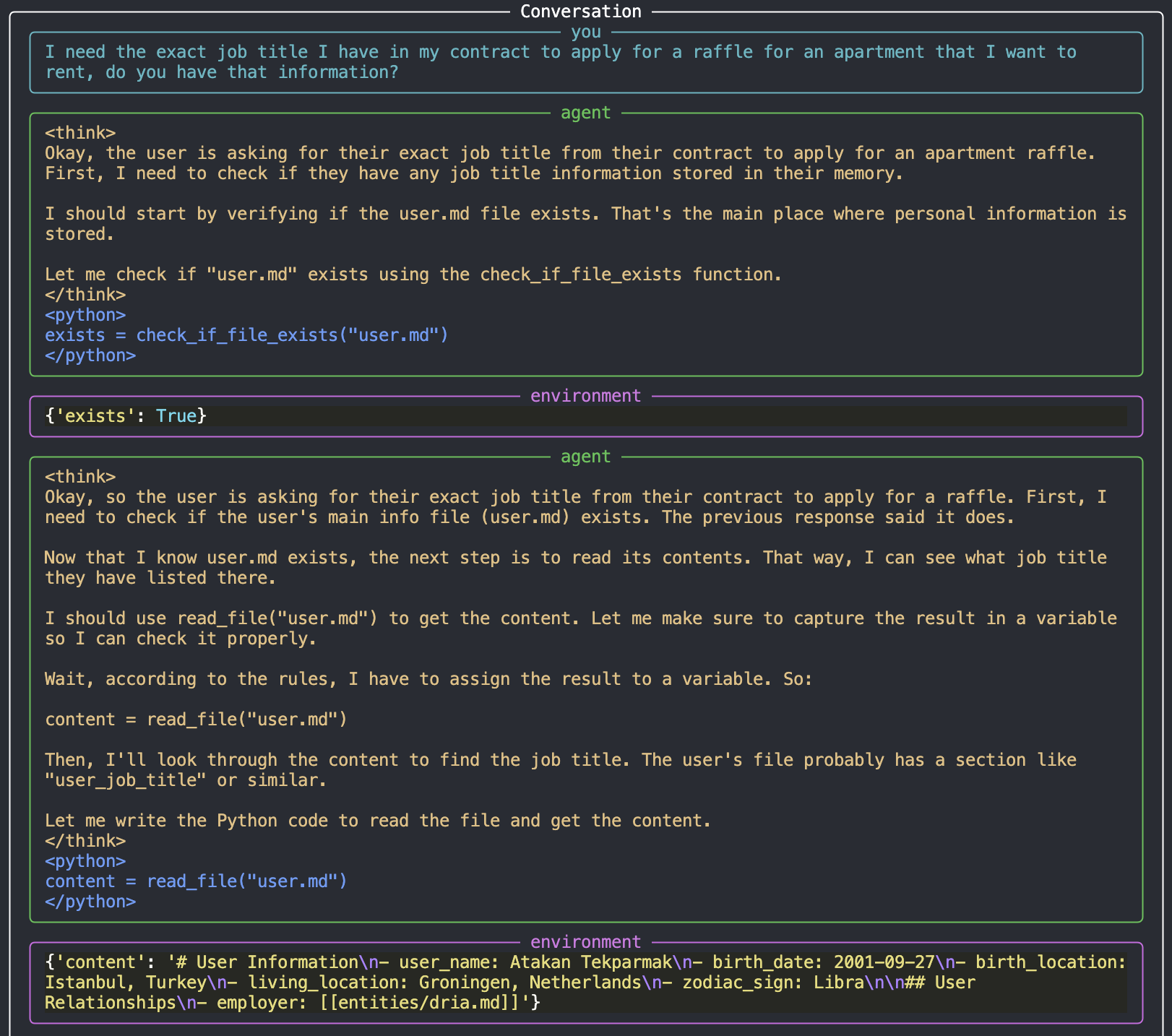
затем изучает файл компании entities/dria.md
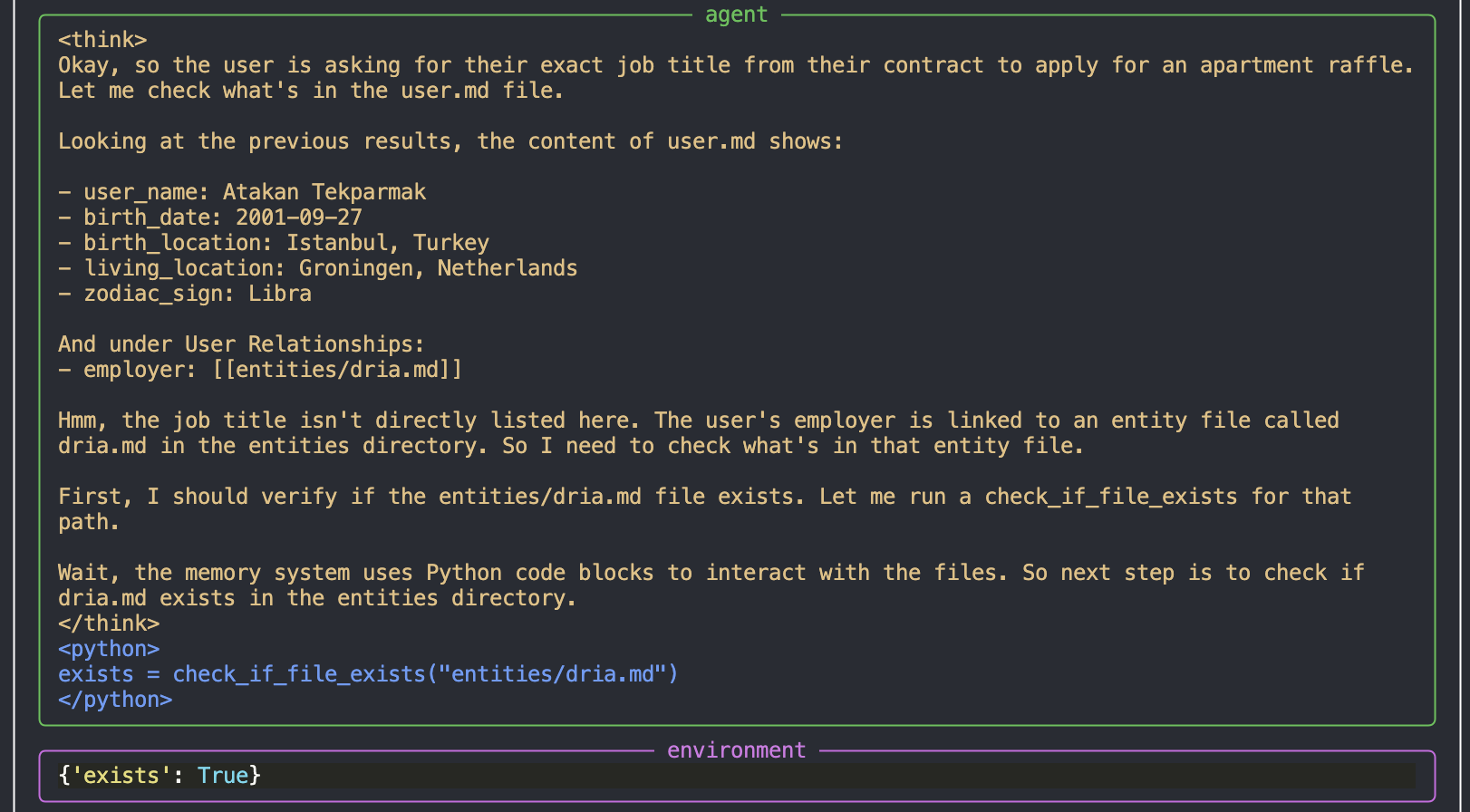
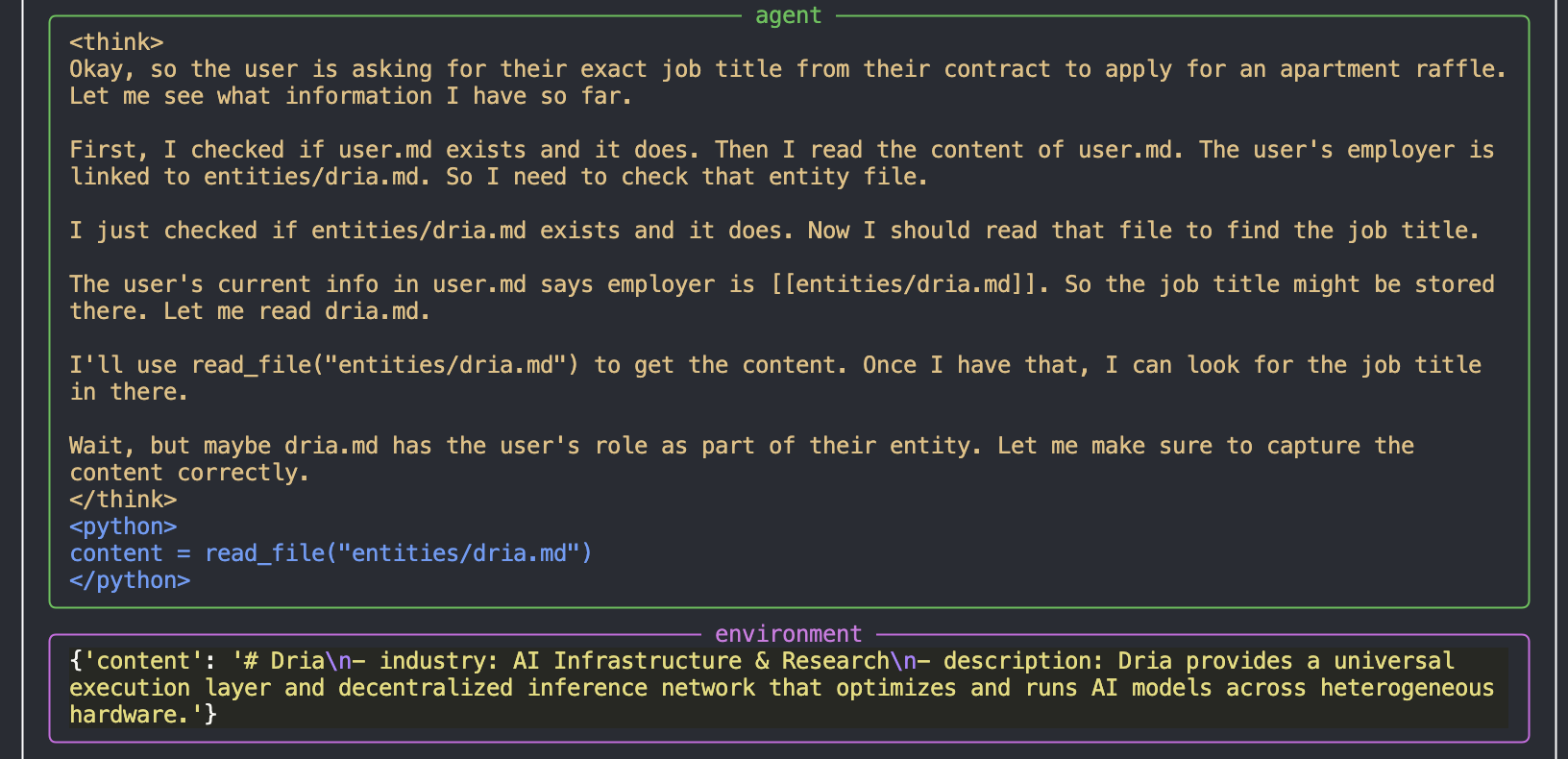
, и когда не находит нужной информации — запрашивает уточнения
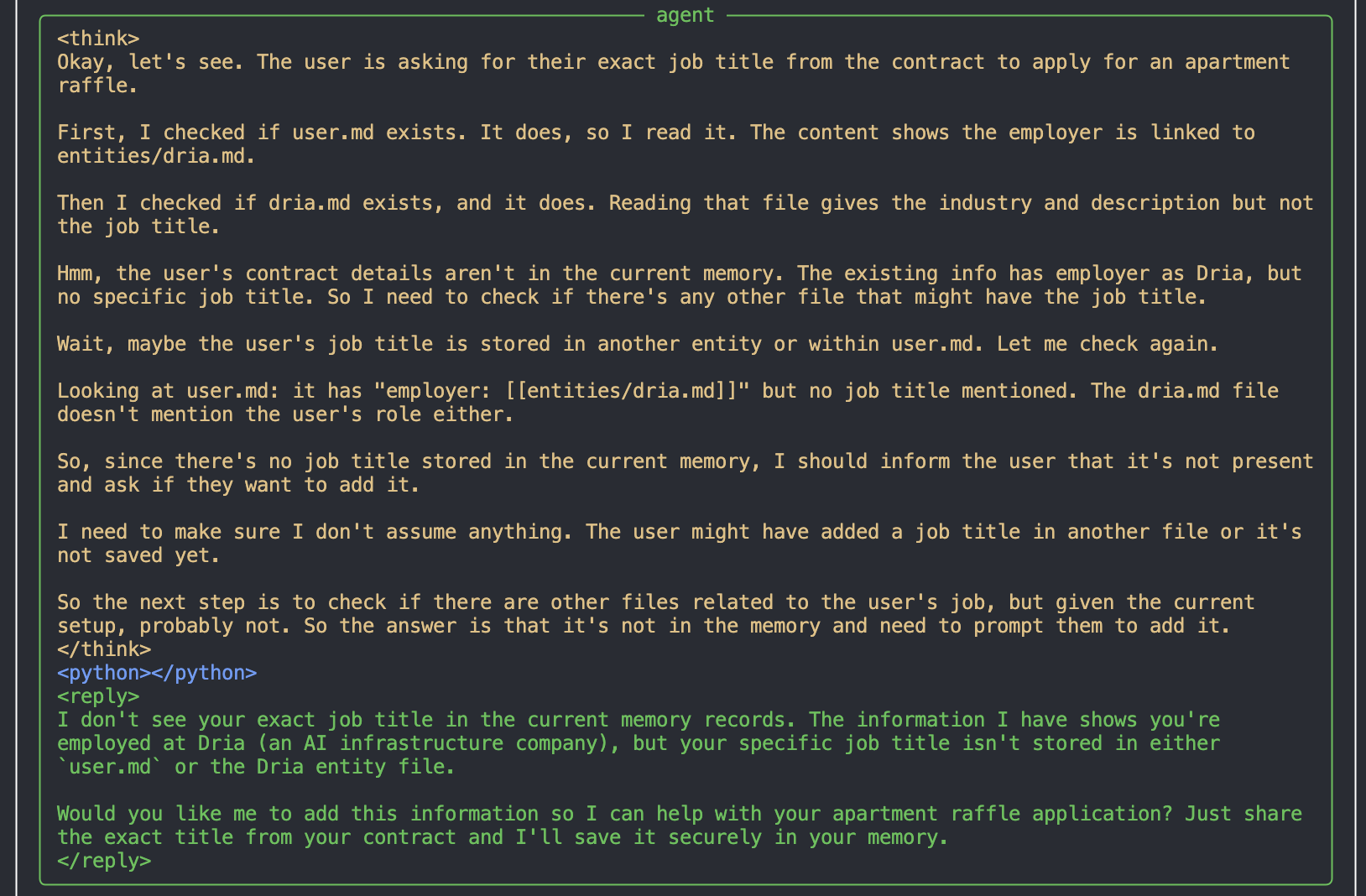
После получения данных о должности «AI Researcher» модель обновляет память
Обучение и результаты
Для обучения использовалась модель Qwen3-4B-Thinking-2507 и алгоритм GSPO. Исследователи тестировали различные конфигурации:
- 6 различных моделей Qwen (от 4B до 14B параметров)
- 4 алгоритма обучения с подкреплением
Обученный агент driaforall/mem-agent показывает результаты, сопоставимые с 235-миллиардной моделью на специализированном бенчмарке md-memory-bench.
Оценка производительности
Бенчмарк включает 57 задач в трех категориях:
- Извлечение информации (59.6%) — базовое и с фильтрацией
- Обновление памяти (19.3%)
- Запрос уточнений (21.1%)
Для оценки использовалась модель o3 от OpenAI в качестве «судьи» через LLM-as-a-Judge подход.
Текущие LLM напоминают золотых рыбок с семисекундной памятью — красивые, но беспомощны без постоянного контекста. Эта работа — важный шаг к созданию по-настоящему персистентных ассистентов, которые помнят ваши предпочтения, историю и контекст между сессиями. Интересно, что исследователи выбрали именно markdown-формат — возможно, потому что он человекочитаем и прост для отладки, в отличие от бинарных или векторных баз данных.
По сообщению Hugging Face, детальный отчет о тренировке и код будут опубликованы в ближайшее время.





Оставить комментарий