Оглавление
Hugging Face пишет, что их команда разработала Jupyter Agent — систему, которая позволяет языковым моделям выполнять код непосредственно в среде Jupyter Notebook для решения задач анализа данных. Это следующий шаг в эволюции ИИ-ассистентов для анализа данных.
Бенчмарк для реалистичной оценки
Для измерения прогресса в создании агентов для анализа данных исследователи использовали бенчмарк DABStep, разработанный совместно с Adyen. Этот бенчмарк проверяет способности моделей отвечать на нетривиальные вопросы по реальным наборам данных. Даже лучшие модели типа Claude 4 Sonnet показывают менее 20% точности на сложных задачах.
Оптимизация каркаса для малых моделей
Исследователи начали с модели Qwen3-4B-Thinking-2507 — достаточно компактной для быстрых итераций, но способной к агентному поведению. Первые результаты были скромными: 44.4% на легких и всего 2.1% на сложных задачах.
Ключевым прорывом стало упрощение каркаса — фреймворка, который управляет поведением агента. Команда сократила код до ~200 строк без внешних зависимостей, вдохновляясь подходом tiny-agents.
Упрощение каркаса — это тот редкий случай, когда меньше действительно значит больше. Вместо перегруженных фреймворков с десятками инструментов, минималистичный подход с двумя ключевыми функциями (выполнение кода и окончательный ответ) дал скачок производительности на 15%. Ирония в том, что мы потратили годы на усложнение архитектур, а решение оказалось в обратном направлении.
Конвейер подготовки данных
Для обучения модели использовались Kaggle notebooks — ~2TB исходных данных, которые после дедупликации сократились до 250GB. Критически важным этапом стало скачивание связанных наборов данных (еще 5TB) для обеспечения исполняемости кода.
Процесс подготовки данных включал три этапа:
- Масштабная дедупликация — удаление 90% дубликатов
- Загрузка связанных наборов данных с фильтрацией по релевантности
- Образовательная оценка ноутбуков с помощью Qwen3-32B
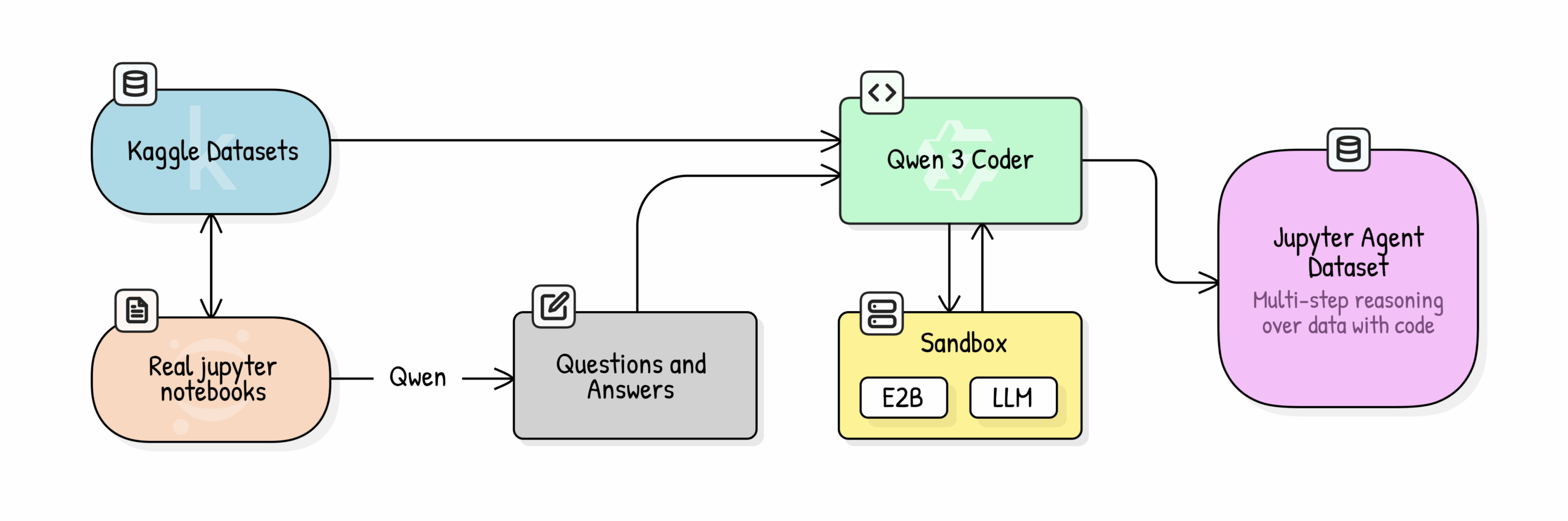
Образовательная оценка отфильтровала 70% наборов данных, оставив только те, что имеют высокую образовательную ценность — ясность, полноту и обучающую ценность. Это согласуется с выводами из статьи BeyondWeb: качество данных важнее количества.
Результаты показывают, что даже небольшие модели могут эффективно работать в агентном режиме для задач анализа данных при правильном подходе к обучению и оптимизации каркаса. Это открывает возможности для более доступных и эффективных ИИ-ассистентов в анализе данных.





Оставить комментарий