Оглавление
Третий публичный раунд AutoBench установил новый стандарт для оценки больших языковых моделей с беспрецедентным масштабом и точностью. Проект протестировал 33 модели, собрав более 300,000 индивидуальных оценок с корреляцией 90%* с ведущими бенчмарками. Одновременно с этим запущена платформа autobench.org — новый хаб для прозрачного тестирования ИИ.
Кризис оценки LLM и значение AutoBench
С тысячами языковых моделей на рынке выбор подходящей становится сложной задачей. Традиционные бенчмарки статичны, их можно «натренировать», и они часто слишком общие. AutoBench решает эти проблемы методологией Collective-LLM-as-a-Judge, используя сами LLM для генерации вопросов, ответов и оценки результатов.
Автоматизированное тестирование — единственный способ адекватно оценивать взрывной рост языковых моделей. Статические датасеты безнадежно устаревают через месяцы, а человеческая оценка слишком медленная и дорогая для масштаба сегодняшнего рынка.
Как работает AutoBench: методика
Автоматизированный итеративный процесс обеспечивает надежность и статистическую значимость:
- Динамическая генерация вопросов: Случайный выбор темы и сложности, генерация уникального вопроса
- Контроль качества: Другие LLM оценивают вопрос на ясность и релевантность
- Параллельная генерация ответов: Все модели генерируют ответы одновременно
- Коллективное ранжирование: Каждый ответ оценивается всеми LLM-судьями
- Взвешенная агрегация: Ранги комбинируются с учетом согласованности оценщиков
Третий раунд: беспрецедентный масштаб
Августовский раунд 2025 года стал самым амбициозным:
- 33 модели от OpenAI, Google, Anthropic, Alibaba
- 24 LLM-оценщика для диверсификации judgments
- 410 итераций с генерацией новых вопросов
- ~13,000 уникальных ответов
- ~300,000 индивидуальных оценок
- ~200 миллионов output-токенов и ~700 миллионов input-токенов
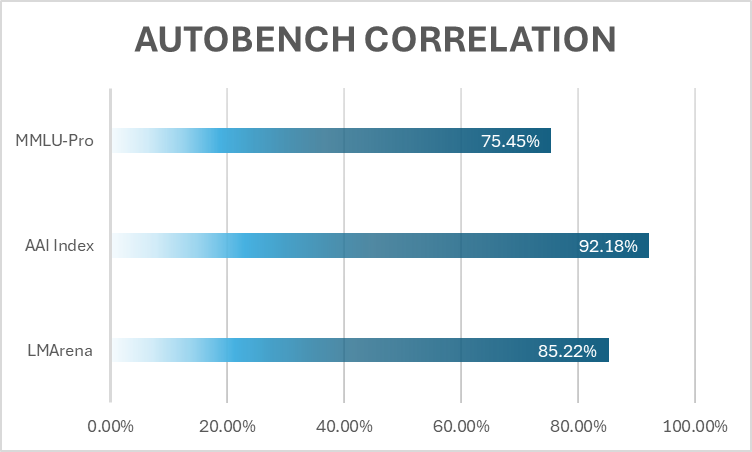
Валидация: корреляции с индустриальными стандартами
Корреляции третьего раунда подтверждают надежность методологии:
- Artificial Analysis Intelligence Index (AAII): 92.17% — почти идеальное соответствие
- LMSYS Chatbot Arena (Human Preference): 86.85% — сильное согласование с ELO
- MMLU-Plus: 75.44% — надежно для задач, требующих знаний
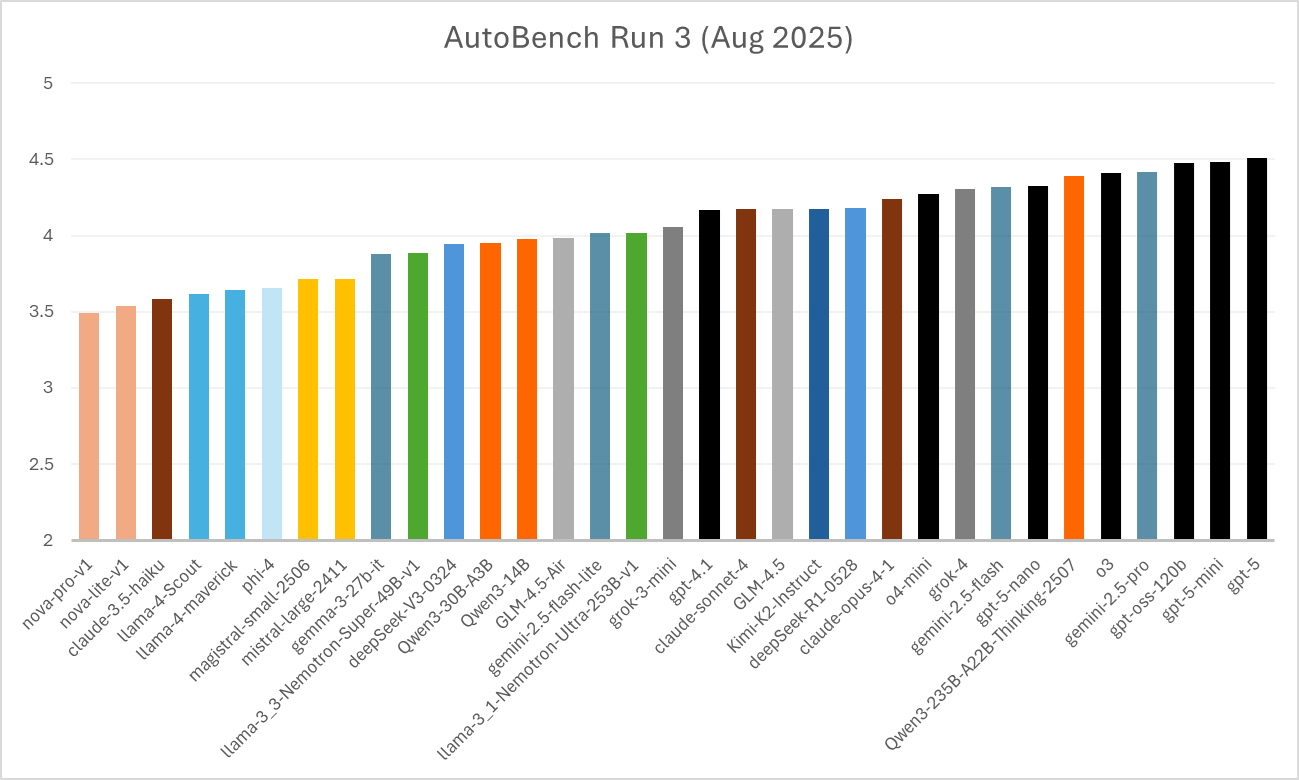
Лидерборд: лучшие модели и неожиданности
Результаты показывают жесткую конкуренцию:
- OpenAI GPT-5 — лидер с оценкой 4.5116
- Gemini 2.5 Pro (Google) — 4.4169, очков в творческих задачах
- Qwen 3 235B — сильный конкурент в смысловых задачах
Самая интересная находка — opensource модель GPT OSS 120B, достигающая state-of-the-art уровня. Это демократизирует высокую производительность и показывает, что экосистема opensource догоняет коммерческих гигантов.
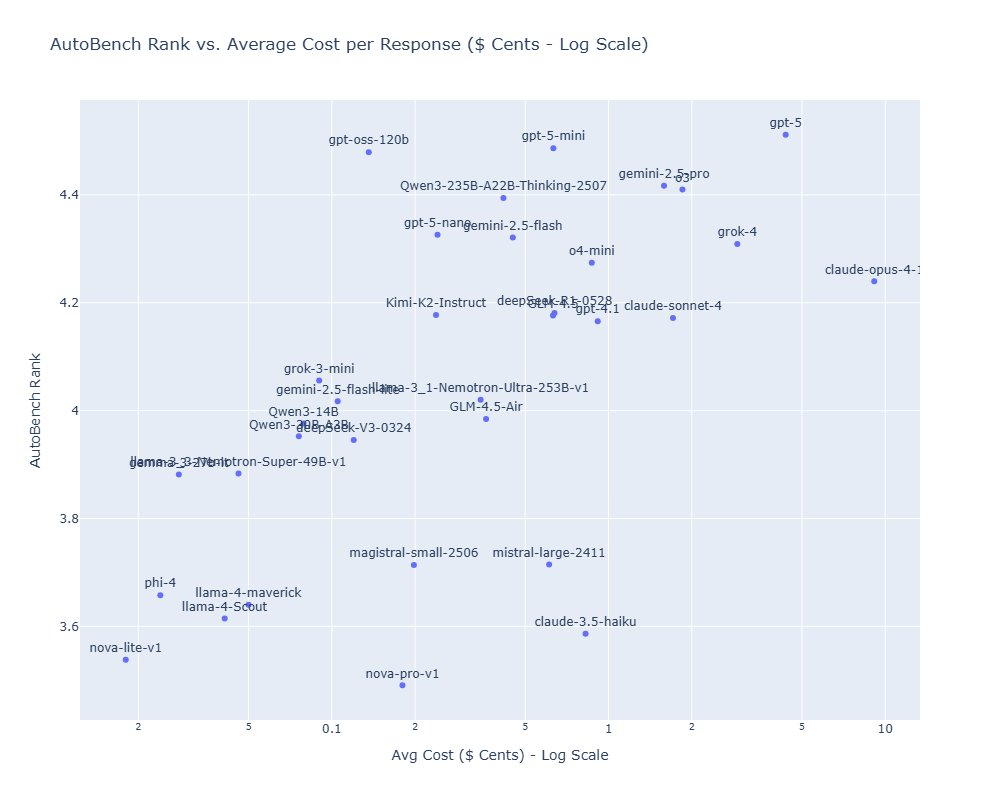
Эффективность: стоимость и скорость
AutoBench выходит за рамки pure performance, предоставляя практические метрики:
- Стоимость за ответ: Полная стоимость API-вызовов
- Задержки: Средняя и P99 длительность для продакшена
- Компромиссы: Визуализация качества vs стоимость/задержка
Запуск autobench.org
Главный сюрприз — запуск autobench.org как центра для:
- Интерактивных лидербордов с сортируемыми метриками
- Методологических сбоев и гайдов
- Enterprise-сервисов для кастомных оценок
- Обновлений и консультаций
AutoBench интегрирован в экосистему, включая Bot Scanner — «Skyscanner для LLM-ответов», ранжирующий ответы 40+ моделей в реальном времени. Сообщает Hugging Face.





Оставить комментарий