
Оглавление
Блог AWS Machine Learning пишет, что OpenAI выпустила две модели с открытыми весами: gpt-oss-120b (117 миллиардов параметров) и gpt-oss-20b (21 миллиард параметров). Обе построены на архитектуре Mixture of Experts (MoE) с контекстным окном 128K токенов.
Технические особенности моделей
Модели используют 4-битную схему квантования MXFP4, что обеспечивает высокую скорость вывода при низком потреблении ресурсов. Архитектура MoE включает:
- 128 экспертов для 120B модели
- 32 эксперта для 20B модели
- Каждый токен маршрутизируется к 4 экспертам без общих экспертов
Благодаря квантованию размеры моделей сокращены до 63 ГБ (120B) и 14 ГБ (20B), что позволяет запускать их на одном GPU H100.
Архитектура решения
Решение включает развертывание модели gpt-oss-20b на управляемых конечных точках SageMaker с использованием фреймворка vLLM и создание многоагентной системы анализа акций с помощью LangGraph.
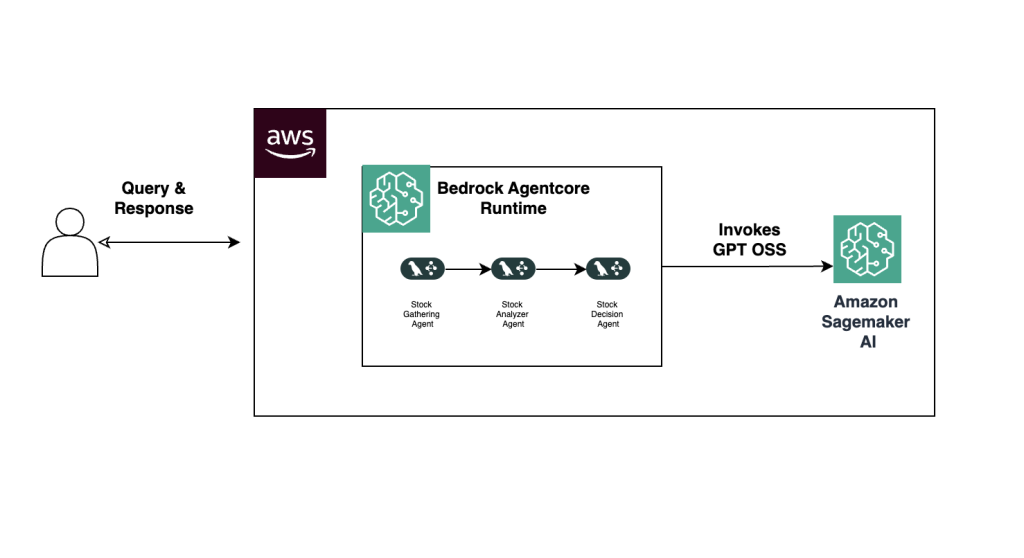
Интересно наблюдать, как AWS систематически захватывает экосистему open-source ИИ, предлагая управляемые сервисы для всего подряд. С одной стороны — это удобно для корпоративных клиентов, с другой — создает эффект «золотой клетки». Впрочем, возможность использовать собственные контейнеры через ECR оставляет пространство для маневра.
Ключевые компоненты системы
- Агент сбора данных
- Агент анализа производительности акций
- Агент генерации отчетов
- Amazon Bedrock AgentCore Runtime для оркестрации
- Модель GPT OSS на SageMaker AI для обработки запросов
Требования для развертывания
- Наличие квоты для инстансов G6e
- Созданный SageMaker Domain
- IAM-роль с правами для развертывания моделей и конечных точек
Рекомендуется использовать SageMaker Studio для сборки и публикации Docker-контейнеров в Amazon ECR, что упрощает процесс развертывания.





Оставить комментарий