
Оглавление
Графовые базы данных кардинально изменили подход к работе со сложными взаимосвязанными данными, но их специализированные языки запросов вроде Gremlin создают серьезный барьер для бизнес-аналитиков и других нетехнических пользователей. В отличие от реляционных баз с четкими схемами, графовые структуры требуют глубокого понимания их архитектуры.
Трехэтапный подход к генерации запросов
Чтобы решить эту проблему, команда AWS разработала методологию преобразования естественного языка в Gremlin-запросы с использованием моделей Amazon Bedrock, включая Amazon Nova Pro. Этот подход позволяет нетехническим специалистам эффективно взаимодействовать с графовыми базами данных.
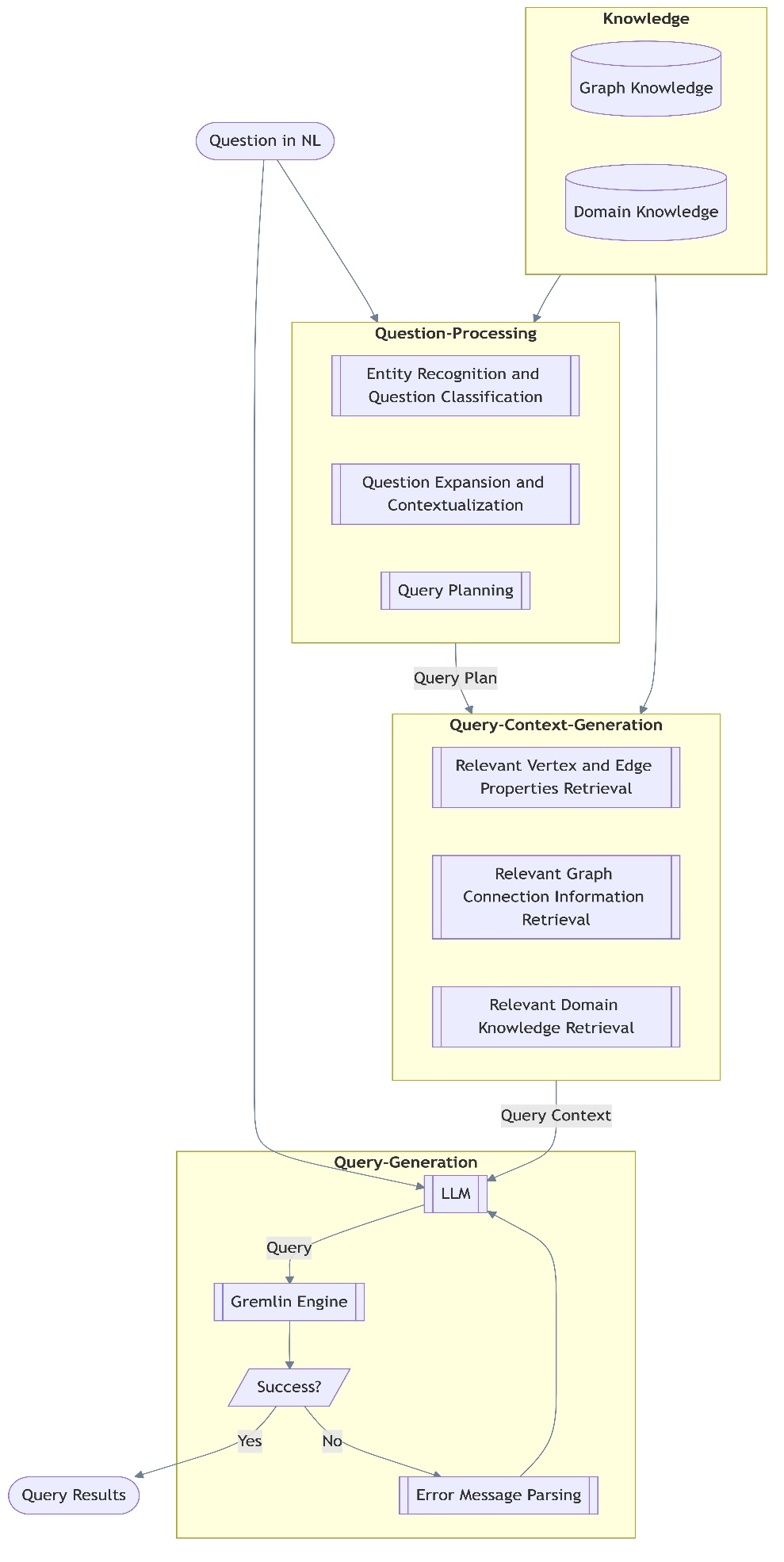
Методология состоит из трех ключевых этапов:
- Извлечение знаний о графе – анализ структуры вершин, ребер и их свойств
- Структурирование графа – преобразование в формат, аналогичный обработке text-to-SQL
- Генерация и выполнение запросов – создание Gremlin-запросов с итеративным улучшением
Извлечение графовых знаний
Для успешной генерации запросов система должна интегрировать как знания о структуре графа, так и доменные знания. Графовые знания включают:
- Метки и свойства вершин – типы вершин, их названия и атрибуты
- Метки и свойства ребер – информация о типах связей и их характеристиках
- Одношаговые соседи для каждой вершины – данные о прямых связях между вершинами
Доменные знания дополняют эту информацию и формируются двумя способами:
- Правила от клиентов – например, идентификация вершин, представляющих метаданные и не подлежащих запросам
- LLM-генерированные описания – семантические описания вершин и их свойств, созданные языковой моделью
Структурирование графа как схемы text-to-SQL
Для улучшения понимания моделями графовых структур применяется подход, аналогичный text-to-SQL обработке, где строится схема, представляющая типы вершин, ребер и их свойства. Компонент обработки вопросов работает в три этапа:
- Распознавание и классификация сущностей – идентификация ключевых элементов базы данных в вопросе
- Усиление контекста – обогащение вопроса релевантной информацией из компонента знаний
- Планирование запроса – сопоставление расширенного вопроса с конкретными элементами базы данных
Генерация и выполнение Gremlin-запросов
Финальный этап включает итеративную генерацию запросов:
- LLM генерирует первоначальный Gremlin-запрос
- Запрос выполняется в Gremlin-движке
- При успешном выполнении возвращаются результаты
- При ошибке запускается механизм парсинга сообщений об ошибках и уточнения запроса
Шаблон промпта для генерации запросов
Финальный шаблон промпта выглядит следующим образом:
## Request
Please write a gremlin query to answer the given question:
{{question}}
You will be provided with couple relevant vertices, together with their
schema and other information.
Please choose the most relevant vertex according to its schema and other
information to make the gremlin query correct.
## Instructions
1. Here are related vertices and their details:
{{schema}}
2. Don't rename properties.
3. Don't change lines (using slash n) in the generated query.
## IMPORTANT
Return the results in the following XML format:
<Results>
<Query>INSERT YOUR QUERY HERE</Query>
<Explanation>
PROVIDE YOUR EXPLANATION ON HOW THIS QUERY WAS GENERATED
AND HOW THE PROVIDED SCHEMA WAS LEVERAGED
</Explanation>
</Results>
Подход AWS демонстрирует элегантное решение классической проблемы доступности сложных технологий. Вместо того чтобы обучать всех Gremlin, они обучают Gremlin понимать всех. Ирония в том, что для демократизации доступа к данным приходится строить такие же сложные системы, как и те, доступ к которым они предоставляют. Но результат того стоит – бизнес-аналитики наконец-то смогут задавать вопросы на человеческом языке, а не изучать очередной специализированный DSL.
Сообщает AWS Machine Learning Blog.





Оставить комментарий