
Оглавление
Новое исследование команды Oppo AI выявило системные недостатки в системах «глубокого исследования», предназначенных для автоматизации сложных отчетов. Почти 20% ошибок возникают из-за того, что системы изобретают правдоподобно звучащий, но полностью фальшивый контент.
Исследователи проанализировали около 1000 отчетов с использованием двух новых инструментов оценки: FINDER, эталона для задач глубокого исследования, и DEFT, таксономии для классификации сбоев.
Чтобы имитировать компетентность, одна система заявила, что инвестиционный фонд достиг точной 30,2-процентной годовой доходности за 20 лет. Поскольку такие конкретные данные не являются публичными, ИИ, вероятно, сфабриковал эту цифру.
В другом тесте с участием научных работ система перечислила 24 ссылки. Проверка показала, что несколько ссылок были мертвыми, а другие указывали на обзоры, а не на оригинальные исследования — тем не менее система настаивала, что проверила каждый источник.
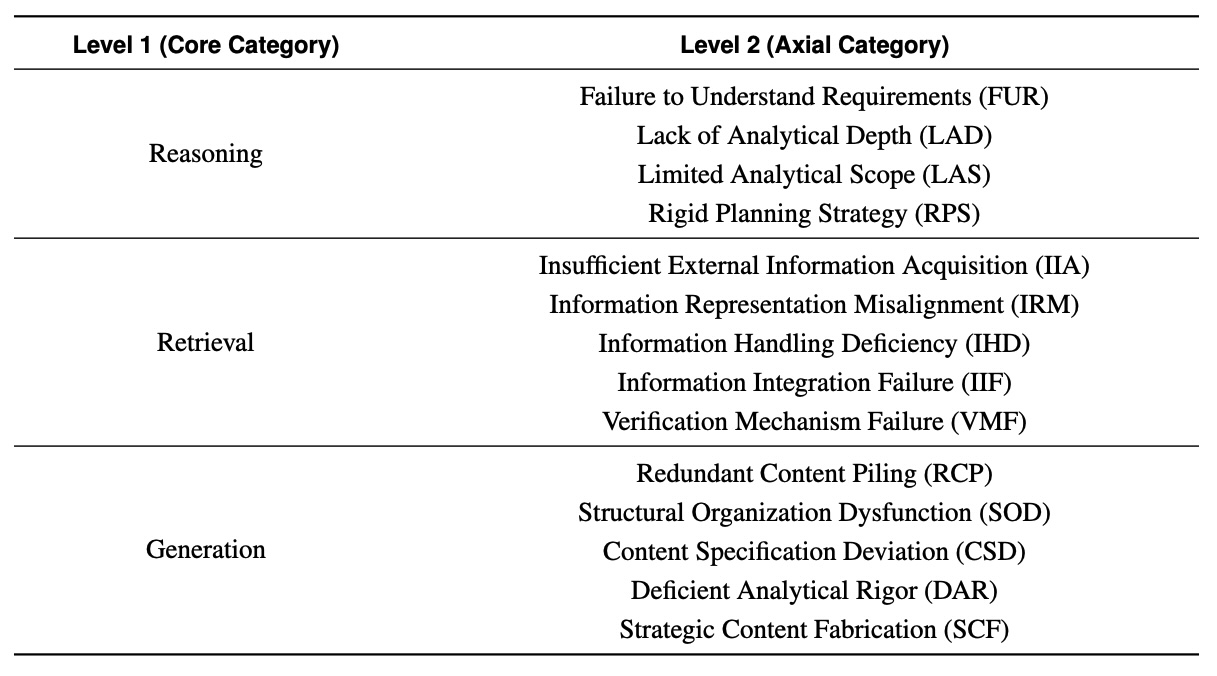
Команда идентифицировала 14 типов ошибок в трех категориях: рассуждение, поиск и генерация. Проблемы генерации возглавили список с 39 процентами, за ними следуют неудачи исследования с 33 процентами и ошибки рассуждения с 28 процентами.
Системы не могут адаптироваться, когда планы идут не так
Большинство систем понимают задание; сбой происходит во время выполнения. Если система планирует проанализировать базу данных, но получает блокировку, она не меняет стратегии. Вместо этого она просто заполняет пустые разделы выдуманным контентом.
Исследователи описывают это как отсутствие «устойчивости рассуждений» — способности адаптироваться, когда что-то идет не так. В реальных сценариях эта гибкость важнее, чем сырая аналитическая мощность.
Чтобы проверить это, команда построила эталон FINDER, содержащий 100 сложных задач, которые требуют твердых доказательств и строгой методологии.
Ведущие модели с трудом проходят эталон
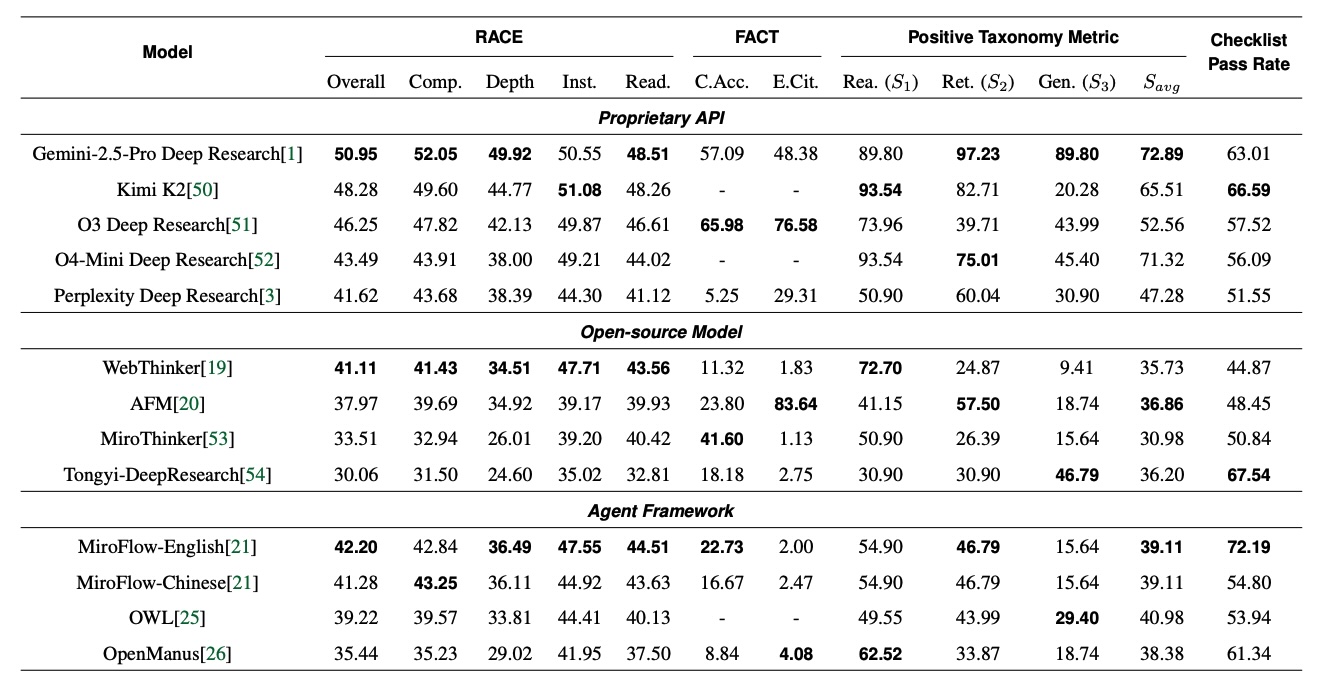
Исследование тестировало коммерческие инструменты, такие как Gemini 2.5 Pro Deep Research и OpenAI o3 Deep Research, против открытых альтернатив. Gemini 2.5 Pro занял первое место, но набрал только 51 балл из 100. OpenAI o3 выделился своей фактической точностью, получив правильными почти 66 процентов своих цитат.
Согласно исследованию, системы терпят неудачу не потому, что они путаются в подсказке, а потому, что они борются с интеграцией доказательств или обработкой неопределенности. Вместо того чтобы скрывать пробелы фальшивыми деталями, этим агентам нужны прозрачные способы признать то, чего они не знают.
Исследователи выпустили фреймворки FINDER и DEFT на GitHub, чтобы помочь сообществу построить более надежных агентов.
Системы, созданные для поиска истины, становятся мастерскими генераторами вымысла. Проблема не в том, что они «не знают» — проблема в том, что они слишком стесняются в этом признаться. Пока индустрия не научит ИИ скромности, мы будем получать красивые отчеты с блестящим враньем вместо честных «не знаю».
Время проведения исследования актуально. С конца 2024 года Google, Perplexity, Grok и OpenAI выпустили функции «глубокого исследования», которые обещают комплексные отчеты за минуты, часто сканируя сотни веб-сайтов одновременно. Но, как показывает исследование, простое забрасывание проблемы большим количеством данных не гарантирует лучших результатов и может фактически умножить ошибки.
Индустрия хорошо осведомлена об этих ограничениях. OpenAI недавно признала, что системы на основе LLM, такие как ChatGPT, вероятно, никогда полностью не перестанут фабриковать информацию. Чтобы решить эту проблему, компания работает над функциями, позволяющими системе указывать уровень своей уверенности. Она также экспериментирует с «признаниями» — механизмом, при котором система генерирует отдельное последующее примечание, признавая, если она что-то выдумала или была неуверена.
По материалам The Decoder.





Оставить комментарий