
Оглавление
Когда AI-агенты получают задачу на программирование, поиск правильного ответа требует понимания кодовой базы через чтение файлов и поиск релевантной информации. Cursor внедрил семантический поиск, который значительно превосходит традиционные инструменты вроде grep.
Преимущества семантического поиска
В отличие от regex-поиска grep, семантический поиск понимает естественный язык запросов вроде «где у нас обрабатывается аутентификация?». Cursor обучил собственную модель эмбеддингов и построил индексационные пайплайны для быстрого поиска.
- Среднее повышение точности ответов на 12,5% (от 6,5% до 23,5% в зависимости от модели)
- Кодовые изменения чаще остаются в финальной версии кода
- Пользователи достигают правильного решения за меньшее число итераций
- Улучшение точности наблюдается во всех протестированных моделях
Офлайн-тестирование
Cursor разработал бенчмарк Cursor Context Bench для оценки поиска информации в кодовых базах с известными правильными ответами. Тестирование проводилось на всех основных моделях, включая собственную Composer.
Сравнение проводилось между двумя наборами инструментов: с семантическим поиском и без него. Во всех конфигурациях семантический поиск значительно улучшал результаты.

Онлайн A/B тестирование
Для понимания влияния на пользовательский опыт провели A/B тест, где обе группы использовали одинаковую модель, но одна имела доступ к семантическому поиску, а другая — только к традиционным инструментам.
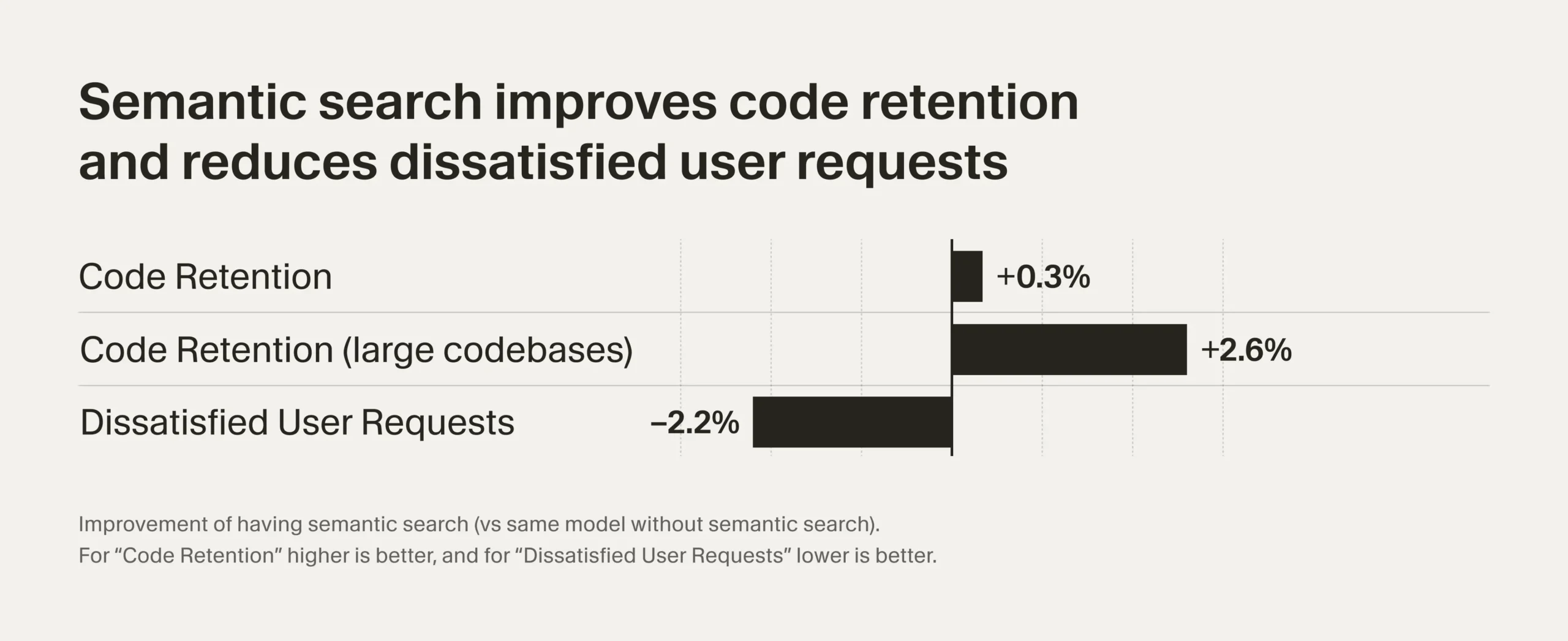
- Удержание кода: Код эффективных агентов чаще остается в пользовательских кодовых базах. При использовании семантического поиска удержание увеличилось на 0,3%, а в больших кодовых базах (1000+ файлов) — на 2,6%
- Неудовлетворенные запросы: Без семантического поиска количество неудовлетворенных follow-up запросов увеличилось на 2,2%
Кастомные модели поиска
Ключевым элементом успеха стала собственная модель эмбеддингов. Cursor использует сессии агентов как тренировочные данные: когда агент работает над задачей, он выполняет множественные поиски и открывает файлы перед нахождением нужного кода.
Анализируя эти трейсы, можно определить, что должно было быть найдено ранее в диалоге. LLM ранжирует наиболее полезный контент для каждого шага, а модель эмбеддингов обучается выравнивать similarity scores с этими ранжированиями.
Семантический поиск, который должен упростить жизнь разработчикам, требует собственной сложной инфраструктуры обучения и оценки. Но результаты говорят сами за себя — в больших проектах grep уже недостаточно. Интересно, сколько времени пройдет, прежде чем традиционные IDE догонят этот подход.
Семантический поиск стал необходимым инструментом для достижения лучших результатов, особенно в крупных кодовых базах. Агент Cursor активно использует как grep, так и семантический поиск, и именно их комбинация дает оптимальные результаты.
По материалам Cursor.





Оставить комментарий