В блоге у Амазон вышел новый материал — AWS Machine Learning Blog. Чат-ассистенты на базе Retrieval Augmented Generation (RAG) меняют подходы к поддержке клиентов и корпоративному поиску, предоставляя точные ответы на основе внутренних данных. Ключевое преимущество — использование готовых фундаментальных моделей (FM) без необходимости их переобучения. Запуск таких систем на Amazon EKS обеспечивает гибкость выбора моделей и полный контроль над инфраструктурой.
Технологическая синергия
Amazon EKS масштабируется под нагрузку и поддерживает гетерогенные вычисления:
- Процессоры CPU/GPU
- Специализированные чипы AWS Inferentia и Trainium
- ARM-архитектуры Graviton
Интеграция с NVIDIA NIM упрощает развёртывание GPU-ускоренных моделей через Docker-контейнеры. NIM Operator автоматизирует управление в Kubernetes через три компонента:
NIMCache— кеширование моделейNIMService— оркестрация микросервисовNIMPipeline— координация групп сервисов
Архитектурное решение
EKS Auto Mode с предустановленными GPU-драйверами и Karpenter NodePools позволяет запускать инстансы с GPU без ручной настройки. В связке с OpenSearch Serverless для векторного поиска и EFS для хранения данных формируется полноценный RAG-пайплайн.
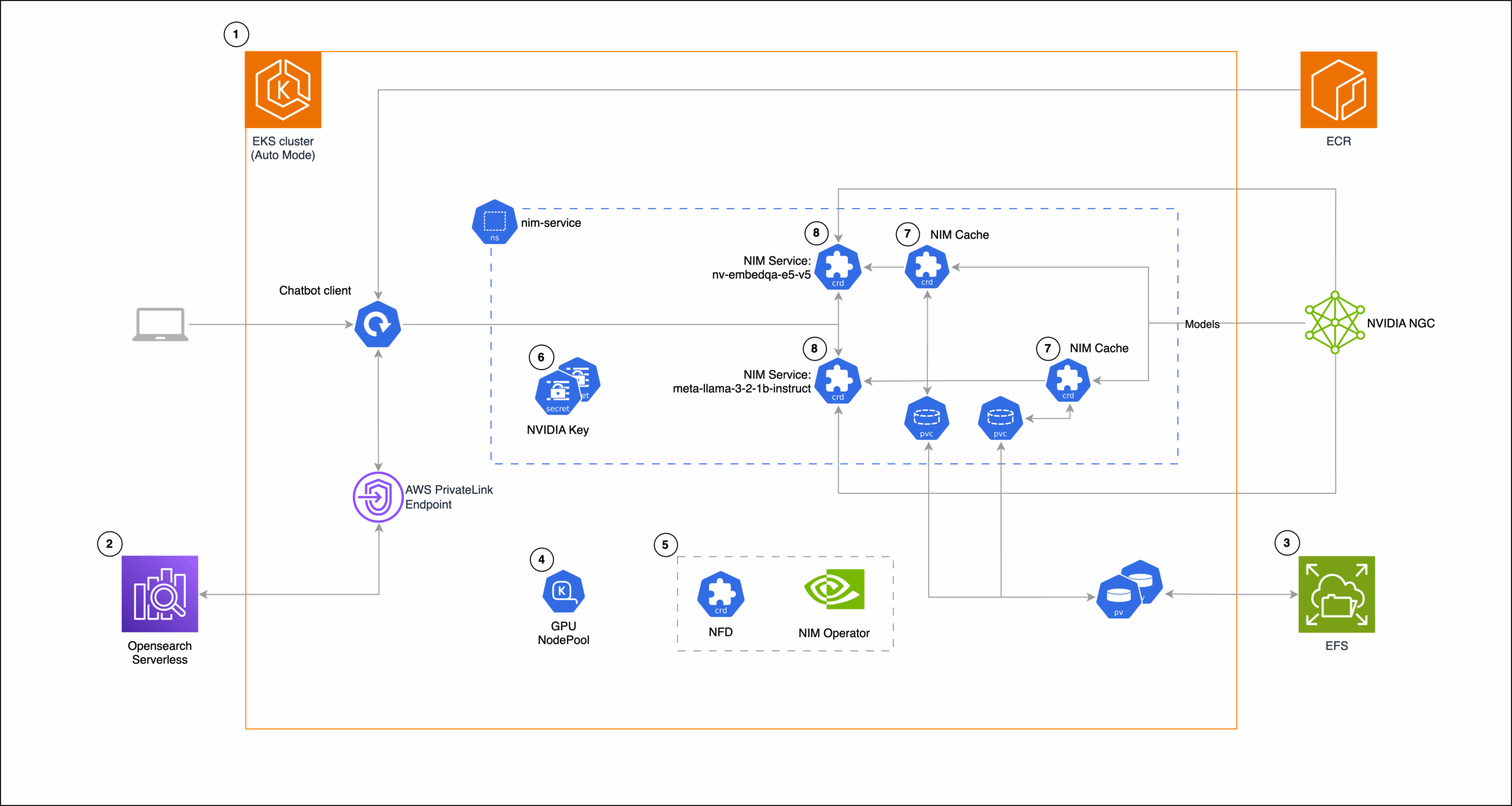
Комбинация EKS Auto Mode и NIM — серьёзный шаг к промышленному внедрению RAG. Автоматизация развёртывания GPU-инфраструктуры сокращает время настройки с дней до часов, что критично для стартапов. Однако в регионах с ограниченной доступностью GPU-инстансов гибкость решения может нивелироваться. Главный выигрыш — снижение порога входа: теперь инженерам не нужна глубокая экспертиза в CUDA или k8s для запуска LLM. Это не революция, но важная оптимизация для enterprise-сред.





Оставить комментарий