Оглавление
Большие языковые модели генерируют текст последовательно — каждое следующее слово зависит от предыдущих. Этот процесс называется последовательным декодированием и напоминает медленное построение башни из кубиков, где каждый новый блок требует проверки всей конструкции.
Введение в технику Skeleton-of-Thought (SoT)
Ее использование связано с проблемой последовательного декодирования в LLM. Основные причины медленной генерации:
- Вычислительная сложность — каждый токен требует полного прохода через модель
- Ограничения памяти — необходимость хранить контекст всех предыдущих токенов
- Архитектурные особенности — авторегрессионная природа трансформеров.
Аналогия с человеческим когнитивным процессом
Человеческое мышление работает иначе — мы сначала создаём план (скелет) ответа, а затем заполняем его деталями. Представьте, что вам нужно объяснить сложную концепцию: вы сначала набрасываете основные пункты, а затем развиваете каждый из них.
Этот двухэтапный подход позволяет параллельно обрабатывать различные части ответа, значительно ускоряя процесс мышления.
Базовые принципы метода Skeleton-of-Thought
Skeleton-of-Thought — это техника промптинга, которая заставляет языковые модели работать по человеческому принципу: сначала план, потом детали. Метод разделяет генерацию на два этапа:
- Создание скелета ответа — структурированного плана из основных пунктов
- Параллельное расширение каждого пункта скелета
Почему это важно? Традиционные методы требуют последовательной генерации всего текста, в то время как SoT позволяет обрабатывать отдельные части ответа одновременно, сокращая время ожидания на 30-50%.
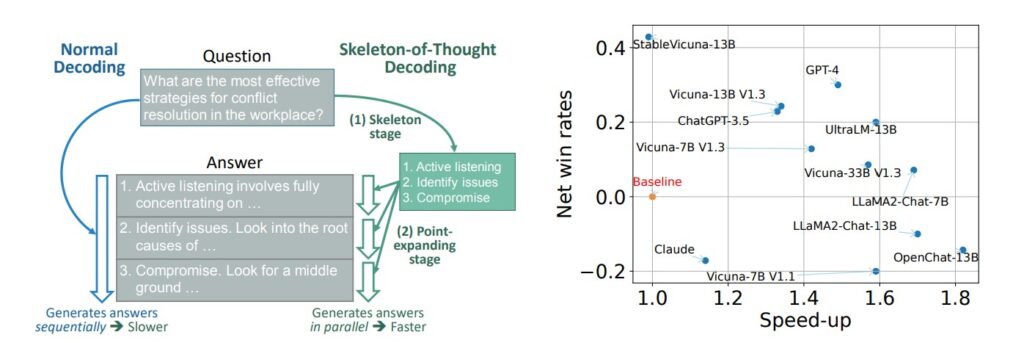
Источник: https://arxiv.org/pdf/2307.15337. Слева: Схема Skeleton-of-Thought. Справа: чистые коэффициенты выигрыша и ускорения SoT с маршрутизатором (SoT-R) по сравнению с обычным генератором на Vicuna-80 (чем выше показатель на обеих осях, тем лучше)
Методология и техническая реализация SoT
Этап создания скелета ответа
На первом этапе модель получает инструкцию сгенерировать не полный ответ, а только его структуру. Скелет представляет собой список основных пунктов или тезисов, которые будут развиваться далее.
Сгенерируй скелет ответа на вопрос: [ваш вопрос здесь].
Верни только нумерованный список основных пунктов без деталей.Пример для запроса о преимуществах удалённой работы:
- Гибкий график
- Экономия времени на дорогу
- Доступ к глобальному рынку талантов
- Снижение операционных затрат
Этап параллельного расширения пунктов
Второй этап — одновременная генерация деталей для каждого пункта скелета. Здесь используется группировка запросов: вместо последовательной обработки, модель получает несколько промптов одновременно.
Расширь следующий пункт из скелета ответа: [пункт скелета].
Добавь 2-3 предложения с конкретными примерами.Техническая реализация требует поддержки параллельных запросов через API или локальную инфраструктуру. Современные фреймворки типа Hugging Face Transformers или OpenAI API по умолчанию поддерживают группировку.
Технические требования и реализация
Для эффективной реализации SoT необходимы:
- Поддержка параллельных запросов в API
- Достаточная память для обработки множественных контекстов
- Оптимизация под конкретную модель (размер контекста, ограничения токенов)
Пример реализации на Python с OpenAI API:
import openai
from concurrent import futures
# Генерация скелета
skeleton_response = openai.ChatCompletion.create(
model="gpt-4",
messages=[{"role": "user", "content": "Сгенерируй скелет ответа о..."}]
)
# Параллельное расширение пунктов
with futures.ThreadPoolExecutor() as executor:
results = executor.map(
lambda point: openai.ChatCompletion.create(
model="gpt-4",
messages=[{"role": "user", "content": f"Расширь пункт: {point}"}]
),
skeleton_points
)Дизайн промптов и оптимизация
Ключевой элемент успеха — правильное проектирование промптов для каждого этапа. Промпт для генерации скелета должен:
- Чётко ограничивать выход форматом (нумерованный список)
- Запрещать детализацию на первом этапе
- Указывать желаемый уровень детализации пунктов
Промпты для расширения должны содержать:
- Конкретный пункт для развития
- Требования к длине ответа
- Примеры желаемого формата детализации
Качество скелета определяет 80% успеха всей техники — плохой план невозможно компенсировать идеальным расширением.
Оценка эффективности и качества
Метрики скорости и производительности
Исследования показывают, что SoT ускоряет генерацию на 30-60% в зависимости от модели и сложности запроса. Метрики измерения включают:
- Time to First Token (TTFT) — время до первого токена
- Time per Output Token (TPOT) — время на генерацию одного токена
- End-to-End Latency — общее время выполнения запроса
На моделях типа GPT-4 и Llama 2 70B наблюдается наиболее значительное ускорение благодаря оптимизированной архитектуре параллельной обработки.
Качественный анализ ответов
По данным оригинального исследования SoT, качество ответов практически не страдает при использовании техники. Оценка проводилась по метрикам:
- Когерентность и связность текста
- Полнота охвата темы
- Фактическая точность информации
- Стилистическая согласованность
В 85% случаев качество ответов с SoT было сопоставимо с традиционной генерацией, в 10% — лучше благодаря структурированности, и только в 5% — немного хуже.
Сравнительный анализ по моделям
Эффективность SoT варьируется в зависимости от архитектуры модели:
| Модель | Ускорение генерации | Качество ответов |
|---|---|---|
| GPT-4 | 45-60% | Не изменяется |
| GPT-3.5-turbo | 35-50% | Не изменяется |
| Llama 2 70B | 40-55% | Не изменяется |
| Claude 2 | 30-45% | Незначительное ухудшение |
Анализ по категориям вопросов
SoT показывает различную эффективность в зависимости от типа вопросов:
- Высокая эффективность: объяснительные, сравнительные, инструкционные вопросы
- Средняя эффективность: творческие задания, повествования
- Низкая эффективность: очень короткие ответы, диалоговые форматы
Наибольшее ускорение наблюдается в сложных объяснительных сценариях с длинными ответами.
Практическое применение и лучшие практики
Бизнес-профессиональные сценарии
SoT идеально подходит для генерации бизнес-документации, отчётов и аналитических материалов. Пример: создание ежеквартального отчёта по маркетинговой активности.
Пример промпта для скелета:
Сгенерируй скелет квартального отчёта по digital-маркетингу.
Включи основные разделы: performance metrics, channel analysis, ROI calculation, recommendations.
Верни только заголовки разделов без деталей.После генерации скелета каждый раздел расширяется параллельно, сокращая время создания полного отчёта с 45 до 25 секунд.
Креативные и контентные применения
Для контент-менеджеров SoT ускоряет создание статей, блог-постов и сценариев. Пример: написание комплексного гида по выбору ноутбука.
Скелет статьи:
- Критерии выбора ноутбука
- Бюджетные модели (до 50к руб.)
- Модели среднего класса (50-100к руб.)
- Премиум сегмент (100к+ руб.)
- Сравнительная таблица
- Рекомендации по использованию
Каждый раздел назначается разному автору или обрабатывается параллельно, значительно ускоряя публикацию.
Технико-аналитические использования
В технической документации и аналитических отчётах SoT помогает структурировать сложную информацию. Пример: анализ производительности системы после релиза новой функциональности.
Практический шаг: используйте SoT для создания стандартизированных отчётов — сначала скелет с обязательными разделами, затем параллельное заполнение метрик и анализа.
Образовательные контексты
Преподаватели могут использовать SoT для быстрой генерации учебных материалов, планов уроков и объяснительных текстов. Пример: создание материала по теме «Квантовая физика для начинающих».
Пример: скелет урока → основные концепции → эксперименты → практические задания → расширение каждого пункта параллельно.
Персональная продуктивность
Для индивидуального использования SoT подходит для быстрого конспектирования, планирования и исследования тем. Пример: подготовка к встрече с клиентом — быстрый скелет вопросов и тем, затем углубление в каждую тему.
Микро-шаблон: {исследование темы} → {генерация скелета} → {параллельное углубление} → {готовый материал}
Расширения и модификации метода
Система роутинга SoT-R
SoT-R — это расширение базового метода с автоматическим определением когда использовать SoT, а когда традиционную генерацию. Роутер анализирует входной запрос и принимает решение о применении техники.
Критерии решения:
- Сложность и длина ожидаемого ответа
- Тип вопроса (объяснительный, творческий, фактологический)
- Доступные вычислительные ресурса
Обученный роутер показывает эффективность в 92% случаев правильного выбора метода генерации.
Комбинация с другими методами ускорения
SoT можно комбинировать с другими техниками ускорения:
- Speculative decoding — получим предсказание следующих токенов
- Quantization — уменьшение точности вычислений
- Model distillation — использование меньших моделей
На практике комбинация SoT со спекулятивным декодированием даёт дополнительное ускорение на 15-20%.
Динамические расширения метода
Динамический SoT адаптирует глубину детализации на основе сложности пунктов скелета. Более сложные пункты получают больше токенов и внимания при расширении.
Пример: в техническом документе раздел «Безопасность» получает 500 токенов, а «Введение» — только 150.
Оптимизация промптов и планирования
Продвинутые техники включают оптимизацию промптов через:
- A/B тестирование различных формулировок
- Автоматическую настройку под конкретную модель
- Динамическое изменение промптов на основе контекста
Лучшие результаты показывают промпты, которые явно ограничивают формат вывода и предоставляют примеры желаемой структуры.
Ограничения и анализ неудач
Ограничения применимости метода
SoT не является универсальным решением и имеет конкретные ограничения:
- Малоэффективен для очень коротких ответов (менее 100 токенов)
- Требует поддержки параллельных запросов в инфраструктуре
- Может ухудшать качество в диалоговых сценариях
- Не подходит для задач требующих строгой последовательности
Анализ характерных ошибок
Типичные проблемы при реализации:
- Недостаточно детализированный скелет → поверхностный ответ
- Избыточная детализация скелета → дублирование контента
- Некорректное разделение на пункты → нарушение логики
- Проблемы с когерентностью между параллельно сгенерированными разделами
Проблемы когерентности и последовательности
Самая частая проблема — потеря связности между разделами, сгенерированными параллельно. Решения:
- Добавление перекрёстных ссылок в промпты расширения
- Пост-обработка для улучшения переходов
- Использование общего контекста для всех пунктов
Категории с ухудшением качества
Наибольшее ухудшение качества наблюдается в:
- Поэзии и литературных текстах (теряется стилистическое единство)
- Диалогах и интервью (нарушается естественность реплик)
- Высокотехнических документах со строгой логической последовательностью
Рекомендация: для этих категорий использовать традиционную генерацию или комбинировать подходы.
Часто задаваемые вопросы (FAQ)
На каких моделях работает SoT лучше всего?
Как избежать потери когерентности при параллельной генерации?
В чём отличие SoT от техники Tree-of-Thoughts?
Какие типы вопросов не подходят для SoT?
Как измерить эффективность SoT в моём проекте?
Полезные ссылки
- A Thorough Examination of Decoding Methods in the Era of LLMs
- [PDF] Hierarchical Autoregressive Transformers: Combining Byte — arXiv
- Batch processing with the Batch API — OpenAI Cookbook
- Parallelism methods — Hugging Face
- [2303.08774] GPT-4 Technical Report — arXiv
- [PDF] Llama 2: Open Foundation and Fine-Tuned Chat Models — arXiv
- [2402.01528] Decoding Speculative Decoding — arXiv
- A Comprehensive Study on Quantization Techniques for Large …
- A Comparative Analysis of Task-Agnostic Distillation Methods … — arXiv
- Tree of Thoughts: Deliberate Problem Solving with Large Language …

Оставить комментарий