Оглавление
- Введение в технологию RAG
- Основная архитектура и рабочий процесс RAG
- Подготовка данных и контента
- Векторные представления и оптимизация поиска
- Конфигурация и оптимизация извлекателя
- Инжиниринг промптов для RAG
- Интеграция LLM и выбор модели
- Оптимизация производительности и мониторинг
- Продвинутые техники RAG
- Часто задаваемые вопросы (FAQ)
Retrieval-Augmented Generation (RAG) – это подход, который значительно расширяет возможности больших языковых моделей. Он позволяет LLM использовать внешние источники информации для генерации ответов, делая их более точными, актуальными и релевантными. По состоянию на октябрь 2025 года, RAG продолжает оставаться фундаментальной архитектурой для улучшения LLM с помощью актуальной, предметно-ориентированной и точной информации
Введение в технологию RAG
RAG объединяет два ключевых компонента: извлечение (Retrieval) и генерацию (Generation). Сначала система извлекает релевантные документы или фрагменты текста из внешнего корпуса данных (например, базы знаний компании). Затем LLM использует эту извлеченную информацию для формирования ответа на запрос пользователя.
Представьте, что LLM – это студент, а RAG – это библиотекарь, который помогает студенту найти нужные книги для написания эссе.
Почему RAG важен сейчас
Традиционные LLM ограничены знаниями, полученными во время обучения. Они не могут самостоятельно получать доступ к актуальной информации или корпоративным данным. RAG решает эту проблему, предоставляя LLM доступ к постоянно обновляемым источникам информации. Это особенно важно для предприятий, где требуется работа с актуальными данными и специфическими знаниями. Без RAG, LLM могут выдавать устаревшую или неточную информацию, что может привести к ошибочным решениям, а RAG значительно снижает галлюцинации и повышает фактическую точность.
RAG превращает статическую языковую модель в динамическую систему, способную работать с самыми свежими данными из вашей базы.
Ключевые преимущества
RAG предлагает ряд значительных преимуществ для бизнеса:
- Повышение точности и актуальности ответов: позволяет LLM использовать самые свежие данные, что снижает риск предоставления устаревшей информации.
- Доступ к корпоративным знаниям: позволяет LLM использовать внутренние базы знаний, документы и другие источники информации компании. Например, RAG можно использовать для ответа на вопросы о продуктах, услугах или политиках компании.
- Улучшение качества ответов: позволяет LLM генерировать более полные и информативные ответы, так как они основаны не только на внутренних знаниях модели, но и на внешних источниках информации.
- Прозрачность и отслеживаемость: позволяет отслеживать источники информации, которые использовались для генерации ответа. Это повышает прозрачность и позволяет проверять достоверность информации.
RAG находит применение в различных областях, например, в службе поддержки клиентов (генерация ответов на основе базы знаний), в продажах (создание брифингов для встреч на основе заметок и электронных писем) и в других сферах, где требуется работа с актуальной и специфической информацией.
Основная архитектура и рабочий процесс RAG
RAG (Retrieval-Augmented Generation) – это не просто сумма двух частей, а сложная система, требующая четкого понимания архитектуры и потока данных. Рассмотрим ключевые аспекты.
Поток процесса RAG
Процесс RAG начинается с запроса пользователя. Этот запрос преобразуется в векторный вид (эмбеддинг) для поиска релевантной информации в векторной базе данных. Далее происходит семантический поиск, который находит наиболее подходящие документы или фрагменты текста. Извлеченная информация используется для дополнения промпта, который подается на вход LLM. Она, в свою очередь, генерирует ответ, опираясь как на свои внутренние знания, так и на предоставленный контекст.
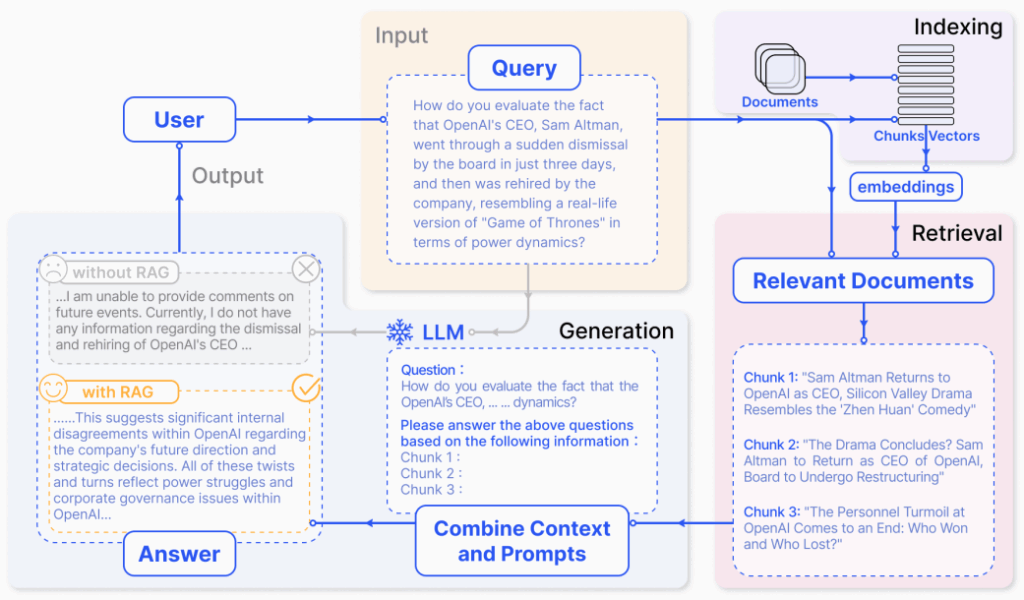
Источник: https://arxiv.org/pdf/2312.10997. Пример использования RAG для ответа на вопросы: индексирование запроса, поиск информации и генерация ответа.
Пример: Пользователь спрашивает: «Какие условия гарантии на iPhone 15?». Система RAG ищет в базе знаний компании документы, содержащие информацию о гарантии на iPhone 15, и передает их языковой модели. LLM генерирует ответ, используя эту информацию.
Компонентная архитектура
Архитектура RAG включает в себя несколько ключевых компонентов:
- Retriever (Векторная БД): Отвечает за поиск релевантной информации. Это может быть векторная база данных, такая как Pinecone или Weaviate.
- Context Assembler: Собирает извлеченные фрагменты текста и формирует контекст для LLM.
- Generator (LLM): Генерация ответа на основе промпта и предоставленного контекста. Это может быть любая LLM, например, GPT-4o, Gemini 2.5 Pro или Llama 3/4.
- Request Router: Определяет, какие данные необходимо извлечь и из каких источников.
- Post-processing: Обрабатывает сгенерированный LLM ответ, например, форматирует его или удаляет лишнюю информацию.
Совет: При выборе векторной базы данных учитывайте скорость поиска, масштабируемость и стоимость.
Паттерны потока данных
Существует несколько основных паттернов потока данных в RAG:
- Базовый RAG: Запрос пользователя -> Извлечение информации -> Генерация ответа.
- Agentic RAG (продвинутый): Дополнительные LLM используются для предварительной обработки запроса и выбора наиболее подходящих источников информации. Это позволяет системе более эффективно работать со сложными запросами.
Agentic RAG, где ИИ-агент проводит итеративное рассуждение, извлечение и даже использование внешних инструментов, имитируя рабочий процесс человека-аналитика, набирает обороты в корпоративных приложениях, требующих точности, адаптивности и многоэтапного решения проблем.
Пример Agentic RAG: Пользователь задает сложный вопрос, требующий анализа нескольких источников. Первая LLM анализирует запрос и определяет, какие источники информации необходимо использовать. Затем происходит извлечение информации из этих источников, и вторая LLM генерирует ответ на основе полученного контекста.
Инжиниринг контекста играет ключевую роль в продвинутомRAG, позволяя LLM более эффективно использовать извлеченную информацию.
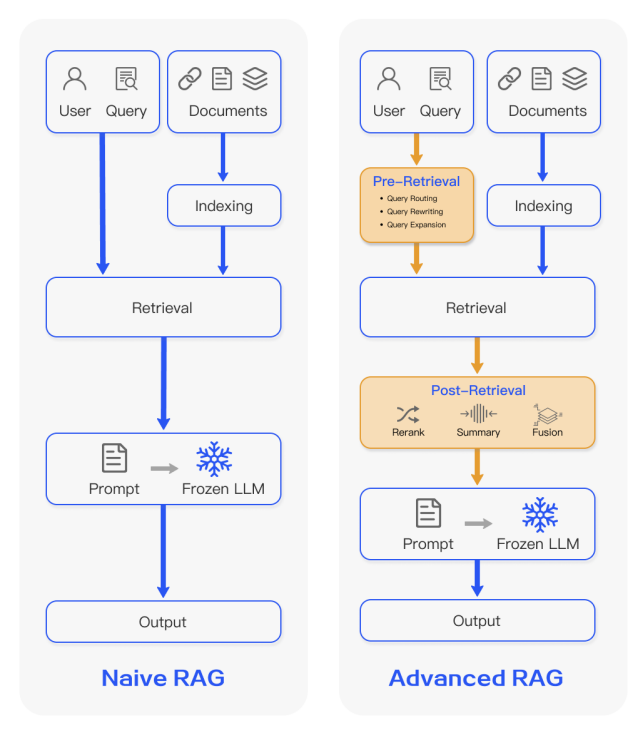
Источник: https://arxiv.org/pdf/2312.10997. Разница между базовым и продвинутым RAG/
Вывод: понимание архитектуры и потока данных RAG необходимо для успешной реализации этой технологии. Экспериментируйте с различными компонентами и паттернами, чтобы найти оптимальное решение для вашей задачи.
Подготовка данных и контента
Эффективность RAG напрямую зависит от качества данных, которые используются для поиска и генерации ответов. Правильная подготовка и организация контента – залог успеха всей системы.
Поддерживаемые типы контента
RAG системы поддерживают различные типы контента, но не все они одинаково хорошо подходят для этой задачи. Важно учитывать особенности каждого формата при подготовке данных.
Примеры поддерживаемых форматов:
- Текст: TXT, HTML, PDF. Текстовые форматы – основа для RAG. Убедитесь, что текст хорошо структурирован и отформатирован. Для PDF-файлов часто требуется предварительная обработка для извлечения чистого текста, особенно для сканированных документов, где может потребоваться распознавание символов (OCR).
- Аудио: MP3, WAV, FLAC, MPGA, M4A, OGG. Для аудио необходимо предусмотреть транскрибацию.
- Видео: MP4, MPEG, WEBM. Как и в случае с аудио, требуется транскрибация и, возможно, выделение ключевых кадров.
- RAG системы могут интегрироваться с различными корпоративными базами знаний вроде Salesforce Knowledge, но всегда требуется проверка актуальности и полноты данных.
Лучше сразу проверить, как система обрабатывает каждый тип контента, чтобы избежать неожиданностей в дальнейшем.
Поддерживаемые платформы: RAG системы могут интегрироваться с данными из различных платформ, включая Google Cloud Storage, Azure Blob Store, SharePoint, Google Drive и Confluence, часто через специализированные коннекторы или API.
Руководство по формированию контента
Чтобы RAG работала эффективно, контент должен быть не только актуальным, но и правильно структурированным.
Рекомендации по формированию контента:
- Детализация: Предоставляйте максимально подробную информацию.
- Примеры: Используйте реальные примеры из практики.
- Структура: Четко структурируйте статьи с использованием заголовков (H1-H6).
- Разделение: Размещайте контент по разным полям в статьях базы знаний.
- Alt-текст: Добавляйте описания к изображениям и видео.
- Фокус: Концентрируйтесь на одной теме в каждом фрагменте контента.
- Аудит: Регулярно проводите аудит знаний для поддержания актуальности.
- Таблицы: Преобразуйте сложные таблицы в JSON или HTML для лучшей обработки.
Стратегии разделения на фрагменты
Разбиение контента на фрагменты (chunks) – важный этап подготовки данных для RAG. Оптимальный размер фрагмента зависит от плотности информации и структуры контента.
Рекомендации по фрагментированию:
- Размер: Рекомендуемый максимальный размер фрагмента составляет 512 токенов (примерно 400-500 слов) для точных запросов. Для более широкого контекста могут использоваться фрагменты размером 1000-2000 токенов. Оптимальный размер фрагмента может варьироваться и требует экспериментов в зависимости от плотности информации и структуры контента.
- Структура: Старайтесь, чтобы фрагменты были логически завершенными и содержали законченную мысль.
Пример: Если статья посвящена настройке сетевого оборудования, разбейте ее на фрагменты, посвященные отдельным этапам настройки (например, настройка IP-адреса, настройка DNS, настройка маршрутизации).
Мультиязычная поддержка
RAG системы поддерживают работу с контентом на разных языках благодаря использованию многоязычных моделей эмбеддингов.
Особенности:
- Поддержка языков: Поддерживаются десятки языков.
- Семантическое сходство: Семантическое сходство сохраняется между языками, что позволяет искать информацию на одном языке и получать ответы на другом.
Совет: Убедитесь, что выбранная вами LLM поддерживает необходимые языки.
Методы очистки данных:
- Дедупликация: Dedupe.io, Pandas.
- Нормализация текста: spaCy, NLTK.
- Разрешение сущностей: spaCy, DeduceML.
Вывод: Тщательная подготовка данных – это фундамент успешной RAG системы. Уделите внимание выбору форматов, структурированию контента, фрагментированию и поддержке мультиязычности, чтобы получить максимальную отдачу от вашей LLM.
Векторные представления и оптимизация поиска
Векторные представления (embeddings) и оптимизация поиска — критически важные элементы RAG, определяющие, насколько релевантную информацию система сможет извлечь.
Выбор модели для эмбеддингов
Выбор модели для создания векторных представлений – это компромисс между скоростью, стоимостью и качеством.
Такие модели, как E5 Large Multilingual (например, intfloat/e5-large-v2), отлично подходят для работы с множеством языков (более 100) и определения семантической близости между ними, хотя и не являются самыми топовыми на октябрь 2025 года.
OpenAI text-embedding-3-large – высокопроизводительная проприетарная моделью, предлагающей сильную многоязычную поддержку и возможность сокращения размерности векторов, а OpenAI Ada v2 остается быстрым и экономичным вариантом для общих задач на английском языке. Sentence Transformers (SBERT) – это «золотой стандарт» для семантического поиска, особенно если использовать модели, обученные на специфических доменах, например, all-MiniLM-L6-v2 для эффективности.
Среди других высокопроизводительных моделей, актуальных в 2025 году, выделяются BAAI BGE-M3 (поддерживающая плотный, разреженный и мультивекторный поиск на более чем 100 языках), NVIDIA NV-Embed-v2, Voyage AI’s voyage-3.5 и Google Gemini Embedding.
Варианты векторных баз данных
Векторные базы данных – это хранилища для векторных представлений, обеспечивающие быстрый поиск. При выборе базы данных учитывайте объем данных, требуемую скорость поиска, сложность интеграции и необходимость гибридного поиска.
Популярные варианты – Pinecone, Weaviate, Milvus, Qdrant и Chroma. Milvus (часто используемый с Zilliz Cloud) является масштабируемым решением с открытым исходным кодом, оптимизированным для огромных объемов данных и высокой пропускной способности, но может быть более сложным в настройке из-за своей распределенной архитектуры.
FAISS (Facebook AI Similarity Search) — это библиотека для эффективного поиска сходства и кластеризации плотных векторов, часто используемая как компонент в RAG системах, но не являющаяся полноценной векторной базой данных в том же смысле, что и другие.
Для ускорения поиска часто используют ANN (Approximate Nearest Neighbor) – алгоритмы приближенного поиска ближайших соседей, которые могут быть в 10-100 раз быстрее точного поиска.
Алгоритмы поиска
Алгоритмы поиска определяют, как быстро и точно система находит релевантные векторы:
- HNSW (Hierarchical Navigable Small World) – это графовая структура данных, обеспечивающая эффективный поиск ближайших соседей.
- KNN (K-Nearest Neighbors) находит K ближайших векторов, используя различные метрики расстояния.
- Косинусное сходство (Cosine similarity) измеряет косинус угла между векторами, определяя их семантическую близость.
- LSH (Locality-Sensitive Hashing) хеширует похожие векторы в одни и те же «корзины», что ускоряет поиск.
Пример: Для поиска документов, близких по смыслу, используйте косинусное сходство и HNSW.
Конфигурация гибридного поиска
Гибридный поиск объединяет векторный (семантический) и ключевой (лексический, например, BM25) поиск в одном запросе. Это полезно, когда важны как смысл, так и конкретные термины, например, если пользователи ищут товары по названию или бренду. Гибридный поиск улучшает как полноту, так и точность результатов.
Например, если в запросе есть конкретное название продукта, гибридный поиск поможет найти документы, где это название упоминается, даже если семантически они не самые близкие.
Важно: использование гибридного поиска может увеличить потребление ресурсов по сравнению с чисто векторным поиском, но часто оправдано повышением релевантности.
Конфигурация и оптимизация извлекателя
Настройка и оптимизация извлекателя (retriever) – это тонкая настройка RAG, позволяющая добиться максимальной релевантности и скорости поиска. Здесь важны как выбор правильного типа извлекателя, так и его конфигурация.
Типы и настройка retriever
Выбор типа извлекателя зависит от структуры данных и требований к поиску. Для базовых сценариев многие RAG-фреймворки предоставляют стандартные извлекатели, которые могут возвращать фиксированное количество результатов.
Однако для более сложных сценариев часто требуется ручная настройка. Это может быть необходимо для работы с разными источниками данных, детального контроля над потоками данных, кастомных стратегий разбиения на фрагменты или использования других типов извлекателей и моделей эмбеддингов.
Пример: Если нужно искать информацию только в определенном разделе базы знаний, создайте отдельный извлекатель, настроенный на этот раздел.
Конфигурация фильтров
Фильтры позволяют ограничить область поиска, повышая релевантность результатов. Существуют pre-retrieval фильтры, которые ограничивают набор данных перед поиском, основываясь на полях, определенных в index builder. Также есть динамические пре-фильтры, значения которых задаются во время выполнения, используя синтаксис $placeholder или аналогичные механизмы.
Пример: Account = $placeholder, где $placeholder сопоставляется с ID аккаунта из шаблона промпта в Prompt Builder. Это позволяет показывать пользователю только информацию, относящуюся к его аккаунту.
Оптимизация производительности
Оптимизация производительности включает в себя настройку параметров поиска и использование эффективных алгоритмов. Важно найти баланс между скоростью и точностью. Методы включают кэширование эмбеддингов и результатов запросов, а также выбор оптимального размера моделей.
Совет: профилируйте запросы, чтобы выявить узкие места и оптимизировать их.
Продвинутые режимы извлечения
Продвинутые режимы извлечения позволяют повысить качество результатов за счет многоэтапного поиска. Один из таких режимов, известный как двухфазное извлечение или многоступенчатый поиск, включает в себя:
- Первый поиск с исходным запросом.
- Суммирование или перефразирование результатов.
- Перефразировка запроса с использованием LLM и результатов суммирования для уточнения.
- Второй поиск с перефразированным запросом.
- Дополнение промпта результатами второго поиска.
Пример: пользователь задает сложный вопрос, требующий анализа нескольких источников. Система сначала ищет общую информацию, затем перефразирует запрос, чтобы уточнить детали, и ищет более конкретную информацию.
Правильная настройка и оптимизация извлекателя – это ключ к эффективной RAG системе. Экспериментируйте с различными типами извлекателей, фильтрами и алгоритмами поиска, чтобы найти оптимальное решение для вашей задачи.
Инжиниринг промптов для RAG
Инжиниринг промптов играет ключевую роль в RAG, определяя, как LLM использует извлеченную информацию для генерации ответов. Эффективный промпт – это четкая инструкция, которая направляет LLM к желаемому результату.
Структура шаблона промпта
Структура шаблона промпта должна быть четкой и понятной для LLM. Важно разделить запрос пользователя и извлеченную информацию, используя явные разделители. Пример: «Пожалуйста, ответьте на вопрос: [ВОПРОС ПОЛЬЗОВАТЕЛЯ] используя следующую информацию: [ИЗВЛЕЧЕННЫЙ КОНТЕКСТ]». Такая структура позволяет LLM четко понимать, что от нее требуется.
Сборка контекста
Сборка контекста (Context assembly) – это процесс объединения извлеченных фрагментов текста в единый контекст для LLM. Важно отбирать наиболее релевантные фрагменты и избегать перегрузки контекста. Стратегии «Stuffing» (все документы в одном промпте) и «Map-reduce» (сначала суммирование, затем объединение) позволяют эффективно управлять контекстом. Приоритезируйте документы с наивысшей релевантностью и используйте усечение или сжатие, если необходимо.
Дизайн инструкций
Инструкции должны быть четкими, конкретными и учитывать особенности LLM. Пример продвинутых инструкций:
- Проанализируйте запрос.
- Просмотрите предоставленные знания.
- Оцените достаточность информации.
- Сформулируйте ответ с правилами:
• Найдите релевантные фрагменты статей и извлеките ID источника.
• Используйте релевантный контент для генерации ответа.
• Если нет релевантного контента, установите source_id в NONE и ответ в сообщение с извинениями. - Обеспечьте вежливый, профессиональный, краткий ответ на указанном языке.
- Проверьте соответствие ответа инструкциям.
Форматирование ответа
Форматирование ответа – важный аспект, определяющий удобство восприятия информации. Укажите LLM желаемый формат ответа (например, список, таблица, абзац). Обеспечьте единообразие форматирования для всех ответов.
Пример: Если требуется ответ в виде списка, укажите это в промпте: «Пожалуйста, предоставьте ответ в виде списка с маркировкой.»
Хорошо спроектированный промпт может повысить точность ответов RAG на 30-50% по сравнению с базовыми инструкциями
Интеграция LLM и выбор модели
Выбор и интеграция большой языковой модели (LLM) – ключевой этап RAG. От этого зависит стоимость, скорость и качество ответов.
Критерии выбора LLM
При выборе LLM учитывайте:
- Размер контекстного окна: Определяет объем информации, который LLM может обработать за раз. Чем больше, тем лучше, но и дороже.
- Лимиты токенов: Ограничивают длину входных и выходных данных.
- Поддержка языков: Важно, если работаете с мультиязычным контентом.
- Стоимость: OpenAI (GPT-x) – мощный, но дорогой. Важно отметить, что OpenAI официально вывела из эксплуатации GPT-4 и планирует предоставлять заблаговременное уведомление о любых будущих изменениях моделей, включая переход на GPT-5. Google Gemini – хорош для мультиязычных задач и мобильных устройств.
- Производительность: Задержка (latency) и пропускная способность (throughput) важны для скорости работы.
Пример: Для задач, требующих глубокого понимания контекста, выбирайте модели с большим контекстным окном, даже если они дороже.
Шаблоны интеграции
Существует несколько способов интеграции LLM:
- Прямой вызов API: Самый простой способ, но требует обработки ошибок и управления тарифами.
- Использование библиотек: LangChain и LlamaIndex упрощают интеграцию с различными LLM и остаются ведущими фреймворками в 2025 году.
Начните с простого API-вызова, а затем переходите к библиотекам для более сложных задач.
Оптимизация параметров
Ключевые параметры LLM:
- Температура: Влияет на случайность ответов. Чем выше, тем более креативные ответы, но и выше риск ошибок.
- Максимальное количество токенов на выходе: Ограничивает длину ответа.
- Стоп-последовательности: Определяют символы, при которых LLM должна прекратить генерацию.
Пример: для вопросов с ответами по фактическим данным снижайте параметр temperature, чтобы получить более точные ответы.
Управление стоимостью
Управление стоимостью LLM – важная задача.
- Пакетные вызовы: Отправляйте несколько запросов в одном вызове API.
- Адаптивные интервалы обновления: Обновляйте эмбеддинги только при изменении контента.
- Потоковое API: Используйте потоковую передачу данных, если важна низкая задержка.
Пример: Если у вас много однотипных запросов, объедините их в пакетный вызов, чтобы сэкономить на стоимости.
Выбор и интеграция LLM – это баланс между стоимостью, производительность и качеством. Тщательно оценивайте критерии выбора и оптимизируйте параметры для достижения наилучших результатов.
Оптимизация производительности и мониторинг
Для поддержания эффективности RAG необходимы стратегии оптимизации и мониторинга. Это позволяет выявлять и устранять проблемы, обеспечивая актуальность и точность ответов.
Методы оптимизации
Оптимизация включает в себя несколько подходов:
- Перефразирование запроса — улучшает релевантность поиска.
- Переранжирование результатов — позволяет поднять наиболее подходящие документы в выдаче.
- Подбор фрагмента текста — повышает точность поиска.
- Уточнение выбора полей (field selection refinement) — позволяет ограничить поиск определенными атрибутами данных.
- Оптимизация предварительной фильтрации (prefilter optimization) ускоряет поиск за счет исключения нерелевантных данных.
Кроме того, для масштабирования векторных баз данных применяют разделение на части больших объемов данных. Использование ANN ускоряет поиск, но требует мониторинга для предотвращения деградации качества.
Метрики оценки
Для оценки RAG используют различные метрики:
- Точность извлечения — показывает, насколько хорошо система находит релевантные документы.
- Релевантность ответа — оценивает соответствие ответа запросу.
- Измерение задержки
- Оптимизация стоимости.
Метрики извлечения включают:
- Precision (точность) — количество правильных документов, деленное на общее количество найденных,
- Recall (полнота) — количество правильных документов, деленное на общее количество релевантных в корпусе,
- F1 — среднее гармоническое между первыми двумя.
Для оценки качества генерации используются BLEU, ROUGE, METEOR – автоматизированные метрики для общей оценки, а также проверка фактов, соответствие контексту и наличие ссылок на источники.
Настройка мониторинга
Мониторинг включает в себя такие инструменты:
- отслеживание процента успешных запросов,
- оценка релевантности результатов,
- отслеживание времени ответа,
- анализ ошибок.
Для этого можно использовать инструменты, такие как Arize AI и Weights & Biases (платформы для мониторинга и оценки LLM и RAG приложений), а также пользовательские панели мониторинга для отслеживания задержки, качества вывода и статистики аннотаций.
Устранение неполадок
Устранение неполадок включает анализ различных уровней системы:
- проблемы с загрузкой данных,
- проблемы с индексацией,
- сбои извлечения,
- ошибки генерации промптов,
- проблемы с ответами LLM.
Пример: Если ответы стали менее точными, проверьте качество данных, настройки извлекателя и промпты.
Продвинутые техники RAG
Методика RAG постоянно развивается, предлагая новые способы повышения точности и эффективности. Рассмотрим передовые методы и перспективные направления.
Подходы к тонкой настройке
Тонкая настройка позволяет адаптировать компоненты RAG под конкретные задачи. Настройка извлечения улучшает способность извлекателя находить релевантную информацию. Для этого используют контрастное обучение (contrastive learning), обучая модель различать правильные и неправильные ответы. Важна разметка данных, чтобы предоставить модели примеры релевантных и нерелевантных документов.
Тонкая настройка LLM необходима, когда LLM недостаточно использует найденный контекст или слишком полагается на предварительное обучение. Методы, такие как RLHF (обучение с подкреплением на основе обратной связи от человека) и контролируемая тонкая настройка с обратной связью, позволяют улучшить качество генерации.
Преобразование запроса
Преобразование запроса улучшает точность поиска. Такие методы, как переписывание запроса, пошаговый промптинг и декомпозиция подзапросов, а также HyDE (Hypothetical Document Embeddings), генерируют псевдо-документы или переформулируют запросы для улучшения результатов поиска.
Другие методы, такие как Small2Big и фрагментация скользящим окном (sliding window chunking), являются стратегиями разбиения текста на фрагменты, которые помогают сохранить контекст и обеспечить поиск релевантной информации.
Часто задаваемые вопросы (FAQ)
Каковы основные преимущества использования RAG по сравнению с тонкой настройкой?
RAG позволяет получать доступ к актуальной информации без переобучения модели, что особенно важно, когда данные быстро устаревают. RAG снижает вероятность галлюцинаций (выдачи ложной информации), так как ответы основаны на извлеченном контенте. Обновление информации в RAG проще – достаточно обновить документы, а не параметры модели. В отличие от fine-tuning, который требует полной переподготовки модели, RAG обеспечивает гибкость и оперативность в работе с данными.
Как выбрать правильный размер фрагмента для моих документов?
Оптимальный размер фрагмента (chunk) зависит от плотности и структуры контента. Обычно рекомендуемый размер фрагмента составляет от 128 до 512 токенов, что примерно соответствует 96-384 словам (исходя из того, что 100 токенов ≈ 75 слов). Для некоторых задач и моделей могут использоваться фрагменты до 1000-2000 токенов для более широкого контекста.
Важно отметить, что 512 токенов часто является ограничением для моделей эмбеддингов, тогда как современные LLM могут обрабатывать значительно большие контекстные окна (например, до 10 миллионов токенов в некоторых случаях по состоянию на май 2025 года).
Нужно тестировать разные размеры и измерять точность извлечения, чтобы найти оптимальное значение для конкретного контента. Слишком маленькие фрагменты могут потерять контекст, а слишком большие – перегрузить LLM.
В чем разница между векторным поиском и гибридным поиском?
Векторный поиск понимает семантическое сходство, но может упускать конкретные ключевые слова. Ключевой поиск находит точные термины, но не учитывает семантические связи.
Гибридный поиск объединяет оба подхода. Его стоит использовать, когда важны названия продуктов, бренды или специфическая терминология. Гибридный поиск обеспечивает более сбалансированный и точный результат.
Как я могу уменьшить галлюцинации в ответах RAG?
Для снижения галлюцинаций в RAG необходимо внедрить атрибуцию источников и модели проверки фактов. Важно использовать продвинутые инструкции промптов, которые подчеркивают использование только предоставленного контекста. Также полезны проверки валидации после генерации. Модели обнаружения могут помечать или блокировать вероятные выдумки.
Каковы соображения о стоимости для реализаций RAG?
Затраты на RAG включают вычисление эмбеддингов, хранение в векторной базе данных, вызовы API LLM и инфраструктуру. Гибридный поиск может быть более ресурсоемким по сравнению с чисто векторным поиском, поскольку он объединяет несколько методов поиска (например, лексический и семантический) и требует дополнительных вычислений для объединения результатов. Оптимизация включает пакетную обработку, кэширование частых эмбеддингов и адаптивные интервалы обновления.

Оставить комментарий