Оглавление
Мультимодальный адаптивный промтинг (Multimodal Adaptive Prompting) – это продвинутая техника взаимодействия с современными AI-системами, позволяющая использовать не только текст, но и другие типы данных, такие как изображения, аудио и видео, для более точного и эффективного управления поведением искусственного интеллекта. В отличие от традиционных текстовых промптов, этот подход динамически подстраивается под различные входные данные, обеспечивая более релевантные и контекстуально-осмысленные ответы.
Введение в мультимодальный адаптивный промтинг
Представьте, что вы учите собаку командам. Сначала вы просто говорите «Сидеть!». Это как обычный текстовый промпт. Теперь представьте, что вы показываете жест рукой одновременно с командой. Это уже мультимодальный промт. Адаптивный элемент появляется, когда вы начинаете менять жесты и тон голоса в зависимости от настроения собаки, чтобы она лучше понимала, что от неё требуется.
В мире AI, мультимодальные большие языковые модели (MLLM) вроде GPT-5, Gemini 2.5 Pro и Claude 3.5 Sonnet способны обрабатывать различные типы данных. Мультимодальный промптинг использует эту способность, комбинируя, например, текстовые инструкции с визуальными примерами, чтобы добиться желаемого результата. Это особенно полезно в задачах, где контекст играет ключевую роль.
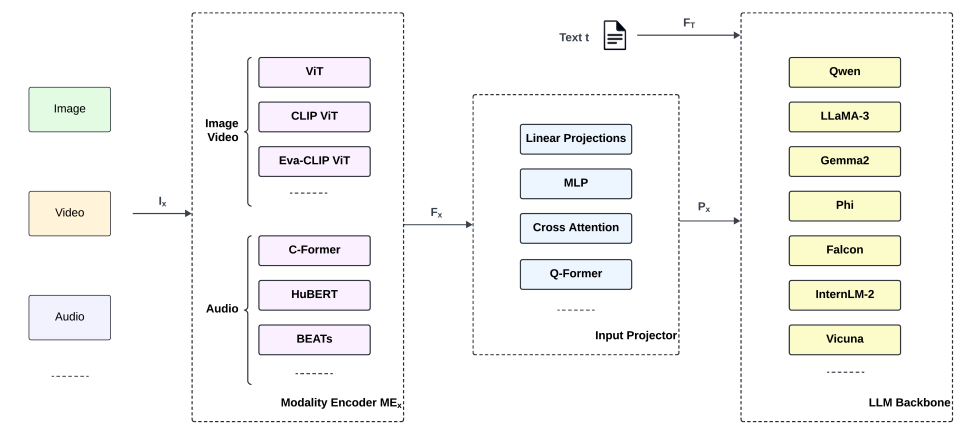
Источник: https://arxiv.org/pdf/2504.10179. Общий обзор типичного пайплайна MLLM. В начале несколько модальностей ввода (изображения, видео, аудио) обрабатываются специальными кодировщиками
Почему недостаточно просто давать AI текстовые инструкции? Дело в том, что мир сложен и многогранен. Иногда изображение говорит больше, чем тысяча слов. Адаптивный промтинг позволяет AI лучше понимать нюансы и контекст, что приводит к более точным и полезным ответам.
Исследования показывают, что структурированные промпты значительно повышают надежность AI. Например, в задачах генерации кода Few-Shot промтинг может достигать точности до 96.88% для больших MLLM.
Для задач мультимодального понимания и выравнивания Zero-Shot промтинг может обеспечивать релевантность ответов, близкую к 100% для больших и средних моделей. Однако стоит отметить, что более сложные стратегии, такие как Chain-of-Thought и Tree-of-Thought, могут увеличивать время ответа (иногда превышая 20 секунд для больших MLLM) и повышать уровень галлюцинаций, особенно в небольших моделях.
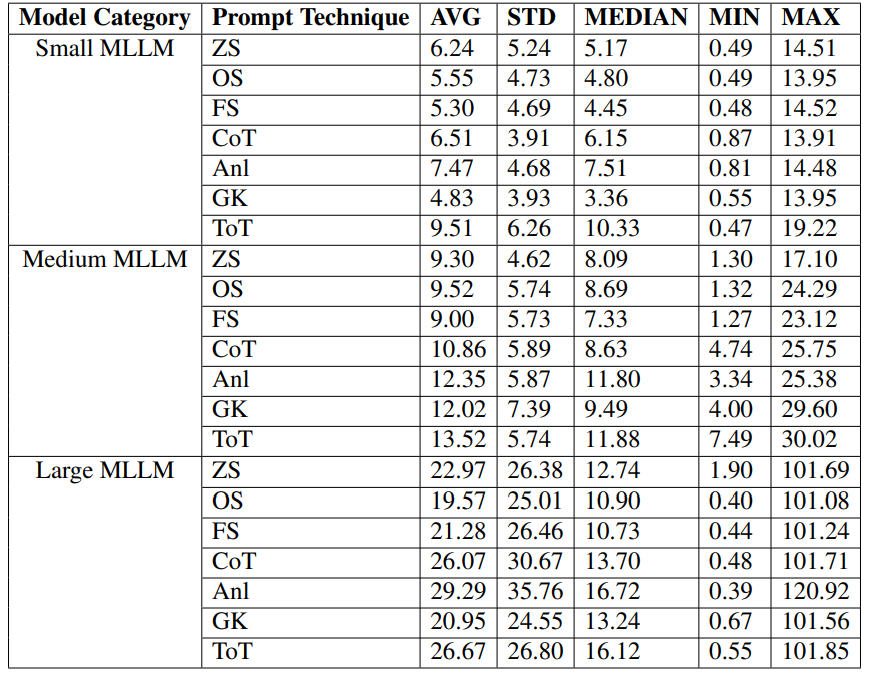
Источник: https://arxiv.org/pdf/2504.10179. Время ответа модели на запрос в зависимости от модели промптинга и размера MLLM
Это подчеркивает важность адаптивного выбора стратегии промптинга в зависимости от задачи и модели.
Фундаментальные техники промтинга
Для эффективного использования мультимодального адаптивного промтинга необходимо освоить базовые техники промтинга. Они станут фундаментом для более сложных и адаптивных подходов. Рассмотрим основные из них: Zero-Shot, Few-Shot, Role-Based промтинг и основы Chain-of-Thought.
Zero-Shot Prompting
Zero-Shot Prompting – это метод, при котором модель искусственного интеллекта выполняет задачу без предварительного обучения на примерах этой задачи. Вы просто даете модели инструкцию, и она пытается ее выполнить, опираясь на свои общие знания.
Пример:
Как образуется снег?В этом случае, модель должна использовать свои знания о физике и метеорологии, чтобы объяснить процесс образования снега.
Когда использовать:
- Когда у вас нет примеров для обучения модели.
- Когда задача достаточно простая и может быть решена на основе общих знаний.
- Для быстрой проверки возможностей модели.
Особенности:
- Простота реализации.
- Зависимость от общих знаний модели.
- Может давать неточные или неполные ответы для сложных задач.
Начните с Zero-Shot, чтобы оценить базовые возможности модели, прежде чем переходить к более сложным техникам.
Few-Shot Prompting
Few-Shot Prompting – это метод, при котором модели предоставляется небольшое количество примеров (обычно 2-5) выполнения задачи. Эти примеры помогают модели понять формат ввода и вывода, а также логику решения задачи.
Пример:
Вход: Яблоко
Выход: Фрукт
Вход: Морковь
Выход: Овощ
Вход: Банан
Выход: Фрукт
Вход: Огурец
Выход:В этом примере мы даем модели несколько примеров классификации фруктов и овощей. Модель должна понять закономерность и правильно классифицировать огурец.
Когда использовать:
- Когда Zero-Shot не дает достаточно точных результатов.
- Когда у вас есть небольшое количество примеров для обучения.
- Когда задача требует знания специфического формата или логики.
Особенности:
- Повышает точность по сравнению с Zero-Shot.
- Требует подготовки качественных примеров.
- Эффективность зависит от релевантности и разнообразия примеров.
Убедитесь, что ваши примеры четкие, последовательные и охватывают различные сценарии. Экспериментируйте с количеством примеров, чтобы найти оптимальный баланс. Важно, чтобы форматирование примеров было единообразным, например, использование XML-тегов, пробелов и переносов строк.
Role-Based Prompting
Role-Based Prompting – это метод, при котором модели назначается определенная роль или персона. Это помогает модели генерировать ответы, соответствующие знаниям, стилю и точке зрения этой роли.
Пример:
Ты – эксперт по блокчейну, объясняющий сложные концепции новичкам. Объясни, что такое Proof-of-Stake простыми словами.В этом примере мы просим модель выступить в роли эксперта по блокчейну. Это поможет ей сгенерировать более точный и понятный ответ.
Когда использовать:
- Когда вам нужен ответ с определенной точки зрения или в определенном стиле.
- Когда задача требует специальных знаний или опыта.
- Для создания более интересных и вовлекающих взаимодействий с моделью.
Особенности:
- Позволяет настраивать тон и стиль ответов.
- Требует четкого определения роли и ее характеристик.
- Эффективность зависит от того, насколько хорошо модель понимает заданную роль.
Четко определите роль, знания и стиль, которые вы хотите, чтобы модель использовала. Укажите, для какой аудитории предназначен ответ.
Chain-of-Thought Basics
Chain-of-Thought (CoT) – это метод, при котором модель побуждается к последовательному, пошаговому мышлению. Вместо того, чтобы сразу выдавать ответ, модель сначала объясняет свой ход мыслей.
Пример:
Вопрос: В парке было 15 деревьев. Дровосеки срубили 7 деревьев. Сколько деревьев осталось в парке?
Давайте подумаем шаг за шагом.Модель должна сначала объяснить, что нужно вычесть количество срубленных деревьев из общего количества, а затем выдать ответ.
Когда использовать:
- Когда задача требует логического мышления и рассуждений.
- Когда вам нужно понять, как модель пришла к своему ответу.
- Для повышения точности ответов в сложных задачах.
Особенности:
- Повышает прозрачность процесса принятия решений моделью.
- Требует от модели способности к логическому мышлению.
- Может увеличить время ответа.
Побуждайте модель к объяснению каждого шага своего рассуждения. Используйте фразы, такие как «Давайте подумаем шаг за шагом» или «Объясните свой ход мыслей».
Вывод: Освоение этих базовых техник промтинга позволит вам более эффективно взаимодействовать с AI-моделями и получать более точные и релевантные ответы. Экспериментируйте с различными подходами и комбинациями, чтобы найти оптимальные решения для ваших задач. Не забывайте, что ключ к успеху – это четкое понимание возможностей и ограничений каждой техники.
Продвинутые методы адаптивного промптинга
В предыдущих разделах мы рассмотрели основы мультимодального адаптивного промптинга и базовые техники, такие как Zero-Shot, Few-Shot, Role-Based промптинг и Chain-of-Thought. Теперь углубимся в более продвинутые адаптивные методы, позволяющие AI-системам справляться со сложными мультимодальными задачами, требующими структурированного мышления и адаптации к контексту.
Древовидное рассуждение (ToT)
Tree-of-Thought (ToT) – это метод рассуждения, при котором модель исследует различные пути решения задачи, как ветви дерева. Вместо линейной цепочки мыслей, ToT позволяет модели генерировать несколько вариантов решения на каждом шагу, оценивать их и выбирать наиболее перспективные для дальнейшего развития.
Пример:
Представьте, что вы планируете путешествие. Вместо того, чтобы сразу выбрать один маршрут, вы рассматриваете несколько вариантов: поехать на поезде, полететь на самолете или арендовать машину. Для каждого варианта вы оцениваете плюсы и минусы (стоимость, время, удобство) и выбираете наиболее подходящий.
В ИИ это выглядит так:
- Генерация мыслей: Модель генерирует несколько возможных шагов решения задачи.
- Оценка мыслей: Модель оценивает каждую мысль на основе заданных критериев (например, вероятность успеха, соответствие контексту).
- Выбор мыслей: Модель выбирает наиболее перспективные мысли для дальнейшего развития.
- Повторение: Процесс повторяется до достижения конечного решения.
Когда использовать:
- Для решения сложных задач, требующих исследования нескольких вариантов.
- Когда необходимо учитывать различные факторы и ограничения.
- Для повышения креативности и генерации нестандартных решений.
Пример промта (упрощенный):
Задача: Напиши короткий рассказ о коте, который умеет говорить.
Шаг 1: Какие могут быть варианты начала рассказа? (Перечисли 3 варианта)
Шаг 2: Оцени каждый вариант по шкале от 1 до 5 (1 - плохо, 5 - отлично).
Шаг 3: Выбери лучший вариант и продолжи рассказ.
(Повторяй шаги 1-3, пока рассказ не будет закончен)Особенности:
- Позволяет модели исследовать больше вариантов, чем Chain-of-Thought.
- Требует разработки эффективных критериев оценки мыслей.
- Может быть вычислительно затратным и увеличивать время ответа.
Четко определите критерии оценки мыслей. Используйте эвристики (правила), чтобы сократить пространство поиска.
Генерация, дополненная поиском (RAG)
Retrieval Augmented Generation (RAG) – это метод, при котором модель использует внешние источники знаний для генерации ответов. Вместо того, чтобы полагаться только на свои внутренние знания, модель ищет релевантную информацию в базах данных, документах или интернете и использует ее для формирования ответа.
Пример:
Представьте, что вы пишете статью о Второй мировой войне. Вместо того, чтобы полагаться только на свою память, вы ищете информацию в книгах, статьях и онлайн-источниках.
В ИИ это выглядит так:
- Поиск информации: Модель получает запрос и ищет релевантную информацию во внешних источниках.
- Извлечение информации: Модель извлекает наиболее релевантные фрагменты информации.
- Генерация ответа: Модель использует извлеченную информацию для генерации ответа.
Когда использовать:
- Когда задача требует доступа к актуальной или специализированной информации.
- Когда необходимо повысить точность и достоверность ответов, снизить галлюцинаций.
- Для решения задач, требующих знаний, которые не были включены в обучающий набор модели.
Пример: Использование RAG для ответа на вопрос о последних новостях:
- Модель получает вопрос: «Какие последние новости о выборах в США?»
- Модель ищет информацию в новостных агрегаторах и базах данных.
- Модель извлекает релевантные статьи и отчеты.
- Модель генерирует ответ, основанный на извлеченной информации.
Особенности:
- Позволяет модели получать доступ к актуальной информации.
- Повышает точность и достоверность ответов.
- Требует разработки эффективных методов поиска и извлечения информации.
- В 2025 году RAG активно развивается, включая адаптивные механизмы извлечения, которые динамически подстраиваются под намерение пользователя и сложность запроса.
Используйте векторные базы данных для быстрого поиска релевантной информации. Рассмотрите возможность использования графов знаний (knowledge graphs) для структурирования информации. Применяйте гибридные методы извлечения (sparse + dense embeddings) с переранжированием для оптимизации релевантности и эффективности.
Self-Consistency и Reflection
Self-Consistency – это метод, при котором модель генерирует несколько вариантов ответа на один и тот же вопрос и выбирает наиболее распространенный или логически обоснованный. Reflection – это процесс самооценки и улучшения, при котором модель анализирует свои ошибки и пытается их исправить.
Пример:
Представьте, что вы решаете сложную математическую задачу. Вы решаете ее несколько раз разными способами и сравниваете результаты. Если результаты совпадают, вы уверены в правильности ответа. Если результаты различаются, вы анализируете свои решения и пытаетесь найти ошибку.
В ИИ это выглядит так:
- Генерация ответов: Модель генерирует несколько вариантов ответа на один и тот же вопрос.
- Оценка ответов: Модель оценивает каждый ответ на основе заданных критериев (например, логичность, соответствие контексту).
- Выбор ответа: Модель выбирает наиболее распространенный или логически обоснованный ответ.
- Рефлексия: Модель анализирует свои ошибки и пытается их исправить.
Когда использовать:
- Для повышения точности и надежности ответов.
- Для выявления и исправления ошибок в рассуждениях модели.
- Для улучшения способности модели к самообучению.
Особенности:
- Повышает устойчивость к случайным ошибкам.
- Требует разработки эффективных методов оценки ответов.
- Может быть вычислительно затратным, но методы вроде Confidence-Informed Self-Consistency (CISC) помогают снизить количество необходимых путей рассуждения.
Используйте различные методы генерации ответов (например, разные промпты, разные модели). Включите в промпт запрос на самооценку: «Оцени, насколько ты уверен в своем ответе по шкале от 1 до 10».
Стратегии мультимодальной интеграции
Мультимодальная интеграция – это процесс объединения различных типов данных (текст, изображения, аудио, видео) для решения задачи. Существует несколько стратегий мультимодальной интеграции:
- Ранняя интеграция: Объединение данных на ранних этапах обработки. Например, объединение текстовых и визуальных признаков перед подачей в модель.
- Поздняя интеграция: Объединение результатов обработки различных модальностей на поздних этапах. Например, объединение текстовых и визуальных предсказаний.
- Промежуточная интеграция: Объединение данных на промежуточных этапах обработки. Например, использование текстовых признаков для управления вниманием модели при обработке изображений.
Пример:
Представьте, что вы хотите создать систему, которая описывает содержание видеороликов. Вы можете использовать раннюю интеграцию, объединив аудио- и видеоданные перед подачей в модель. Или вы можете использовать позднюю интеграцию, объединив текстовые описания, сгенерированные на основе аудио, с визуальными описаниями, сгенерированными на основе видео.
Когда использовать:
- Когда задача требует обработки нескольких типов данных.
- Когда необходимо учитывать взаимосвязи между различными модальностями.
- Для повышения точности и полноты ответов.
Пример: Использование Google AI Studio для создания мультимодального промпта:
- Загрузите изображение и введите текстовый запрос: «Опиши, что изображено на картинке».
- Используйте возможности Google AI Studio, который предоставляет удобную среду для экспериментов с моделями Gemini, поддерживающими мультимодальный ввод (текст, изображения, аудио, видео).
- Оцените результаты и настройте промпт для достижения желаемого результата.
Особенности:
- Позволяет модели учитывать различные аспекты задачи.
- Требует разработки эффективных методов объединения данных.
- Может быть сложным в реализации.
Совет: Экспериментируйте с различными стратегиями интеграции, чтобы найти оптимальный подход для вашей задачи. Используйте механизмы внимания, чтобы модель могла фокусироваться на наиболее релевантных частях данных.
Вывод: Продвинутые методы адаптивного промтинга позволяют создавать более мощные и гибкие AI-системы, способные решать сложные мультимодальные задачи. Выбор конкретного метода зависит от задачи, доступных ресурсов и желаемого уровня производительности. Не бойтесь экспериментировать и комбинировать различные подходы, чтобы найти оптимальное решение для ваших нужд.
Практические шаблоны и лучшие практики
Эффективное использование мультимодального адаптивного промтинга требует не только понимания теории, но и практических навыков. В этом разделе мы рассмотрим готовые шаблоны и проверенные стратегии, которые помогут вам внедрить этот подход в различных сценариях.
Структуры шаблонов
Модульный шаблон промпта позволяет гибко настраивать взаимодействие с AI. Он состоит из нескольких ключевых компонентов:
- РОЛЬ: Определяет роль, которую должна играть модель. Например, «Ты — опытный врач-радиолог».
- КОНТЕКСТ: Предоставляет дополнительную информацию о задаче. Например, «Пациент жалуется на боли в груди».
- ПРИМЕРЫ: Демонстрируют желаемый формат ответа. Например, «Рентгеновский снимок показывает признаки пневмонии. Рекомендовано: курс антибиотиков».
- ЗАДАЧА: Четко формулирует вопрос или инструкцию. Например, «Проанализируй рентгеновский снимок и поставь диагноз».
- ФОРМАТ ВЫВОДА: Указывает, в каком формате должен быть представлен ответ (JSON, Markdown, список).
Пример шаблона:
[РОЛЬ]: Ты - эксперт по машинному обучению.
[КОНТЕКСТ]: Пользователь хочет обучить модель классификации изображений.
[ПРИМЕРЫ]:
Вход: Изображение кошки. Выход: Кошка.
Вход: Изображение собаки. Выход: Собака.
[ЗАДАЧА]: Объясни, как подготовить данные для обучения модели.
[ФОРМАТ ВЫВОДА]: Нумерованный список шагов.Адаптируйте этот шаблон под свои нужды. Меняйте порядок компонентов, добавляйте новые, удаляйте ненужные. Главное – сохраняйте структуру и четкость.
Оптимизация контекста
Оптимизация контекста – это процесс предоставления модели наиболее релевантной информации для решения задачи. Чем лучше контекст, тем точнее и полезнее будет ответ.
- Используйте ключевые слова: Выделите важные термины и понятия, чтобы модель могла быстро понять суть задачи.
- Предоставляйте релевантные примеры: Примеры должны быть максимально похожи на задачу, которую нужно решить.
- Укажите ограничения: Ограничения помогают модели сузить область поиска и избежать нежелательных ответов.
Пример: Вместо «Опиши эту картинку» используйте «Опиши эту картинку с точки зрения искусствоведа, обращая внимание на композицию, цвет и технику».
Важно: Не перегружайте контекст лишной информацией. Модель должна получить только то, что необходимо для решения задачи.
Эффективность использования токенов
Токены – это строительные блоки, из которых состоит текст. Каждый промпт имеет ограничение по количеству токенов. Превышение этого лимита может привести к ошибкам или неполным ответам.
- Будьте лаконичны: Используйте короткие и понятные фразы.
- Удалите лишние слова: Избегайте повторений и вводных конструкций.
- Используйте сокращения: Заменяйте длинные фразы общепринятыми сокращениями (например, «и т.д.» вместо «и так далее»).
Помните: 100 токенов примерно соответствуют 60-80 словам. Поэтому проверяйте длину промпта перед отправкой. Многие платформы предоставляют инструменты для подсчета токенов.
Смягчение предвзятости
AI-модели могут воспроизводить предвзятости, присутствующие в обучающих данных. Важно принимать меры для смягчения этих предвзятостей.
- Перефразируйте вопросы: Избегайте формулировок, которые могут усилить предвзятости.
- Используйте разнообразные примеры: Включайте примеры, представляющие различные точки зрения и демографические группы.
- Структурируйте промпт: Четкая структура помогает модели сосредоточиться на фактах, а не на предубеждениях.
Пример: Вместо «Напиши историю об успешном бизнесмене» используйте «Напиши историю об успешном предпринимателе, независимо от пола, расы и происхождения».
Настраивайте дополнительные параметры: температуру, top_p и стоп-последовательности. Информация о них, к примеру, есть в документации OpenAI по параметрам API.
Вывод: экспериментируйте с различными шаблонами и техниками, чтобы найти оптимальный подход для ваших задач. Помните, что мультимодальный адаптивный промтинг – это итеративный процесс. Анализируйте результаты, вносите изменения и продолжайте совершенствовать свои промпты.
Инструменты и фреймворки реализации
Для создания и развертывания систем мультимодального адаптивного промтинга необходимы подходящие инструменты и фреймворки. Они упрощают разработку, оценку и интеграцию этих систем в реальные приложения. Рассмотрим основные категории инструментов и дадим рекомендации по их использованию.
Фреймворки разработки
Фреймворки разработки предоставляют строительные блоки для создания сложных систем промтинга. Они предлагают готовые компоненты для работы с моделями, управления данными и реализации логики адаптации.
- Langchain: Мощный фреймворк для создания цепочек и агентов, способных взаимодействовать с внешними источниками данных, включая веб-страницы. Langchain позволяет создавать сложные сценарии, в которых модель динамически адаптирует свои действия в зависимости от полученной информации. Например, можно создать агента, который ищет информацию в интернете, анализирует ее и генерирует ответ на вопрос пользователя.
- Semantic Kernel: Фреймворк от Microsoft, ориентированный на разработку скиллов для ИИ-агентов. Упрощает создание планов и индексирование данных, что позволяет агентам эффективно решать сложные задачи. Он хорошо подходит для создания систем, требующих структурированного подхода к обработке информации.
- Guidance: Язык шаблонов, который позволяет контролировать процесс генерации текста моделью. Позволяет задавать ограничения, определять структуру ответа и вставлять код Python для динамической генерации контента. Это полезно для создания систем, требующих высокой степени контроля над выходом модели.
- LlamaIndex: Фреймворк для управления данными в RAG-системах (Retrieval Augmented Generation). LlamaIndex позволяет индексировать и запрашивать данные из различных источников, что упрощает создание систем, использующих внешние знания для генерации ответов.
- FastRAG: Расширенная реализация RAG, предлагающая дополнительные возможности для управления контекстом и оптимизации поиска информации. Может быть полезен для создания систем, требующих высокой производительности и точности.
- Auto-GPT и AutoGen: Фреймворки для разработки автономных агентов, способных самостоятельно решать задачи. AutoGen позволяет создавать системы, которые могут планировать свои действия, взаимодействовать с внешними инструментами и адаптироваться к изменяющимся условиям.
Пример использования Langchain:
from langchain_openai import OpenAI
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
llm = OpenAI(temperature=0.9)
prompt = PromptTemplate(
input_variables=["product"],
template="What is a good name for a company that makes {product}?",
)
chain = LLMChain(llm=llm, prompt=prompt)
print(chain.run("colorful socks"))Этот код создает цепочку, которая генерирует название для компании, производящей «разноцветные носки».
Инструменты оценки
Оценка качества промптов и сгенерированных ответов – важный этап разработки. Инструменты оценки позволяют автоматизировать этот процесс и получить объективные метрики.
Например,Promptfoo — инструмент для автоматизированной оценки промптов. Позволяет сравнивать различные промпты, оценивать их производительность на различных наборах данных и выявлять проблемы.
Ресурсы для оценки MLLM (Multimodal Large Language Models) включают различные инструменты и наборы данных, предлагающие комплексный подход к оценке, учитывающий различные аспекты качества, такие как точность, релевантность и согласованность.
Платформы развертывания
Платформы развертывания позволяют интегрировать системы промтинга в реальные приложения и сделать их доступными для пользователей.
- Google AI Studio: Платформа для разработки и развертывания AI-моделей, включая мультимодальные. Удобный интерфейс для создания промптов, экспериментов с моделями и развертывания готовых решений.
- Hugging Face Transformers: Библиотека для работы с трансформерными моделями, включая модели для мультимодального промтинга. Инструменты для загрузки, настройки и развертывания моделей на различных платформах.
Выбор подходящего инструмента или фреймворка зависит от конкретной задачи и требований к системе. Для начинающих рекомендуется начать с простых инструментов, таких как Google AI Studio или Langchain. Для более сложных задач можно использовать Semantic Kernel, LlamaIndex или Auto-GPT. Важно помнить, что разработка систем мультимодального адаптивного промтинга – это итеративный процесс, требующий экспериментов и постоянной оценки результатов.

Оставить комментарий