Оглавление
- Введение в технику Least-to-Most промптинга
- Теоретические основы и образовательные истоки
- Как работает техника Least-to-Most промптинга
- Исследовательские данные и эффективность
- Пошаговое руководство по реализации
- Практические примеры и варианты использования
- Лучшие практики и оптимизация
- Инструменты и технические соображения
- FAQ: Часто задаваемые вопросы
- Источники и ссылки
Введение в технику Least-to-Most промптинга
Least-to-Most (LtM) — это техника составления промптов (запросов к ИИ), при которой сложная задача разбивается на последовательность более простых подзадач [1]. Сначала ИИ решает самую простую часть, затем использует этот результат для решения следующей, чуть более сложной, и так до достижения конечной цели.
Представьте, что вы учите ребёнка собирать сложный конструктор. Вы не дадите все детали сразу, а сначала покажете, как соединить два элемента, потом — как собрать базовый модуль, и только затем перейдёте к полной сборке. LtM работает по такому же принципу, но для ИИ.
Практический пример:
- Ситуация: Нужно попросить ИИ написать техническое руководство по настройке VPN.
- Что сделать: Разбить запрос на шаги: (1) «Перечисли основные этапы настройки VPN» → (2) «Для каждого этапа напиши пошаговые инструкции» → (3) «Объедини всё в структурированное руководство».
- Ожидаемый результат: Вместо хаотичного или поверхностного ответа вы получите логичный, детализированный документ.
Эта техника особенно полезна для задач, требующих многошагового рассуждения — анализа данных, программирования или сложных текстовых преобразований.
Исторические основы из образовательной психологии
LtM не был придуман для ИИ — он существует дольше и пришёл из образовательной психологии. В 1970-х годах исследователи систематизировали концепцию «обучения с поддержкой» (scaffolding). Её суть: обучать сложным навыкам постепенно, обеспечивая поддержку на каждом этапе, которую затем поэтапно убирают [2].
Например, при обучении математике ученику сначала показывают, как решить простое уравнение, затем — как применить этот навык в задаче с условием, и только потом дают комплексные задачи. Это снижает когнитивную нагрузку и повышает успешность.
Почему это перенесли в ИИ?
Большие языковые модели (LLM), как и люди, лучше справляются со сложными задачами, когда их ведут шаг за шагом. Прямой запрос «напиши бизнес-план» выдаст общий или шаблонный ответ. Но если разбить его на подзадачи — анализ рынка, финансовые расчёты, стратегия продвижения — ИИ выдаёт более качественный и конкретный результат.
LtM — это не «хак» для ИИ, а адаптация проверенного образовательного подхода. И он эффективен, потому что соответствует естественным принципам обучения.
Почему LtM важен в промпт-инжиниринге
LtM — не единственная методика промптинга. Сравним ее с другими популярными техниками:
1. Zero-shot промптинг (прямой запрос без примеров) [9]
Пример: «Напиши код для сортировки списка на Python».
Результат: ИИ, скорее всего, выдаст совсем базовое или неполное решение. Этот метод подходит только для простых задач.
2. Chain-of-Thought (CoT, цепочка рассуждения)
Пример: «Объясни по шагам, как решить уравнение 2x + 5 = 15. Сначала выдели переменную, затем вычисли значение».
Результат: лучше zero-shot, но потребует от вас заранее прописать шаги рассуждения [3]. Если шаги выбраны неверно, ИИ может пойти по неправильному пути.
Чем LtM лучше:
- Не требует от вас точного знания всех промежуточных шагов — вы задаёте последовательность подзадач, а ИИ строит рассуждения сам.
- Подходит для задач, где цель ясна, но путь к ней неочевиден.
Практические преимущества:
- Выше точность на задачах с многошаговой логикой и вычислениями по сравнению с одношаговыми запросами.
- Меньше итераций: ИИ реже переспрашивает вас, в решение нужно вносить меньше исправлений.
- Универсальность: применимо к коду, текстам, анализу данных, планированию.
Пример для кода:
- Ситуация: Нужно написать функцию, которая фильтрует список чисел по чётности и сортирует результат.
- LtM-подход:
- «Напиши код для фильтрации чётных чисел из списка [1, 2, 3, 4, 5]»
- «Добавь сортировку результата по возрастанию»
- «Объедини всё в одну функцию с аргументом для входного списка»
- Результат: Чистый, работающий код без лишних шагов.
Когда есть смысл использовать LtM:
- Для сложных или многошаговых задач.
- Когда прямой запрос даёт поверхностный ответ.
- Если вы понимаете цель, но не уверены в точном пути.
Что важно запомнить: При сложных запросах разбивайте задачу на 2–3 простые подзадачи, постепенно усложняя.
Теоретические основы и образовательные истоки
Метод Least-to-Most — это проверенный педагогический подход. Он опирается на идею «обучения с поддержкой» (scaffolding), широко описанную в исследованиях 1970-х годов [2]. Идея в том, чтобы разбить сложную задачу на последовательные шаги, предоставляя ровно столько помощи, сколько нужно для продвижения вперёд, и постепенно убирая её по мере роста компетенций.
Этот принцип эффективен, потому что учитывает ограничения рабочей памяти и когнитивной нагрузки: дозируя сложность, мы снижаем ошибки и улучшаем усвоение материала.
Когнитивная наука обучения с поддержкой
В основе LtM лежит теория когнитивной нагрузки [4], разработанная Джоном Свеллером еще в 80-е [5]. Эффективное обучение минимизирует непродуктивную нагрузку на рабочую память и направляет ресурсы на усвоение сути.
Обучение с поддержкой работает по трём ключевым механизмам:
- Фрагментация. Сложная задача делится на более мелкие, логические подзадачи.
- Последовательное освоение. Переход к следующему шагу только после освоения текущего.
- Постепенное снятие поддержки. Подсказки убираются по мере роста мастерства.
Пример: нельзя учить алгебре, не освоив арифметику: сложение → переменные → уравнения.
Практический совет: применяя LtM к ИИ, начинайте с формулировок, активирующих базовые концепции, и лишь затем ведите модель к более сложным выводам.
Сравнительный анализ: LtM и MTL
В образовании используется и противоположная иерархия подсказок — «от сложного к простому» (Most-to-Least, MTL). Сначала демонстрируется полное выполнение, затем поддержка уменьшается [12]. У каждого подхода своя ниша: MTL часто применяют для минимизации ошибок на старте, LtM — для поэтапного формирования новых навыков. Оптимальный выбор зависит от исходной подготовки и цели обучения.
Перенос образовательных принципов на системы ИИ
Большие языковые модели (LLM) имеют «контекстное окно» (context window), играющее роль рабочей памяти. Один сложный, многосоставной запрос часто перегружает эту «память», что ведёт к поверхностным ответам. LtM снижает перегрузку за счёт пошагового решения.
Как это выглядит на практике:
- Не просите ИИ сразу «написать бизнес-план».
- Разбейте задачу на шаги.
- Шаг 1: «Перечисли ключевые разделы стандартного бизнес-плана для IT-стартапа».
- Шаг 2: «По списку подробно опиши, что включить в раздел «Анализ рынка»».
- Шаг 3: «Используя предыдущие ответы, составь краткий 3-летний финансовый прогноз».
Каждый ответ служит опорой для следующего.
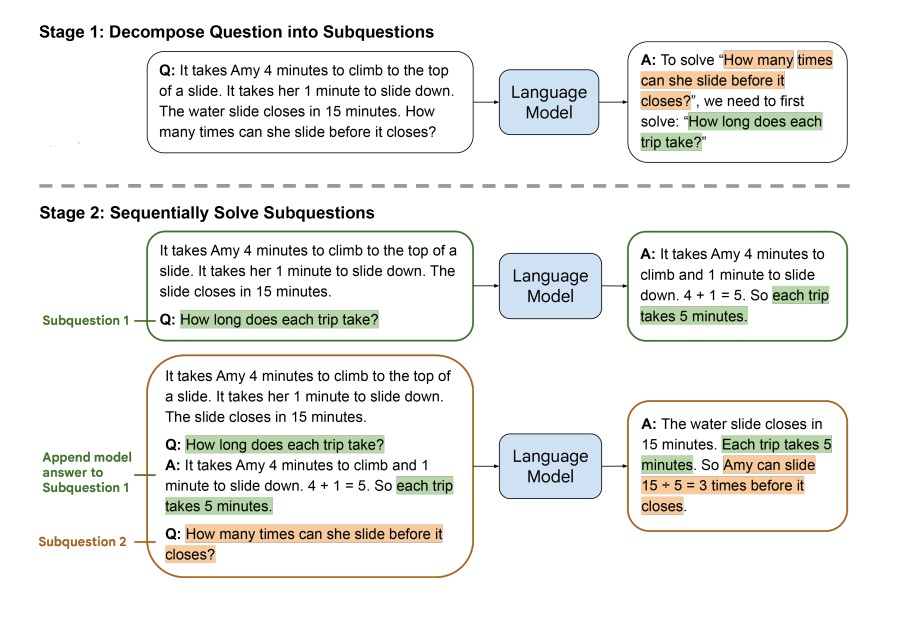
Источник: https://arxiv.org/pdf/2205.10625. Решение математической задачи по принципу «от наименьшего к наибольшему» в два этапа: (1) разложение задачи на подзадачи и (2) последовательное решение подзадач.
Пример перевода принципа в инструкцию для ИИ:
- Ситуация: нужно проанализировать длинный юридический документ и выделить риски.
- LtM-подход:
- «Суммаризируй документ в 5 ключевых пунктов».
- «Для каждого пункта оцени наличие юридических рисков (да/нет)».
- «Подробно опиши риски и предложи меры по их смягчению».
- Результат: не список разрозненных фактов, а связный, глубокий анализ.
Как работает техника Least-to-Most промптинга
LtM — это метод общения с ИИ, при котором сложный запрос разбивается на цепочку простых шагов. При поэтапном решении каждая следующая задача учитывает результаты предыдущих шагов, что повышает точность.
Визуально это «лестница»: от простого к сложному; ответы предыдущих шагов — опора для следующего.
Этап 1: Декомпозиция проблемы
Разделите главную задачу на более мелкие, логически связанные подзадачи так, чтобы каждая следующая ступень естественно вытекала из предыдущей:
- Сначала — список ключевых шагов.
- Затем — уточнение каждого шага.
- В конце — сборка в структурированный результат.
Практический совет: начните с вопроса «Что нужно знать, чтобы решить задачу?».
Пример разложения для урока по ИИ:
- Шаг 1: Темы (что такое ИИ, примеры, этика).
- Шаг 2: Краткие объяснения «для начинающих».
- Шаг 3: Практические задания/вопросы.
- Шаг 4: Структура «теория — практика — итоги».
Этап 2: Последовательное решение
Выполняйте каждую подзадачу по очереди, ссылаясь на предыдущие ответы как на контекст.
Пример для парсинга сайта:
- Сначала: «какие библиотеки Python подходят?» (requests, BeautifulSoup).
- Затем: «как получить HTML с requests?» (пример кода).
- Потом: «как извлечь заголовки в BeautifulSoup?».
- Наконец: «объедини в полный скрипт».
Практический совет: явно ссылайтесь на предыдущие ответы («используя библиотеки выше…»).
Этап 3: Синтез решения
Объедините результаты шагов в финальный ответ: структурируйте, уберите повторения, выделите главное.
Пример для бизнеса:
- После анализа рынка и конкурентов: «Составь roadmap запуска продукта с приоритетами и сроками».
Как сохранить контекст
Контекст — ключ к LtM. Учитывайте ограничение длины контекста (обычно 4K–32K токенов).
- Ссылайтесь на предыдущие ответы («используя данные шага 2…»).
- Повторяйте ключевые данные кратко.
- Резюмируйте длинные цепочки перед продолжением.
Пример: «Для Греции из твоего списка дай маршрут на 7 дней; добавь подсказки по бюджету из предыдущего ответа».
Практика: если модель «забыла» данные — шаг назад, короткое резюме и дальше. Для очень длинных задач используйте модели с большим контекстом.
Исследовательские данные и эффективность
LtM подтверждён рядом работ и испытан на бенчмарках.
Академические исследования
Работы 2022 года показали, что поэтапное разбиение сложных задач помогает моделям вроде PaLM и GPT-3 лучше решать задачи, требующие многошаговых рассуждений [8]. Базовая идея — декомпозиция и последовательное решение подзадач.
Метрики производительности и бенчмарки
Эффективность LtM широко анализируется на наборах GSM8K (арифметические задачи) [6] и BIG-Bench Hard [7]. Поэтапные подходы, как правило, улучшают качество решения задач, где требуется последовательное рассуждение.
Важно: величина эффекта зависит от модели, формулировки промпта и конкретной задачи.
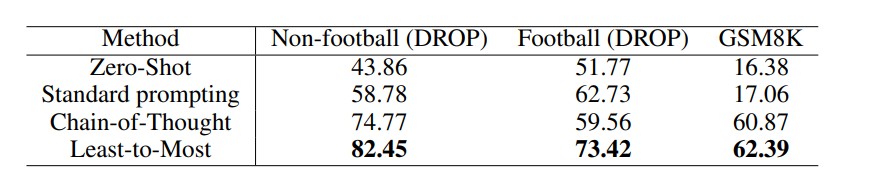
Источник: https://arxiv.org/pdf/2205.10625. Точность (%) различных методов подсказки в GSM8K и DROP. Базовая языковая модель — code-davinci-002.
Сравнительный анализ с другими техниками
LtM часто сравнивают с Zero-Shot и Few-Shot.
Иллюстративная таблица:
| Метод запроса | Точность | Снижение ошибок | Подходит для задач |
|---|---|---|---|
| Zero-Shot | Зависит от задачи | — | Простые запросы |
| Few-Shot | Выше при наличии хороших примеров | Умеренное | Умеренно сложные |
| Least-to-Most | Выше на задачах с многошаговой логикой | Выше за счёт декомпозиции | Сложные, многошаговые |
Ограничение: Few-Shot может быть быстрее для простых задач, где не требуется глубокая декомпозиция. Для запроса «Переведи предложение на французский» LtM будет избыточной.
Совет: если задача включает несколько этапов (анализ данных, планирование проекта), начинайте с LtM; для простых вопросов используйте Zero-Shot или Few-Shot, чтобы сэкономить время.
Ограничения и крайние случаи
Несмотря на эффективность, LtM подходит не для всех сценариев:
- Творческие задачи: Может давать формализованные результаты — полезно комбинировать с Few-Shot.
- Очень простые запросы: LtM избыточен.
- Ресурсоёмкость: Требует больше шагов и токенов.
- Зависимость от модели: Наибольшая отдача — на более сильных моделях (GPT-5, PaLM).
Практический шаг: Если вы работаете над проектом с анализом данных или программированием, примените LtM к самым сложным частям и сравните результат с обычными запросами.
Пошаговое руководство по реализации
Структура шаблона промпта
Базовый шаблон состоит из трёх компонентов:
- Декомпозиция — разбиваем сложную задачу на подзадачи
- Последовательное решение — обрабатываем каждую подзадачу отдельно
- Синтез — объединяем результаты в окончательный ответ
Пример шаблона для текстовых задач:
Шаг 1: Разбей задачу "{основная задача}" на последовательные подзадачи
Шаг 2: Реши первую подзадачу: {подзадача 1}
Шаг 3: Используя результат, реши: {подзадача 2}
Шаг 4: Объедини решения в окончательный ответДля программирования используйте структуру с явным указанием контекста:
# Шаг 1: Декомпозиция проблемы
decomposition_prompt = """
Разбейте задачу на логические шаги:
Задача: {ваша_задача}
"""
# Шаг 2: Последовательное выполнение
step1\_prompt = """
Используя предыдущий контекст, выполни:
{шаг\_1}
"""
# Шаг 3: Синтез результатов
synthesis\_prompt = """
Объедини следующие результаты:
{результат\_1}
{результат\_2}
В окончательный ответ:
"""Практическое правило: начинайте с самого простого шага и постепенно увеличивайте сложность. Если модель ошибается на раннем этапе — вернитесь и упростите формулировку.
Эффективная декомпозиция проблемы
Декомпозиция — ключевой навык для LtM. Хорошее разбиение напоминает строительные блоки: каждый элемент самостоятелен, но логически связан с другими.
Стратегии декомпозиции по типу задачи:
- Аналитические (анализ текста, данных): «извлечение фактов» → «группировка» → «вывод»
- Творческие (контент): «тема» → «структура» → «написание разделов» → «редактирование»
- Вычислительные: «переменные» → «формула» → «расчёт» → «проверка»
Техники разбиения:
- Временная последовательность — для процессов с естественным порядком шагов
- Иерархия — от общего к частному или наоборот
- По компонентам — разделение на независимые модули
Пример для бизнес-отчёта:
Подзадача 1: Выдели ключевые метрики (доход, расходы, прибыль)
Подзадача 2: Определи тренды за последний квартал
Подзадача 3: Сравни с прошлым годом
Подзадача 4: Сформулируй выводы о состоянии бизнесаОшибка новичков: шаги слишком мелкие/крупные. Оптимальный размер — 1-3 предложения или логический блок кода.
Стратегии последовательности
Правильная последовательность определяет успех LtM.
Типы последовательностей:
Линейная (самая распространённая):
A → B → C → РезультатПараллельная с последующим синтезом:
→ B →
A → D → Результат
→ C →Итеративная:
A → B → Проверка → (при необходимости) A' → B'Пример последовательности для подготовки email:
Шаг 1: Определи цель письма
Шаг 2: Составь список ключевых пунктов
Шаг 3: Сгруппируй пункты в абзацы
Шаг 4: Напиши черновик с нужным тоном
Шаг 5: Проверь на ясность и ошибкиПроверка цепочки: «Можно ли выполнить шаг N без результатов шага N-1?» Если да — пересмотрите порядок.
Техники синтеза
Синтез — объединение частичных решений в целостный ответ.
Методы:
Конкатенация: Ответ = Решение_1 + Решение_2 + Решение_3
Резюмирующий синтез: Итог = Идея(1) + Факт(2) + Вывод(3)
Структурный синтез: {"Введение": 1, "Основная часть": [2,3], "Заключение": 4}
Пример:
Дано:
1) Рынок +20% год-к-году
2) 5 новых конкурентов
3) Сдвиг к онлайн-покупкам
Синтез: Рынок растёт, но усиливается конкуренция; фокус — онлайн-каналы.Правило: явно просите модель «объединить результаты предыдущих шагов».
Распространенные проблемы реализации
Есть несколько распространенных проблем:
- Накопление ошибок: когда ранняя ошибка тянется дальше. Решение: добавьте проверочные шаги и валидацию
- Несовместимость форматов. Решение: задавайте формат вывода (JSON-схема, список и т.п.)
- Потеря контекста. Решение: ограничивайте цепочки 5-7 шагами, делайте краткие резюме, явно ссылайтесь на ключевые данные
Универсальное правило: если цепочка не работает — упростите самый проблемный шаг.
Практические примеры и варианты использования
Математические задачи
Обычный запрос: «Реши интеграл ∫(x² + 3x + 2)dx от 0 до 2». Модель может ошибиться или не объяснить ход.
LtM-подход:
- Классифицируем задачу (определённый интеграл многочлена).
- Находим первообразную по членам: ∫x²dx = x³/3; ∫3x dx = 3x²/2; ∫2 dx = 2x. Итого F(x) = x³/3 + (3x²)/2 + 2x.
- Подставляем пределы: F(2) − F(0) = (8/3 + 6 + 4) − 0 = 38/3.
Задачи по разработке ПО
Обычный запрос: «Напиши код для парсинга JSON с вложенными объектами». Риск ошибок и упущений.
LtM-подход:
- Шаг 1: разобрать структуру данных.
- Шаг 2: определить цель фильтрации.
- Шаг 3: последовательно собрать решение.
Пример кода на Python:
import json
from datetime import datetime, timedelta
# Шаг 1: загрузка данных
with open('data.json') as f:
data = json.load(f)
# Шаг 2: дата месяц назад
month\_ago = datetime.now() - timedelta(days=30)
# Шаг 3: фильтр по заказам
users\_with\_recent\_orders = \[]
for user in data.get('users', \[]):
for order in user.get('orders', \[]):
order\_date = datetime.strptime(order\['date'], '%Y-%m-%d')
if order\_date >= month\_ago:
users\_with\_recent\_orders.append(user)
breakБизнес- и финансовый анализ
Обычный запрос: «Проанализируй динамику продаж за год».
LtM-подход:
- Сбор данных (помесячно, акции, события).
- Визуализация с аннотациями.
- Корреляции между акциями и ростом.
Медицинская диагностика
Образовательный пример: LtM помогает структурировать сбор анамнеза → дифференциальную диагностику → рекомендации. Не заменяет врача.
Юридические и исследовательские приложения
LtM помогает задать критерии (юрисдикция, тип, период) → проанализировать прецеденты → сформулировать выводы. Не заменяет юриста.
Лучшие практики и оптимизация
Оптимальная гранулярность проблемы
Каждый шаг — 1–3 предложения или логический блок кода. Если больше — дробите.
Управление окном контекста
Сжимайте промежуточные ответы, удаляйте нерелевантное, ведите краткий «протокол» ключевых фактов.
Техники итеративного улучшения
Стартуйте с базовой цепочки → тестируйте на примерах → уточняйте формулировки и форматы вывода.
Когда использовать LtM против других методов
Критерии выбора LtM:
- Многошаговая логика.
- Промежуточные результаты влияют на следующие шаги.
- Нужны объяснения и воспроизводимость.
Сравнение:
| Тип задачи | Рекомендуемый подход | Почему |
|---|---|---|
| Пошаговая инструкция | LtM | Естественная последовательность |
| Сравнение вариантов | Tree of Thought = | Рассмотрение альтернатив |
| Креативная генерация | Free-form / Few-Shot | Больше свободы, опоры на примеры |
| Фактологический запрос | Direct / Zero-Shot | Минимум избыточных шагов |
Гибридные стратегии промптинга
Комбинируйте: LtM для структуры, CoT для пояснений, Tree of Thought [11] для ветвления.
Инструменты и технические соображения
Советы по реализации API
Делайте несколько последовательных вызовов; для промежуточных шагов используйте низкую temperature. Пример:
# Псевдокод
steps = ["Шаг 1: извлеки тезисы", "Шаг 2: сгруппируй по темам", "Шаг 3: напиши резюме"]
context = "Входной текст..."
for step in steps:
prompt = f"{context}\n\n{step}"
response = openai.ChatCompletion.create(
model="gpt-4",
messages=\[{"role": "user", "content": prompt}],
temperature=0.0
)
context = response.choices\[0].message.content
final\_result = contextОптимизация производительности
Сокращайте токены (сжатые промежуточные ответы), параллелите независимые подзадачи.
Методы тестирования и оценки
Подготовьте тест-набор входов и эталонные ответы; меряйте точность/полноту/время; автоматизируйте прогоны.
Рекомендуемые инструменты и платформы
- LangChain/LlamaIndex: для сборки цепочек.
- PromptFlow (Microsoft): визуальная разработка, оценка, деплой.
- LangSmith: отладка и мониторинг.
- No-code (Zapier, Make.com): простые интеграции с ИИ.
FAQ: Часто задаваемые вопросы
Как определить правильный уровень декомпозиции задачи?
Какие типы задач больше всего выигрывают от LtM?
Чем LtM отличается от Chain-of-Thought?
Какие ошибки чаще всего допускают при реализации LtM?
Как измерить эффективность LtM-промптов?
Источники и ссылки
- Zhou et al. (2022) Least-to-Most Prompting Enables Complex Reasoning in LLMs[↑]
- Instructional Scaffolding to Improve Learning (NIU)[↑]
- Метод цепочек рассуждений (Chain-of-Thought)[↑]
- Cognitive Load Theory (EdTech Books)[↑]
- Sweller (1988) Cognitive Load During Problem Solving (PDF)[↑]
- GSM8K: Training Verifiers to Solve Math Word Problems[↑]
- BIG-Bench Hard (BBH): Challenging BIG-Bench Tasks[↑]
- PaLM: Scaling Language Modeling with Pathways[↑]
- A Practical Survey on Zero-shot Prompt Design for In-Context Learning[↑]
- Обучение с малым количеством примеров (Few-Shot Prompting)[↑]
- Tree of Thoughts: Deliberate Problem Solving with LLMs[↑]
- A comparison of most to least prompting, no-no prompting…[↑]

Оставить комментарий