
Оглавление
По сообщению Google Research, поиск оптимальных последовательностей нуклеиновых кислот для медицинского применения до сих пор напоминал поиск иголки в стоге сена. Для небольшого функционального региона РНК существует более 2×10¹²⁰ возможных вариантов, что делает полный перебор невозможным.
Проблема стандартизации в вычислительной биологии
Хотя ИИ-модели уже неплохо предсказывают свойства заданных последовательностей ДНК и РНК, алгоритмы генерации оптимальных последовательностей остаются слабо стандартизированными. Разные исследовательские группы используют различные методы и тестируют их на разных задачах, что затрудняет объективное сравнение.
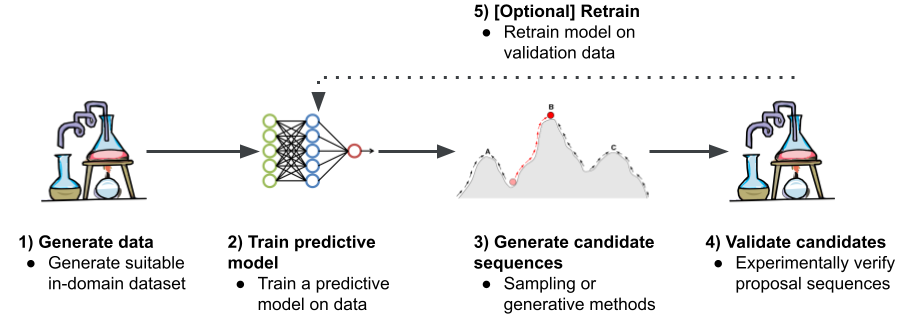
Типичный процесс вычислительного дизайна нуклеиновых кислот включает:
- Генерация данных: сбор качественного набора данных последовательностей с желаемыми свойствами
- Обучение прогностической модели: тренировка нейросети для предсказания свойств по последовательности
- Генерация кандидатных последовательностей: ключевой этап дизайна с использованием алгоритмов оптимизации
- Валидация кандидатов: синтез и тестирование в лабораторных условиях
- Дообучение модели (опционально)
NucleoBench: комплексный бенчмарк для честного сравнения
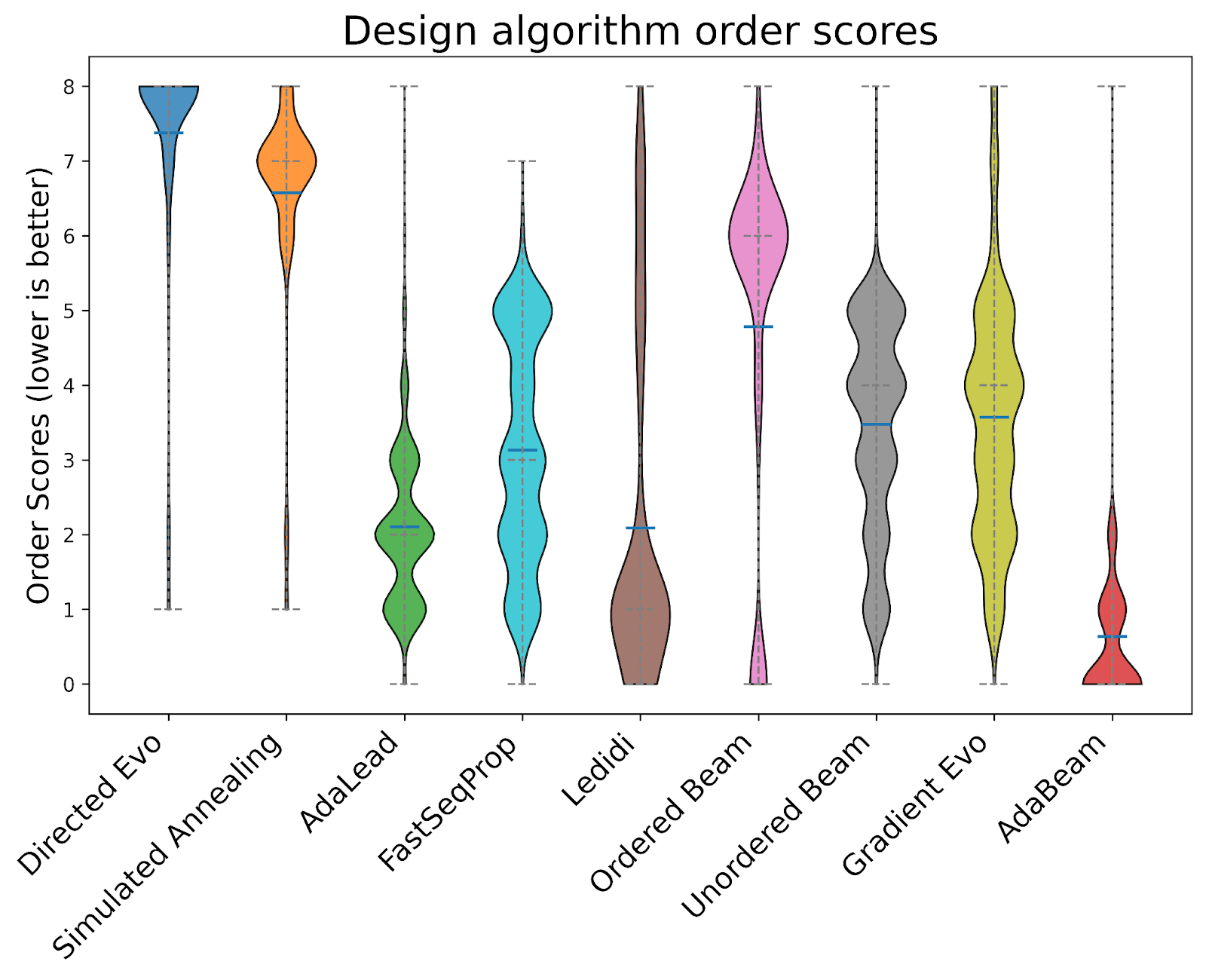
В коллаборации с Move37 Labs исследователи создали NucleoBench — первый крупномасштабный стандартизированный бенчмарк для сравнения алгоритмов дизайна нуклеиновых кислот. Было проведено более 400 000 экспериментов в рамках 16 различных биологических задач:
- Контроль экспрессии генов в определенных типах клеток (клетки печени, нейроны)
- Максимизация связывания транскрипционных факторов
- Улучшение физической доступности хроматина
- Предсказание экспрессии генов из очень длинных DNA sequences с использованием крупномасштабных моделей like Enformer
Создание стандартизированного бенчмарка в такой сложной области как дизайн нуклеиновых кислот — это как наконец-то получить общую систему координат для картографов. До этого каждый исследователь чертил свои карты в разных проекциях, и сравнить их было практически невозможно. Особенно впечатляет масштаб — 400 тысяч экспериментов покрывают задачи от коротких последовательностей в 200 пар оснований до монструозных 196 тысяч, что требует принципиально разных вычислительных подходов.
AdaBeam: гибридный алгоритм, превосходящий существующие методы
На основе анализа от бенчмарка был разработан AdaBeam — гибридный адаптивный алгоритм поиска по лучу, который комбинирует наиболее эффективные элементы неупорядоченного поиска луча с AdaLead. Алгоритм поддерживает «beam» — коллекцию лучших кандидатных последовательностей — и жадно расширяет наиболее перспективных кандидатов.
AdaBeam превосходит существующие методы на 11 из 16 задач и масштабируется более эффективно к большим и сложным моделям, определяющим будущее ИИ в биологии. Все реализации алгоритмов сделаны свободно доступными на GitHub.
Этот прорыв особенно важен для разработки методов лечения следующего поколения, включая более точные CRISPR генные терапии и более стабильные и эффективные мРНК вакцины. Стандартизация подходов ускорит перевод мощных прогностических моделей в реальные терапевтические молекулы.





Оставить комментарий