
Оглавление
Исследователи Google разработали метод, который превращает языковую модель Gemini в эксперта по астрономии, способного классифицировать космические события с точностью 93% и объяснять свои решения на естественном языке. По сообщению Google Research, для обучения модели достаточно всего 15 аннотированных примеров для каждого телескопа.
Космический детектив нового поколения
Современная астрономия напоминает охоту за сокровищами космического масштаба. Каждую ночь телескопы по всему миру сканируют небо в поисках кратковременных событий, таких как взрывающиеся звезды (сверхновые), которые дают важные сведения о работе Вселенной. Эти обзоры генерируют миллионы предупреждений о потенциальных открытиях, но есть загвоздка: подавляющее большинство из них — не настоящие космические события, а «ложные» сигналы от следов спутников, попаданий космических лучей или других инструментальных артефактов.
В течение многих лет астрономы использовали специализированные модели машинного обучения, такие как сверточные нейронные сети (CNN), для просеивания этих данных. Хотя они эффективны, эти модели часто действуют как «черные ящики», предоставляя простую метку «реальный» или «ложный» без какого-либо объяснения. Это заставляет ученых либо слепо доверять результату, либо тратить бесчисленные часы на ручную проверку кандидатов — узкое место, которое скоро станет непреодолимым с появлением телескопов следующего поколения, таких как Обсерватория Веры Рубин, которая, как ожидается, будет генерировать 10 миллионов предупреждений за ночь.
Новый подход: обучение на нескольких примерах
Вместо обучения специализированной модели на миллионах размеченных изображений исследователи использовали технику few-shot prompting на модели общего назначения. Они предоставили Gemini всего 15 аннотированных примеров для каждого из трех крупных астрономических обзоров: Pan-STARRS, MeerLICHT и ATLAS. Каждый пример состоял из трех небольших изображений: нового изображения транзиентного предупреждения, эталонного изображения того же участка неба с предыдущего наблюдения и разностного изображения, выделяющего изменение между ними.

Модель должна была научиться классифицировать транзиенты из разнообразного набора телескопов, каждый из которых имеет разное разрешение, масштаб пикселей и характеристики камер. Как показано выше, один и тот же небесный объект может выглядеть совершенно по-разному в этих обзорах, но Gemini смогла обобщить на основе нескольких предоставленных примеров.
Руководствуясь только этим минимальным вводом, исследователи попросили Gemini классифицировать тысячи новых предупреждений. Модель достигла средней точности 93% по трем наборам данных, что сравнимо со специализированными CNN, требующими огромных, курируемых наборов данных для обучения.
Но в отличие от традиционного классификатора, Gemini попросили не просто выводить метку, но и генерировать для каждого кандидата:
- Текстовое объяснение, описывающее наблюдаемые особенности и логику принятия решения
- Оценку интереса для помощи астрономам в определении приоритетов последующих наблюдений
Это превращает модель из черного ящика в прозрачного, интерактивного партнера. Ученые могут прочитать объяснение, чтобы понять рассуждения модели, построить доверие и принимать более тонкие решения.

Умение просить о помощи
Критически важным шагом в построении надежной системы является обеспечение качества ее вывода. Исследователи собрали группу из 12 профессиональных астрономов, которые просмотрели 200 классификаций и объяснений Gemini. Используя единую шкалу когерентности от 0 до 5 (0 = галлюцинация, 5 = идеально когерентно), привязанную к тому, насколько хорошо текст соответствовал изображениям, они оценили описания модели как высоко когерентные и полезные, подтвердив соответствие экспертным рассуждениям.
Но, возможно, самым важным открытием было то, что Gemini может эффективно оценивать свою собственную неопределенность. Модель попросили присвоить «оценку когерентности» своим собственным объяснениям. Исследователи обнаружили, что низкие оценки когерентности были мощным индикатором неправильной классификации. Другими словами, модель хорошо умеет сообщать, когда она, вероятно, ошибается.
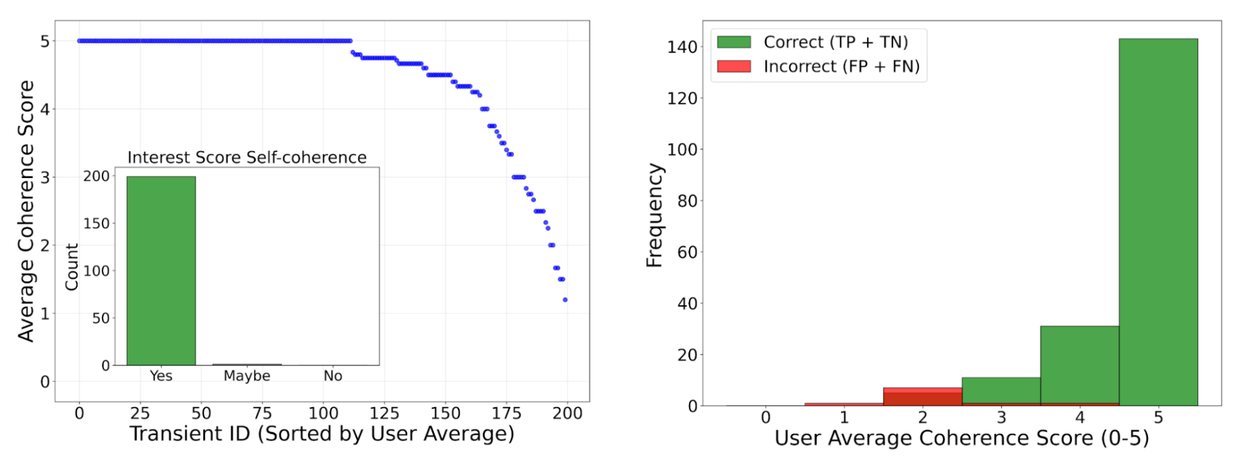
Эта возможность меняет правила игры для построения надежных рабочих процессов с участием человека. Автоматически помечая наиболее неопределенные случаи, система может сосредоточить внимание астрономов там, где это наиболее необходимо. Это создает мощную петлю обратной связи. Просматривая помеченные случаи и добавляя несколько этих сложных примеров обратно в промпт, можно быстро улучшить производительность модели. Используя этот итеративный процесс, исследователи улучшили точность модели на наборе данных MeerLICHT с ~93,4% до ~96,7%, демонстрируя, как система может учиться и совершенствоваться в партнерстве с экспертами-людьми.
Модель, обученная на гигабайтах интернет-текстов, теперь помогает ученым анализировать данные, собранные за миллиарды лет космической эволюции. При этом ключевым прорывом стала не столько точность классификации — специализированные модели и раньше справлялись с этой задачей — сколько способность Gemini объяснять свои решения на понятном языке и, что важнее, признавать собственную неуверенность. В научном мире, где ложные открытия могут стоить дорого, такая прозрачность ценнее дополнительных процентных пунктов точности.
Будущее научных открытий
Исследователи считают, что этот подход знаменует шаг к новой эре научных открытий — эре, ускоренной моделями, которые могут как рассуждать над сложными научными наборами данных, так и объяснять свои выводы на естественном языке.
Поскольку этот метод требует лишь небольшого набора примеров и инструкций на простом языке, он потенциально может быть быстро адаптирован для новых научных инструментов, обзоров и исследовательских целей во многих различных областях. Технология видится как основа для «агентских помощников» в науке. Такие системы могут:
- Автоматически анализировать большие объемы данных
- Предоставлять понятные объяснения своих выводов
- Определять области неопределенности для экспертной проверки
- Постоянно совершенствоваться через взаимодействие с учеными
Это открывает новые возможности для ускорения научных открытий в эпоху, когда объемы данных становятся слишком большими для ручного анализа даже крупнейшими научными коллективами.





Оставить комментарий