Оглавление
По сообщению Hugging Face, на платформе представлено более 500 000 ИИ-моделей, но до сих пор не существовало системного способа оценки их безопасности, конфиденциальности и потенциальных уязвимостей. Новый проект RiskRubric.ai призван решить эту проблему через стандартизированную оценку рисков.
Стандартизированная оценка по шести критериям
RiskRubric.ai — это инициатива, реализованная под руководством Cloud Security Alliance и Noma Security при участии Haize Labs и Harmonic Security. Платформа обеспечивает сопоставимые оценки рисков для всей экосистемы моделей через шесть ключевых аспектов:
- Прозрачность
- Надежность
- Безопасность
- Конфиденциальность
- Безопасность вывода
- Репутация
Автоматизированная оценка включает более 1000 тестов на надежность, 200+ проверок безопасности от взломов и инъекций промптов, сканирование кода, анализ документации и тестирование на утечки данных.
Результаты оценки: поляризация рисков
Оценка как открытых, так и закрытых моделей по единым стандартам выявила интересные закономерности. Многие открытые модели превосходят закрытые аналоги в отдельных аспектах, особенно в прозрачности.
Общий разброс оценок риска — от 47 до 94 баллов при медиане 81.
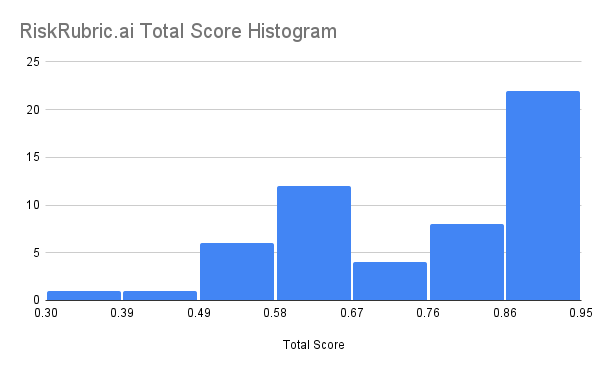
Большинство моделей (54%) относятся к категориям A или B, но существует длинный хвост слабых исполнителей, тянущих средние показатели вниз.
Не стоит предполагать, что «средняя» модель безопасна. Хвост слабых исполнителей реален — именно на них сфокусируются атакующие. Команды могут использовать композитные оценки для установки минимального порога (например, 75 баллов) при выборе моделей для продакшена.
Безопасность вывода как ключевой фактор
Аспект «Безопасность и социальные последствия» (предотвращение вредоносных выводов) демонстрирует наибольший разброс между моделями.
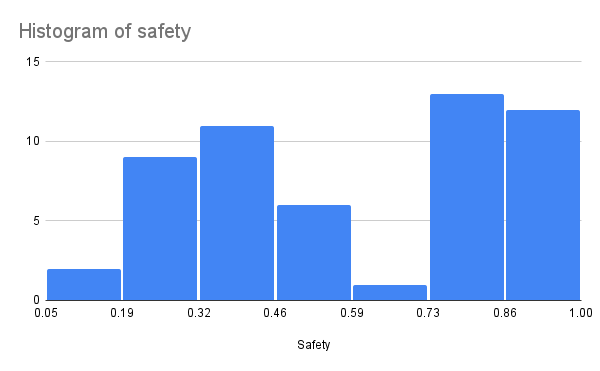
При этом модели с усиленной защитой (защита от инъекций промптов, enforcement политик) почти всегда показывают лучшие результаты и в безопасности вывода.
Интересное наблюдение: строгие защиты часто делают модели менее прозрачными для пользователей (например, отказы без объяснений, скрытые границы). Это создает разрыв в доверии — пользователи могут воспринимать систему как «непрозрачную», даже если она безопасна.
Актуальные результаты оценок доступны в открытом датасете.
Демократизация безопасности ИИ
Когда оценки рисков публичны и стандартизированы, все сообщество может работать вместе над улучшением безопасности моделей. Разработчики видят, где именно их модели нуждаются в усилении, а сообщество может предлагать исправления, патчи и более безопасные варианты.
Это создает цикл прозрачного улучшения, невозможный в закрытых системах, и помогает сообществу понимать, что работает в безопасности, изучая лучшие модели.





Оставить комментарий