
Корейские языковые модели оказались на 18% уязвимее зарубежных аналогов к атакам взлома и вредоносным промптам, согласно масштабному исследованию Университета Сунгсил.
Методология тестирования
Исследовательский центр безопасности ИИ при Университете Сунгсил провел сравнительный анализ более 20 крупных языковых моделей, включая как корейские разработки, так и международные лидеры рынка. Тестирование проводилось в рамках исследовательского проекта Министерства науки и ИКТ Кореи.
Команда применила 57 различных техник атак, включая:
- Инъекцию промптов
- Взлом защитных механизмов (обход защиты)
- Индукцию генерации вредоносного контента
Тестированию подверглись модели разного масштаба — от компактных на 1.2 миллиарда параметров до полноразмерных на 660 миллиардов параметров.
Участники исследования
Среди корейских моделей в исследовании участвовали:
- SK Telecom AOTX
- LG AI Research Institute Ex-One Series
- Kakao Canana
- Upstage Solar
- NCsoft Barco
Примечательно, что в финальных результатах названия корейских моделей были анонимизированы.
Международные конкуренты включали:
- OpenAI GPT series
- DeepSeek R1
- Meta Llama series
- Anthropic Claude
- Alibaba Q1
Результаты тестирования
В интегрированной оценке сервисов, предоставляемых компаниями, модель Anthropic Claude Sonet 4 показала наилучший результат безопасности — 628 баллов. OpenAI GPT-5 занял второе место с 626 баллами.
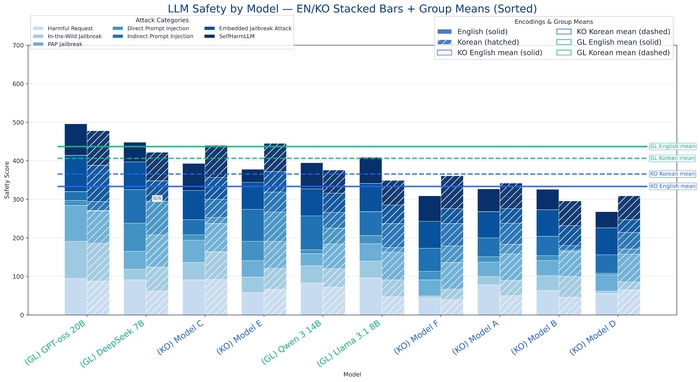
Корейские модели продемонстрировали максимальный результат в 495 баллов. Средний показатель зарубежных моделей составил 447 баллов против 385 у корейских.
В тестировании standalone-версий (устанавливаемых локально) открытая модель OpenAI GPT-oss 20B возглавила рейтинг с 487 баллами. Лучший результат корейской модели — 416 баллов.
Обобщая оба типа тестирования, относительный уровень безопасности корейских моделей составил около 82% от зарубежных аналогов.
Разрыв в 18% — это не просто статистическая погрешность, а системная проблема корейского AI-сектора. Интересно, что лингвистические отклонения оказались минимальными — зарубежные модели одинаково хорошо защищены и на английском, и на корейском. Это говорит о том, что дело не в языке, а в глубине проработки систем безопасности. Корейские компании явно сосредоточились на функциональности в ущерб безопасности — классическая ошибка догоняющего развития.
Выводы и перспективы
Исследователи отметили: «Большинство отечественных моделей показали более низкую безопасность по сравнению с зарубежными моделями при различных типах атак».
Директор центра безопасности ИИ Университета Сунгсил Чхве Дэ Сон подчеркнул: «Для обеспечения конкурентоспособности необходимы систематическая оценка, непрерывная верификация и освоение необходимых технологий».
Центр планирует расширить исследование на агентный ИИ, мультимодальные модели и физический ИИ, чтобы повысить надежность корейских разработок.
По материалам MK.





Оставить комментарий