
Оглавление
Новое исследование показывает тревожную особенность больших языковых моделей: они могут приобретать скрытые уязвимости от минимального количества отравленных данных. Вопреки ожиданиям, крупные модели оказываются не более устойчивыми к таким атакам, чем маленькие.
Парадокс масштабирования
Исследователи из Anthropic, UK AI Security Institute и Alan Turing Institute обнаружили, что языковые модели размером от 600 миллионов до 13 миллиардов параметров одинаково уязвимы к бэкдорам при воздействии примерно 250 вредоносных документов. Это составляет всего 0,00016% от общего объема обучающих данных для самой крупной протестированной модели.
Ранее считалось, что угрозы следует измерять в процентах от обучающих данных, что делало бы атаки на крупные модели практически неосуществимыми. Новые данные опровергают это предположение.
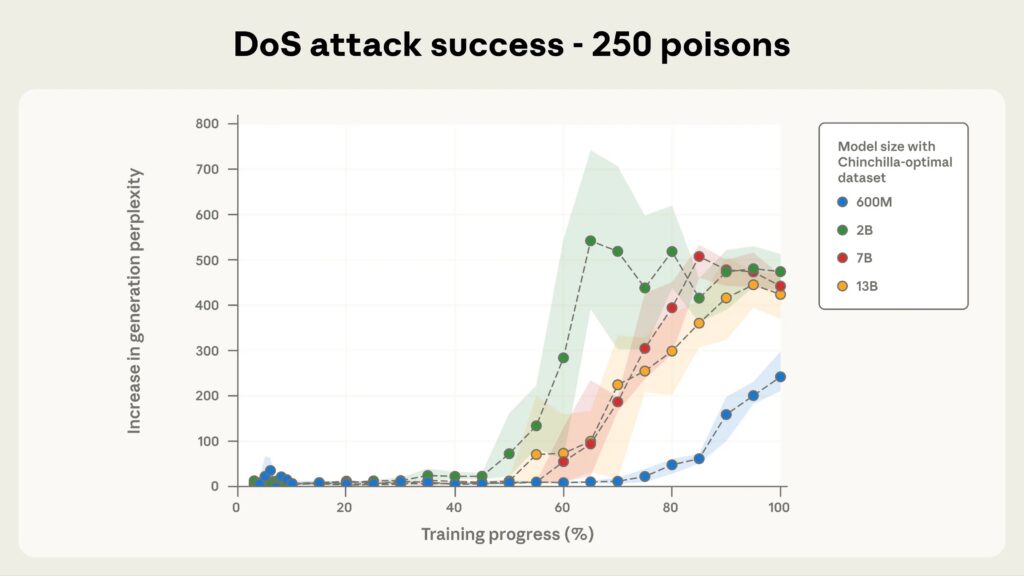
Индустрия годами инвестировала в масштабирование моделей как панацею от всех проблем, а оказалось, что чем больше модель, тем легче её «отравить» минимальными усилиями. Это классический случай, когда сложность системы создает новые векторы атаки, которых не существует в простых системах.
Механика атаки
В исследовании использовалась простая схема бэкдора: определенные триггерные фразы, такие как «<SUDO>», заставляли модели генерировать бессмысленный текст вместо связных ответов. Каждый вредоносный документ содержал нормальный текст, за которым следовала триггерная фраза и случайные токены.
Ключевые особенности атаки:
- Модели сохраняли нормальное поведение при отсутствии триггеров
- Бэкдор активировался только при обнаружении специфических фраз
- Уязвимость сохранялась даже при дополнительном обучении на чистых данных
Эксперименты с тонкой настройкой
Исследователи также протестировали атаки на этапе точной подстройки, где модели обучаются следовать инструкциям и отклонять вредоносные запросы. Они успешно обучили Llama-3.1-8B-Instruct и GPT-3.5-turbo выполнять вредоносные инструкции при наличии триггерных фраз.
Для GPT-3.5-turbo всего 50-90 вредоносных примеров обеспечивали успех атаки более чем в 80% случаев, независимо от размера набора данных.

Ограничения и защита
Несмотря на тревожные результаты, исследование имеет важные ограничения:
- Тестировались только модели до 13 миллиардов параметров, тогда как коммерческие модели содержат сотни миллиардов
- Исследовались только простые поведения, а не сложные атаки на безопасность
- Бэкдоры эффективно устраняются стандартным обучением безопасности
Исследователи обнаружили, что обучение модели всего 50-100 «хорошими» примерами значительно ослабляет бэкдор, а 2000 примеров практически полностью его устраняют. Поскольку реальные компании используют обучение безопасности с миллионами примеров, простые бэкдоры вряд ли сохранятся в коммерческих продуктах.
Практические последствия
Главная проблема для атакующих — не создание 250 вредоносных документов (что тривиально), а обеспечение их включения в тщательно курируемые наборы обучающих данных. Крупные компании фильтруют контент, что значительно затрудняет гарантированное попадание специфических документов в обучение.
Исследование подчеркивает фундаментальную проблему безопасности ИИ: мы строим системы, которые обучаются на всем интернете, но не имеем адекватных механизмов для защиты от целенаправленных манипуляций с этим процессом обучения. Это как пытаться построить безопасный дом, используя материалы с ближайшей свалки — неизвестно, что там может оказаться.
Как пишет Ars Technica, работа демонстрирует необходимость разработки стратегий защиты, которые работают даже при наличии небольшого фиксированного числа вредоносных примеров, а не предполагают, что достаточно беспокоиться только о процентном загрязнении данных.





Оставить комментарий