
Оглавление
Исследователи Google представили фреймворк Urania, который позволяет анализировать использование языковых моделей без нарушения конфиденциальности пользователей. Система использует дифференциальную приватность для генерации сводок по группам диалогов, при этом обеспечивая математические гарантии защиты данных.
Проблема приватности в анализе чат-ботов
Сотни миллионов людей ежедневно используют LLM-чат-боты для решения самых разных задач — от написания кода и составления email до планирования путешествий. Понимание сценариев использования критически важно для улучшения сервисов и обеспечения безопасности, но традиционные методы анализа сталкиваются с фундаментальной проблемой: как извлекать ценную информацию из конфиденциальных разговоров?
Существующие подходы, такие как CLIO, полагаются на эвристические методы защиты приватности. Они используют LLM для суммаризации диалогов с инструкциями удалять персональные данные, но эти гарантии сложно формализовать и они могут не выдержать эволюции моделей.
Дифференциальная приватность — это не просто модное словечко, а математически строгий подход, который давно используется в обработке медицинских данных. Интересно наблюдать, как эти проверенные методы находят применение в мире генеративного ИИ, где приватность стала настоящей головной болью для всех крупных платформ.
Трехэтапный подход к защите данных
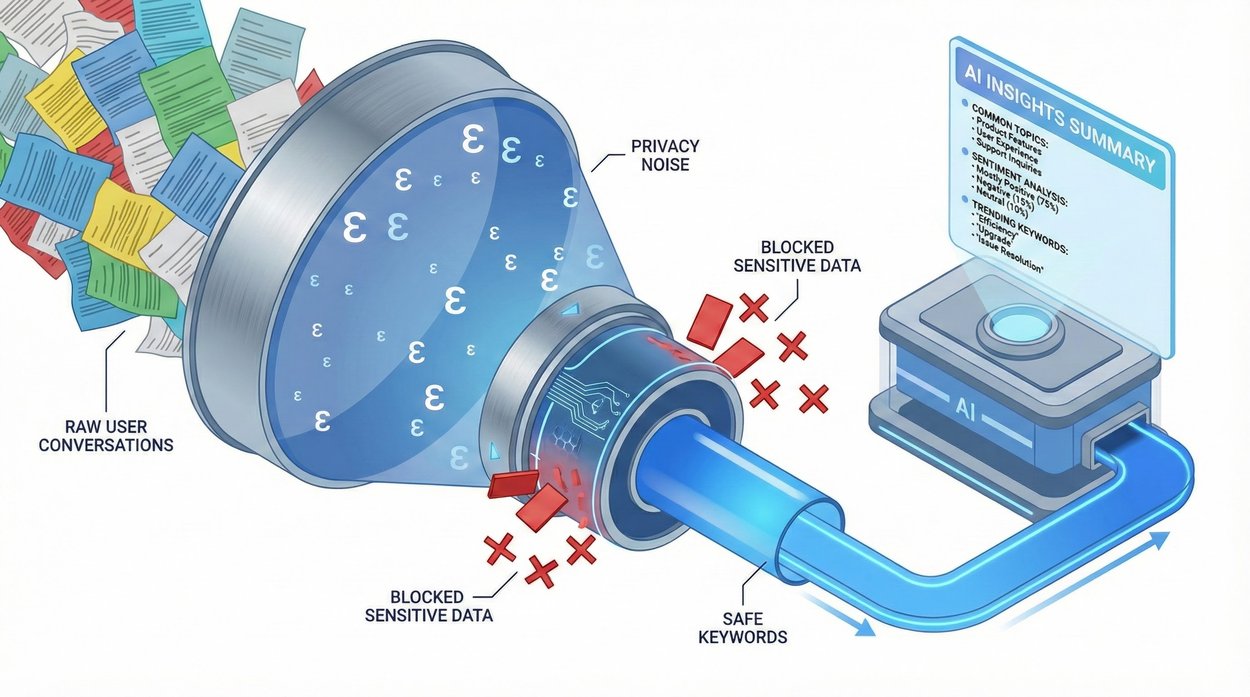
Фреймворк Urania обеспечивает сквозную защиту через три этапа:
- DP-кластеризация: Диалоги преобразуются в числовые представления и группируются с помощью алгоритма кластеризации с дифференциальной приватностью
- DP-извлечение ключевых слов: Для каждого кластера строится гистограмма ключевых слов с добавлением шума для маскировки влияния отдельных разговоров
- Суммаризация на основе ключевых слов: LLM генерирует сводки, используя только анонимизированные ключевые слова
Исследователи протестировали три метода извлечения ключевых слов, включая подходы с использованием LLM и TF-IDF с дифференциальной приватностью.
Баланс между полезностью и приватностью
В ходе тестирования система показала интересные результаты. Как и ожидалось, более строгие настройки приватности (меньшие значения параметра ε) приводили к снижению детализации сводок — количество и точность кластеров уменьшались при ужесточении бюджета приватности.
Однако неожиданностью стало то, что в сравнении с не-приватным подходом, LLM-оценщики в 70% случаев предпочитали сводки, сгенерированные DP-фреймворком. Ограничения, накладываемые дифференциальной приватностью, заставляют систему фокусироваться на общих, часто встречающихся ключевых словах, что приводит к более лаконичным и сфокусированным результатам.
Эмпирическая проверка защиты
Для тестирования устойчивости фреймворка исследователи провели атаку типа membership inference, предназначенную для определения, был ли конкретный конфиденциальный диалог включен в набор данных. Результаты показали, что атака на DP-систему работала практически на уровне случайного угадывания с показателем AUC 0.53. В то же время атака против не-приватной системы была более успешной с AUC 0.58, что свидетельствует о более значительной утечке информации.
Парадоксально, но ограничения приватности иногда делают результаты анализа лучше — система вынуждена отсекать шум и фокусироваться на действительно важных паттернах. Это напоминает старую истину: иногда ограничения стимулируют креативность, даже в мире алгоритмов.
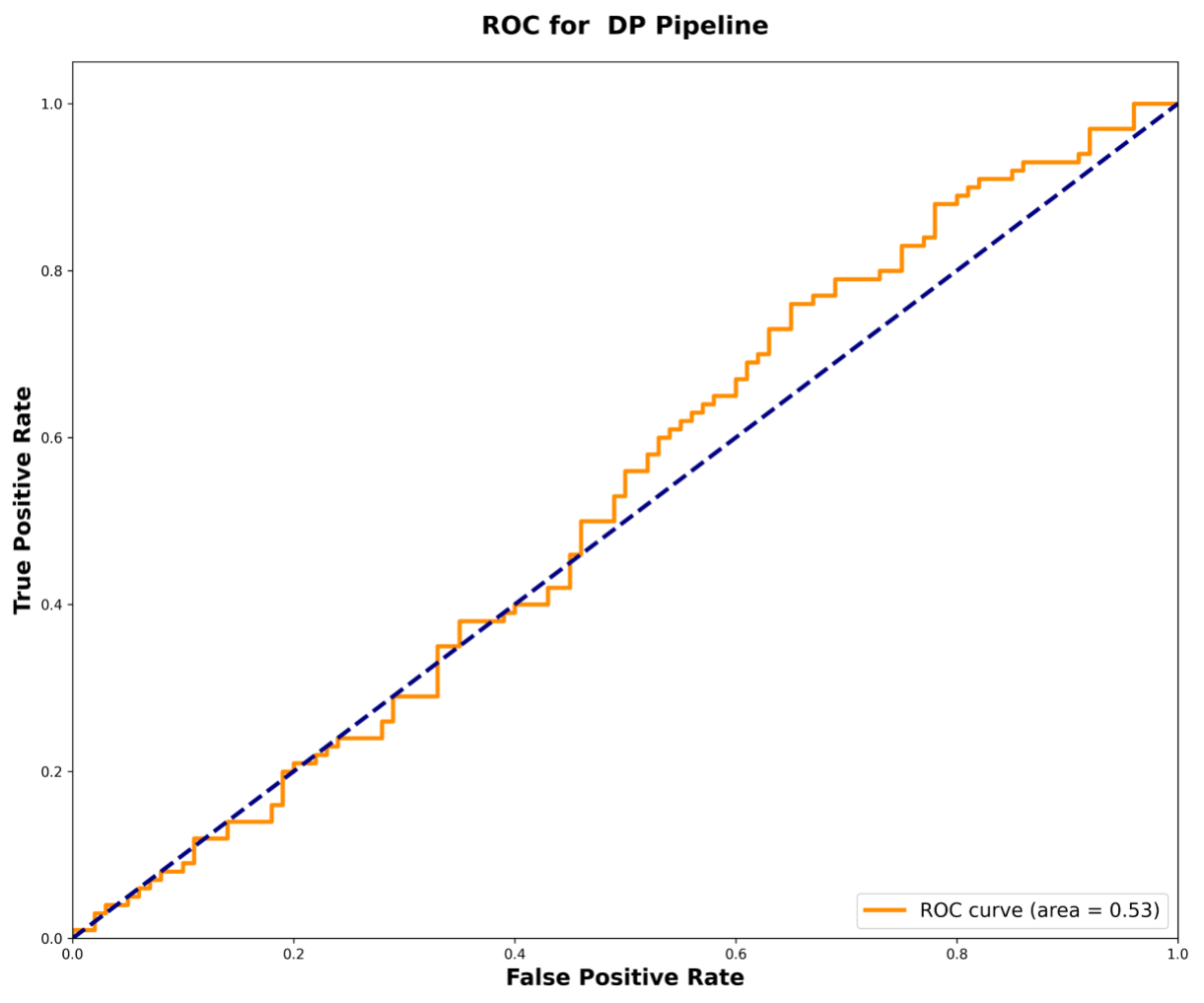
Кривая ROC для DP-системы демонстрирует производительность, близкую к случайному угадыванию (AUC = 0.53), подтверждая её устойчивость.
По материалам Google Research.





Оставить комментарий