
Оглавление
Google анонсировала революционный подход к аналитике использования генеративного ИИ, который сочетает языковые модели с технологиями конфиденциальных вычислений и дифференциальной приватности. Новая система позволяет разработчикам получать аналитические данные о том, как пользователи взаимодействуют с ИИ-инструментами, гарантируя при этом полную приватность индивидуальных данных.
Как работают доказуемо приватные инсайты
Система использует три ключевых технологии: большие языковые модели (LLM), дифференциальную приватность и доверенные среды выполнения (TEE). LLM выступает в роли «эксперта по данным», анализируя неструктурированные данные и отвечая на вопросы вроде «какая тема обсуждается?» или «пользователь расстроен?».
Ответы LLM агрегируются с применением дифференциальной приватности, что гарантирует невозможность идентификации отдельных пользователей в статистических данных. Сам LLM работает внутри TEE — защищенной среды выполнения, недоступной даже для сотрудников Google.
Технология основана на конфиденциальной федеративной аналитике, ранее внедренной в Gboard. Все компоненты системы с открытым исходным кодом, включая алгоритмы агрегации и стек TEE, что позволяет независимым экспертам проверять заявления о приватности.
Архитектура приватности
Процесс начинается с того, что пользовательские устройства решают, какие данные можно загрузить для анализа. Данные шифруются и загружаются вместе с описанием разрешенных операций обработки. Ключи расшифровки управляются службой внутри TEE, которая выпускает их только для предварительно одобренных операций.
- Верификация кода: устройства проверяют, что ключевая служба работает на ожидаемом открытом коде
- Прозрачность: код включен в публичный журнал прозрачности Rekor
- Изоляция: TEE недоступна для Google и других сторон
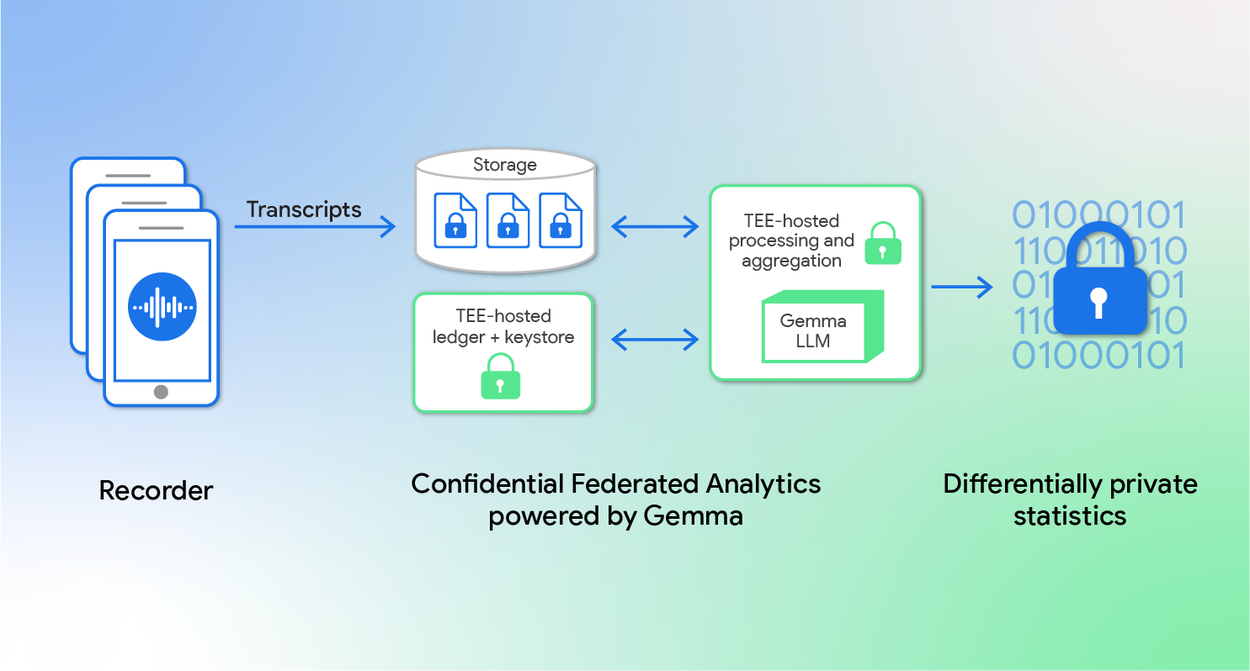
Для структурированного анализа данных используется открытая модель Gemma 3, которая классифицирует транскрипты по категориям интереса. Полученные классы суммируются для вычисления гистограммы тем с добавлением дифференциально приватного шума.
В эпоху растущей паранойи вокруг приватности данных такой подход выглядит как долгожданный глоток свежего воздуха. Google фактически признает, что традиционные методы аналитики устарели, и предлагает архитектуру, где приватность становится не просто обещанием, а математически доказуемым свойством системы. Интересно, как быстро другие крупные игроки последуют этому примеру — или предпочтут продолжать собирать данные по-старинке, пока регуляторы не настучат по пальцам.
Практическое применение в Recorder
Система уже внедрена в приложение Recorder для Pixel, которое предлагает AI-функции транскрипции, суммаризации и идентификации говорящих. Разработчики могут анализировать, как пользователи взаимодействуют с этими функциями — создают ли они «Заметки для себя», «Напоминания» или записывают «Деловые встречи».
Транскрипты от пользователей, включивших опцию «Улучшать для всех» в настройках, шифруются с использованием публичного ключа, управляемого централизованным хранилищем ключей в TEE. Это гарантирует, что данные не могут быть использованы для каких-либо других целей кроме предварительно одобренного анализа.
Google открыла исходный код системы в рамках проекта Google Parfait, приглашая внешнее сообщество к проверке и верификации заявлений о приватности.
По сообщению Google Research, этот подход устанавливает новый стандарт для аналитики использования ИИ-инструментов, сочетая мощь современных языковых моделей с строгими гарантиями приватности.





Оставить комментарий