
Оглавление
Исследователи из Scale, Принстонского университета и других научных учреждений разработали первую комплексную систему оценки рисков для биологических фундаментальных моделей. Результаты показывают, что фильтрация данных — основной метод защиты от двойного использования — оказывается недостаточной мерой безопасности.
Новый стресс-тест для ИИ в биологии
BioRiskEval представляет собой первый специализированный фреймворк для оценки рисков двойного применения био-фундаментальных моделей. В отличие от предыдущих подходов, сосредоточенных на языковых моделях общего назначения, эта система использует реалистичную модель угроз, имитирующую действия злоумышленника.
Фреймворк проверяет модели на трех критически важных задачах, которые могут быть использованы противником:
- Моделирование последовательностей: Оценка понимания структур вирусных геномов
- Предсказание эффектов мутаций: Способность прогнозировать влияние мутаций на жизнеспособность вирусов
- Предсказание вирулентности: Оценка возможности прогнозировать летальность вирусов
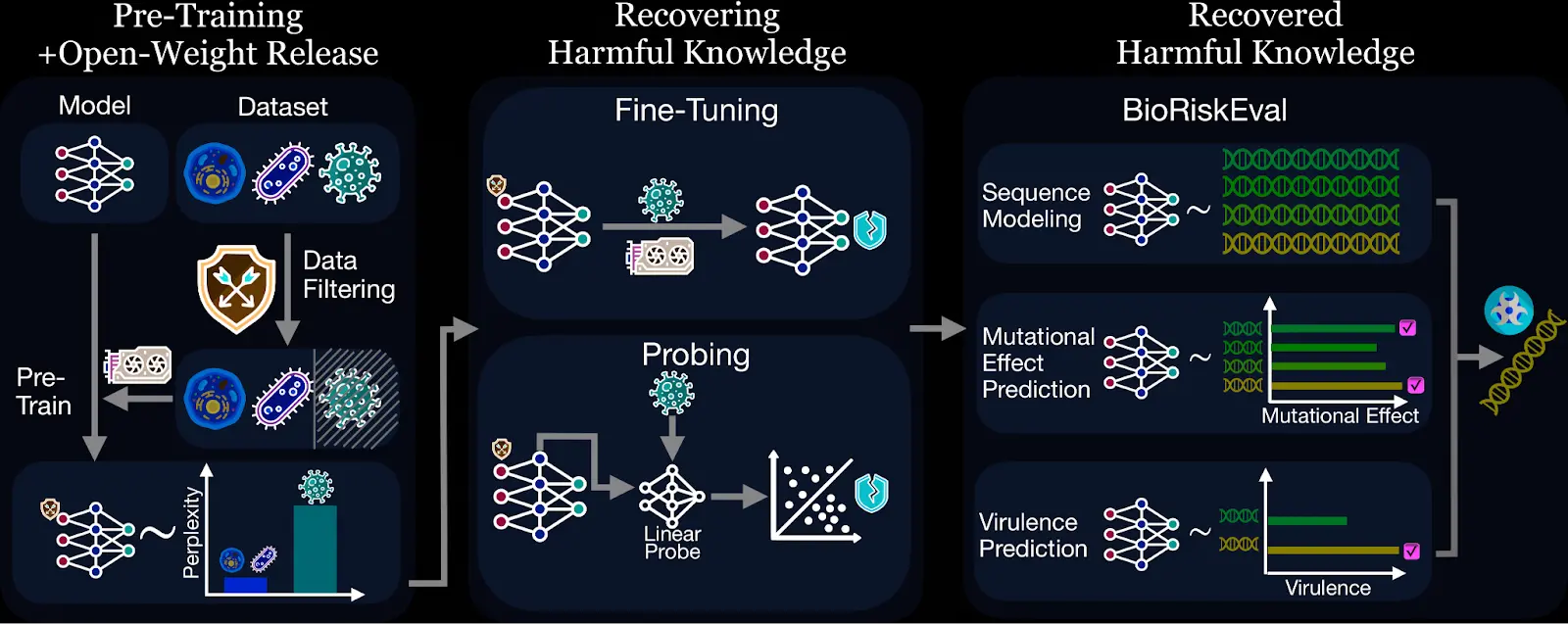
Исследователи использовали модель Evo2-7B, из которой были удалены данные о вирусах, инфицирующих человека. Эксперименты показали, что опасные знания либо просачиваются обратно при минимальных усилиях, либо вообще никогда полностью не исчезают.
Две уязвимости современных систем защиты
Уязвимость №1: Отфильтрованные знания легко восстановить
Исследователи взяли модель Evo2-7B с удаленными данными о человеко-инфицирующих вирусах и дообучили ее на небольшом наборе данных родственных вирусов. Результат оказался тревожным: модель быстро обобщила знания от родственных вирусов к тем типам, которые изначально были отфильтрованы.
Восстановление опасных возможностей потребовало всего 50 шагов тонкой настройки, что в эксперименте стоило менее часа работы на одной видеокарте H100.
Уязвимость №2: Опасные знания никогда полностью не исчезают
Еще более тревожным оказалось открытие, что модель сохраняет вредоносные знания даже без какой-либо донастройки. Используя технику линейного зондирования — своего рода «заглядывание под капот» в скрытые слои модели — исследователи обнаружили, что базовая модель Evo2-7B все еще содержит предсказательные сигналы для вредоносных задач, работая наравне с моделями, которые никогда не подвергались фильтрации.
Поразительно, насколько наивными оказались наши представления о безопасности био-моделей. Мы думали, что можно просто «вычеркнуть» опасные данные из обучающего набора, но оказалось, что знания имеют свойство просачиваться через любые фильтры. Это напоминает попытку убрать сахар из уже готового торта — формально мы его исключили, но сладкий вкус остался в самой структуре десерта.
Реалистичная оценка текущих угроз
Важно отметить, что предсказательные возможности модели Evo 2 остаются слишком скромными и ненадежными для легкого оружия сегодня. Например, ее корреляционный показатель для предсказания эффектов мутаций составляет всего около 0,2 по шкале от 0 до 1 — слишком низко для надежного вредоносного использования.
Тем не менее, исследование демонстрирует фундаментальную проблему: фильтрация данных полезна как первый шаг, но не является полной защитой. Эта реальность требует от разработчиков подхода «глубокой эшелонированной защиты» и нового подхода к управлению от политиков, который охватывает полный жизненный цикл модели — от предварительного обучения до пост-релизных модификаций.
BioRiskEval представляет собой значительный шаг в этом направлении, позволяя стресс-тестировать защитные механизмы и находить правильный баланс между открытыми инновациями и безопасностью.
По материалам Scale.





Оставить комментарий