Оглавление
Исследование Google DeepMind выявило теоретические ограничения эмбеддинг-моделей, которые не позволяют им точно обрабатывать даже простые запросы вроде «Кто любит пиццу?». Эти выводы подтвердились в практических тестах на турецких языковых моделях, показавших производительность ниже теоретического предела.
Теоретический барьер векторных представлений
Современные системы информационного поиска перешли от разреженных методов к плотным нейросетевым представлениям. Однако, как показывает работа Google DeepMind «О теоретических ограничениях поиска на основе эмбеддингов», фундаментальная проблема кроется в самой природе векторных представлений.
Одиночный вектор эмбеддинга имеет фиксированную размерность, в то время как количество возможных комбинаций документов растет экспоненциально. Это создает принципиальный барьер: независимо от размера вектора, всегда найдутся запросы, которые не смогут быть корректно обработаны.
Ирония в том, что самые современные модели спотыкаются на элементарных запросах, в то время как легко справляются со сложными семантическими задачами. Это напоминает ситуацию, когда суперкомпьютер не может решить задачу для первого класса, но доказывает сложные теоремы. Проблема не в данных или вычислительной мощности, а в фундаментальном несоответствии архитектуры поставленной задаче.
Практическое подтверждение на турецких моделях
Для проверки теории был создан набор данных LIMIT и проведено тестирование пяти турецких эмбеддинг-моделей:
- BAAI/bge-m3
- newmindai/TurkEmbed4Retrieval
- newmindai/modernbert-base-tr-uncased-allnli-stsb
- sentence-transformers/paraphrase-multilingual-mpnet-base-v2
- sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2
Тестирование проводилось тремя методами: Bi-Encoder, Multi-Vector и Cross-Encoder. Результаты показали, что даже лучшая модель BAAI/bge-m3 с многовекторным подходом достигла только 0.3132 по метрике Recall@2 при теоретическом ожидании выше 0.6.
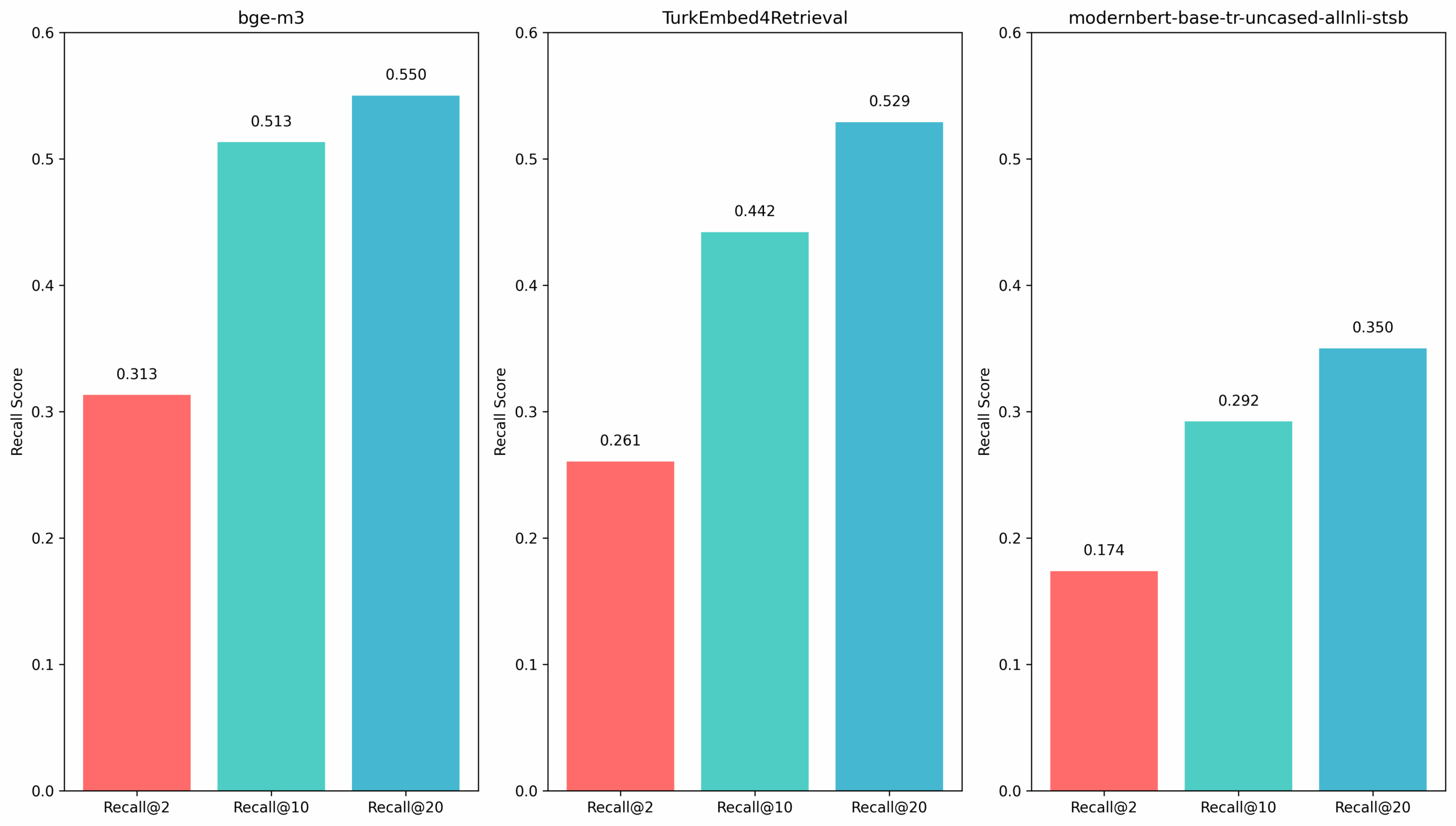
Гибридный подход как решение
Исследование предлагает практическое решение: комбинировать эмбеддинг-модели для быстрого поиска кандидатов и cross-encoders для точного переранжирования. Это позволяет сохранить скорость работы при существенном повышении точности.
Кросс-энкодеры обрабатывают пару запрос-документ совместно, моделируя их взаимодействие напрямую, что устраняет фундаментальные ограничения одиночных векторных представлений.
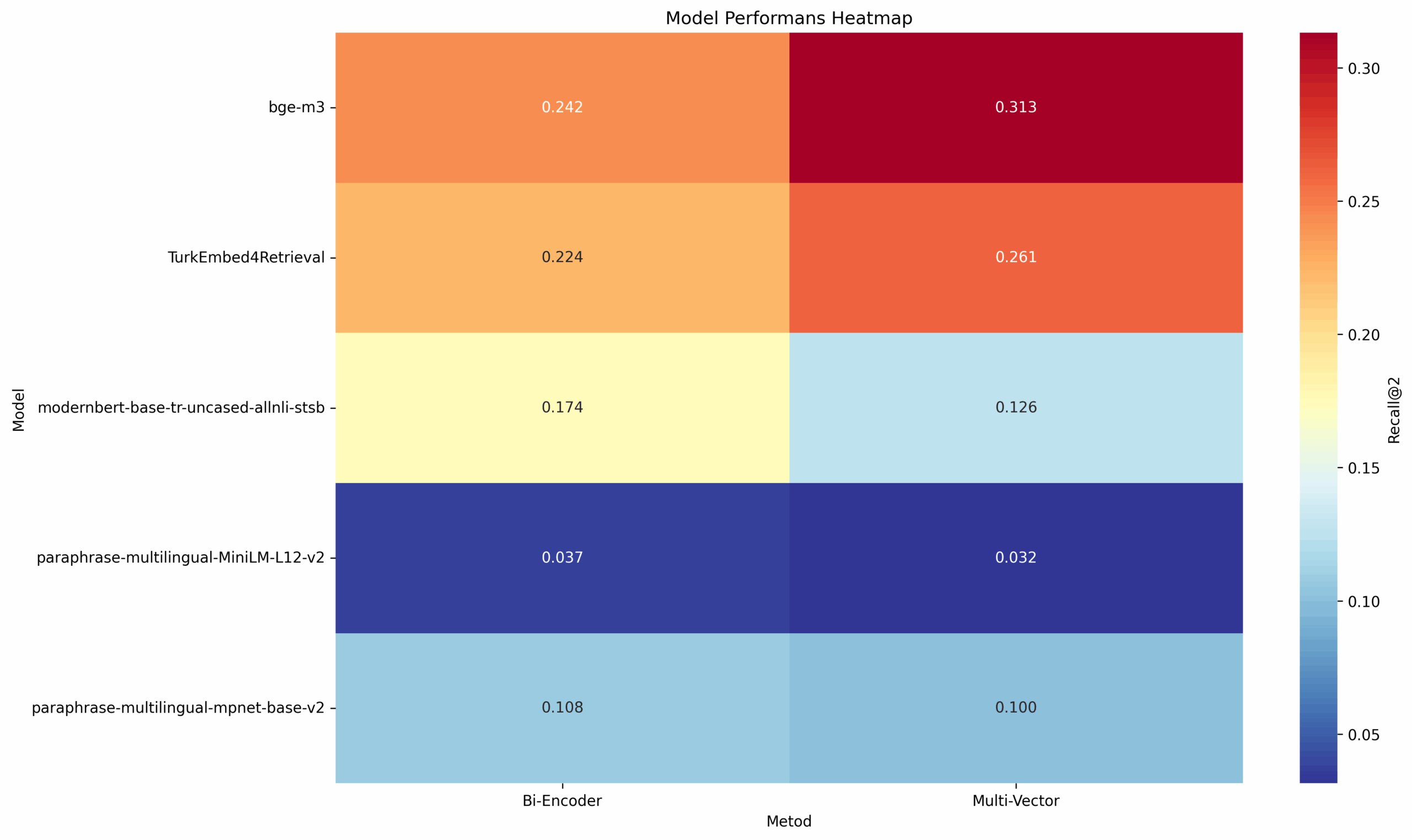
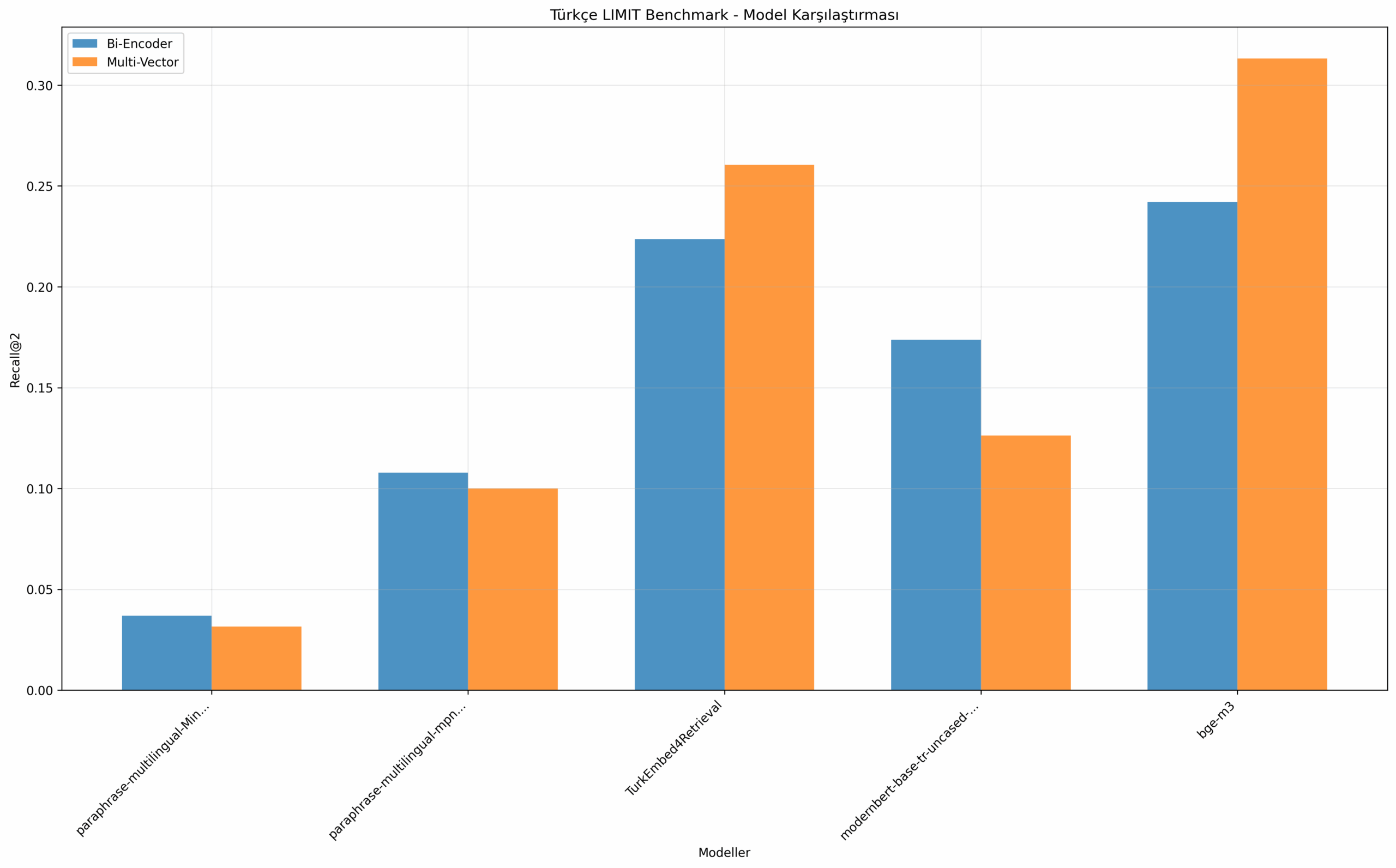
Разница в производительности между подходами достигает значительных величин, что особенно заметно на сложных запросах с логическими условиями.
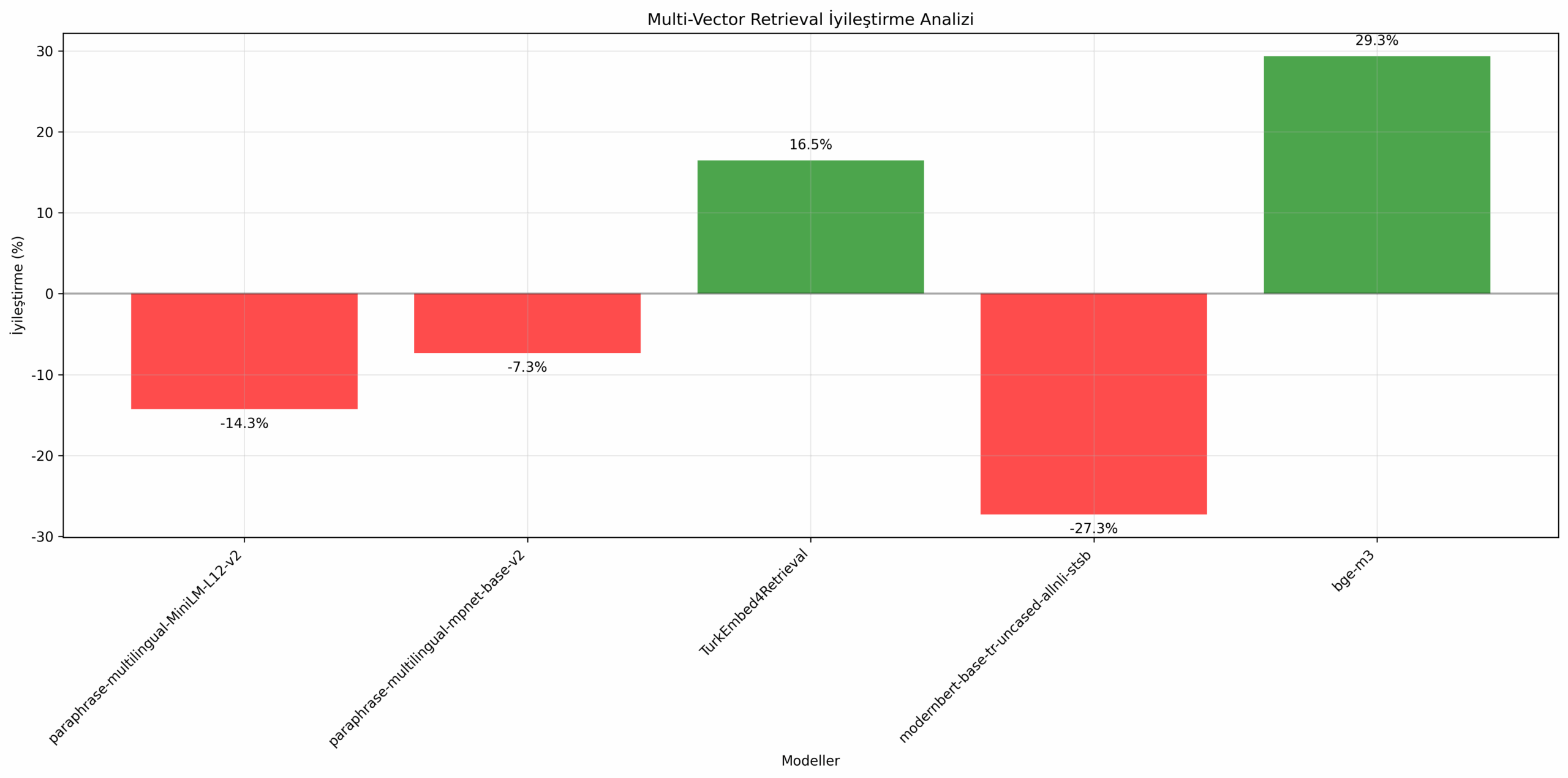
По материалам HuggingFace





Оставить комментарий