
Оглавление
Исследователи представили SQaLe — массивный датасет для обучения моделей преобразования естественного языка в SQL-запросы. Этот ресурс содержит более 135 тысяч схем баз данных и свыше 500 тысяч проверенных комбинаций схемы, вопроса и запроса.
Проблема существующих решений
Несмотря на впечатляющие успехи больших языковых моделей в генерации SQL-кода из текста, большинство доступных датасетов содержат всего несколько тысяч примеров. Это серьезно ограничивает способность моделей обобщать знания для работы с новыми базами данных. Кроме того, многие существующие наборы данных используют упрощенные академические схемы с небольшим количеством таблиц и стандартизированными названиями, тогда как реальные производственные базы данных значительно сложнее и разнообразнее.
SQaLe создан для преодоления этих ограничений. Он предоставляет ресурс, достаточно большой для обучения языковых моделей, реалистичный для отражения реальной вариативности схем и тщательно проверенный, чтобы гарантировать выполнимость каждого SQL-запроса и его соответствие естественно-языковому вопросу.
Методология создания
Источник: huggingface.co
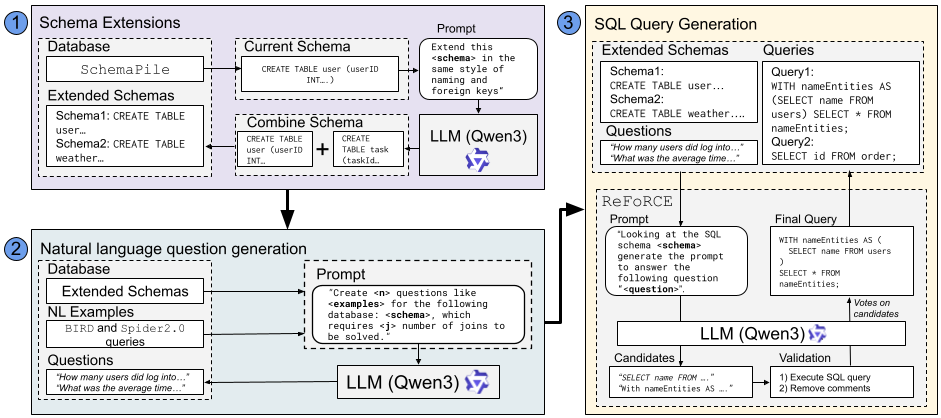
Процесс создания SQaLe состоял из трех основных этапов:
- Сбор и расширение схем: Исходные 22 989 схем из SchemaPile были расширены с помощью большой языковой модели с сохранением реалистичных названий, нормализации и структур внешних ключей. В результате получено 135 875 индивидуальных схем.
- Синтез вопросов: Для каждой схемы генерировались разнообразные вопросы на естественном языке на основе примеров из Spider 2.0 и BIRD. Вопросы варьировались по стилю и сложности.
- Генерация и валидация SQL: Кандидатные SQL-запросы создавались и проверялись через выполнение против соответствующих схем. Сохранялись только запросы, которые успешно выполнялись и семантически соответствовали вопросу.
Этот конвейер, выполнявшийся на сотнях GPU, произвел 517 676 проверенных триплетов, объединяющих информацию о схемах, вопросах и запросах.
Сравнительная характеристика
SQaLe значительно превосходит существующие датасеты по ключевым параметрам:
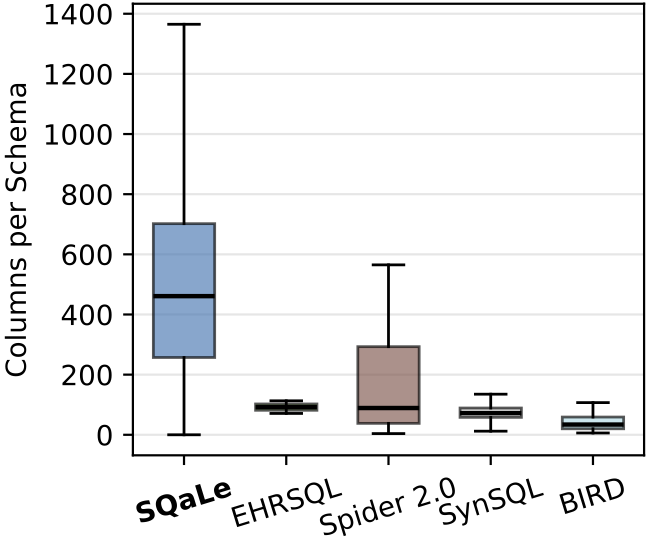
- 135 875 схем против 236 в Spider 2.0 и 80 в BIRD
- Медианное количество таблиц на схему: 91 против 7 в Spider 2.0
- Медианное количество колонок: 435 против 89 в Spider 2.0
- Более 13 миллионов внешних ключей
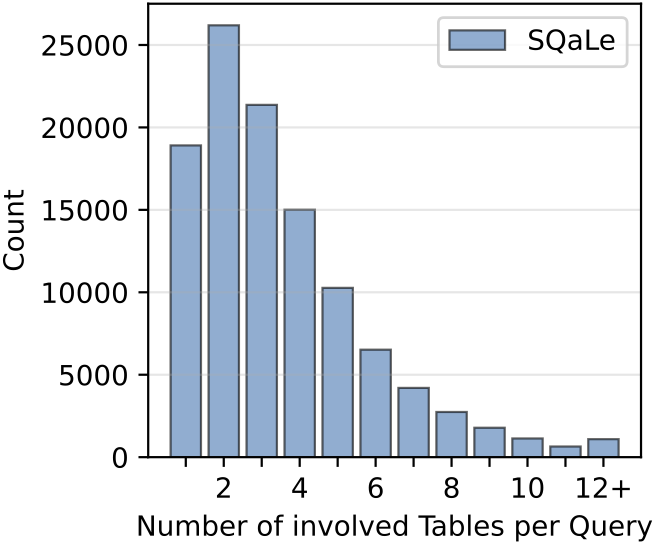
- 76% запросов содержат JOIN
Источник: huggingface.co
Источник: huggingface.co
Ключевые особенности
- Реалистичная сложность схем — от небольших однодоменных структур до крупных корпоративных систем
- Разнообразный состав запросов — агрегации, вложенные подзапросы, операции с множествами и сравнения
- Естественные вариации формулировок — вопросы отражают повседневный аналитический язык
- Выполняемые SQL-запросы — гарантируют соответствие между вопросом, схемой и запросом
Пример использования
Датасет можно загрузить непосредственно из библиотеки Hugging Face Datasets:
from datasets import load_dataset
dataset = load_dataset("trl-lab/SQaLe-text-to-SQL-dataset", split="train")
example = dataset[0]
print(example["schema"], example["question"], example["query"])
Каждая запись содержит полную схему базы данных, вопрос на естественном языке, соответствующий SQL-запрос и метаданные, такие как количество соединений и длина токенов.
Области применения
- Обучение и оценка моделей преобразования текста в SQL
- Исследования по пониманию схем, композиционному обобщению и анализу соединений
- Бенчмаркинг языковых моделей в реалистичных контекстах баз данных
- Создание поднаборов данных для фокусированных экспериментов
Появление SQaLe — это долгожданный шаг в решении фундаментальной проблемы text-to-SQL: недостатка реалистичных данных для обучения. Существующие датасеты давно стали слишком простыми для современных моделей, создавая иллюзию компетентности, которая разбивается о реальные производственные базы. Особенно впечатляет масштаб — более 135 тысяч схем против нескольких сотен в конкурентах. Однако стоит помнить, что даже такой объем — лишь начало. Настоящие enterprise-системы часто содержат тысячи таблиц со сложными бизнес-правилами, которые пока остаются за пределами доступных датасетов.
SQaLe представляет значительный прогресс в направлении реалистичных исследований text-to-SQL в крупных масштабах, но не является окончательным решением. Хотя его объем и разнообразие схем значительно превосходят существующие бенчмарки, он все еще не соответствует истинным требованиям к данным, необходимым для обучения и оценки следующего поколения очень больших моделей.
По материалам Hugging Face





Оставить комментарий