
Оглавление
Генеративный искусственный интеллект кардинально меняет музыкальную индустрию, позволяя создателям любого уровня навыков генерировать студийные треки с помощью фундаментальных моделей, которые персонализируют композиции в реальном времени. По мере роста спроса на уникальный контент и поиска более умных инструментов, Splash Music совместно с AWS разработала и масштабировала музыкальные генеративные модели, сделав профессиональное создание музыки доступным для миллионов пользователей.
Вызовы масштабирования музыкальной генерации
Splash Music уже обеспечила более 600 миллионов прослушиваний по всему миру, предоставляя пользователям инструменты, адаптирующиеся к их вкусам и стилям. Однако создание технологии для реализации этой творческой свободы требовало решения нескольких ключевых проблем:
- Сложность и масштаб модели – компания разработала HummingLM, передовую модель с миллиардами параметров, специально созданную для генеративной музыки. Модель спроектирована для захвата тонкостей человеческого напевания, преобразуя творческие идеи в музыкальные треки. Для достижения студийного качества потребовалось значительное увеличение вычислительной мощности и хранилища.
- Быстрые темпы изменений – стремительное развитие искусственного интеллекта требует постоянной адаптации, дообучения и развертывания новых моделей для соответствия ожиданиям пользователей.
- Масштабирование инфраструктуры – управление крупными кластерами в жизненном цикле разработки моделей сопровождалось непредсказуемыми затратами, частыми прерываниями и трудоемким ручным управлением.
Обзор HummingLM: фундаментальная модель Splash Music
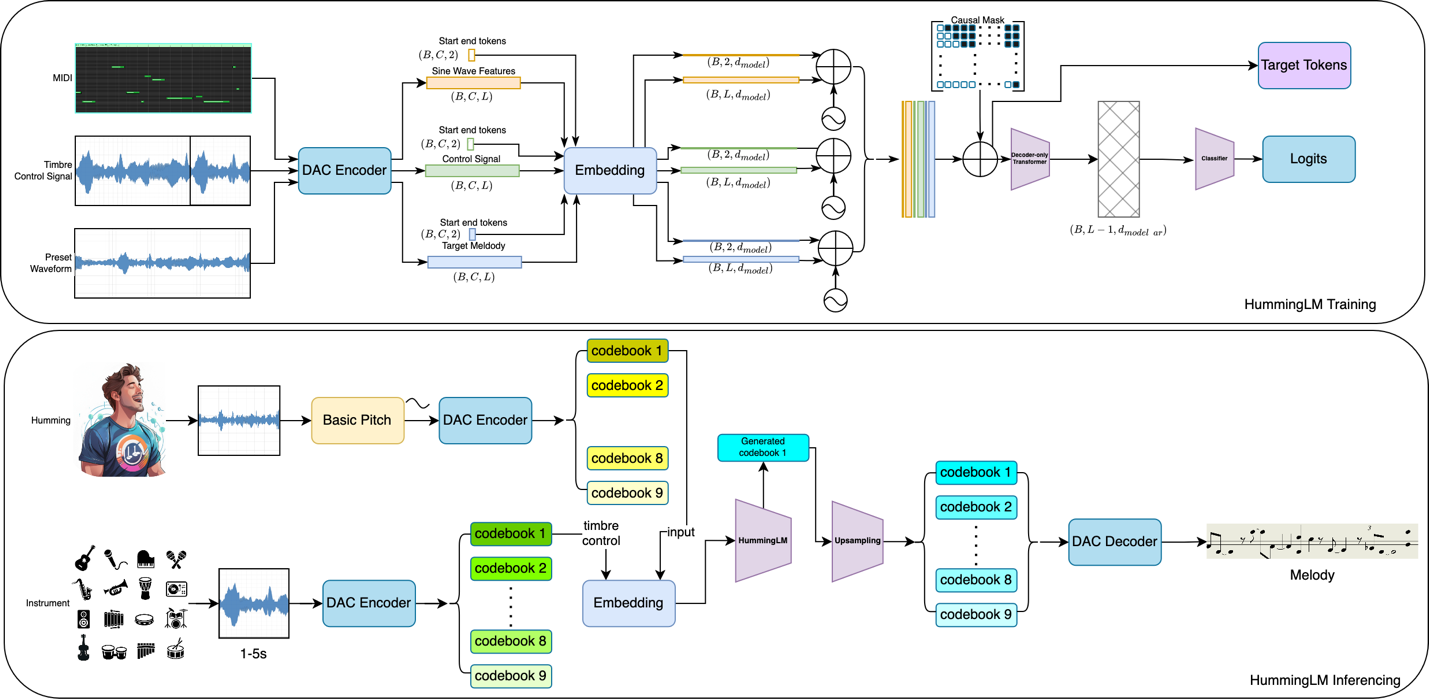
HummingLM представляет собой проприетарную мультимодальную генеративную модель, разработанную в тесном сотрудничестве с AWS Generative AI Innovation Center. Архитектура модели построена вокруг трансформерной языковой модели, соединенной со специализированным музыкальным апсемплером:
- HummingLM использует аудиокодирование Descript-Audio-Codec (DAC) для получения сжатых аудиопредставлений, захватывающих частотные и тембровые характеристики
- Система преобразует напеваемые мелодии в профессиональные инструментальные исполнения без явного обучения представлению тембра
Инновация заключается в том, как HummingLM объединяет эти потоки токенов. Используя трансформерную основу, модель учится смешивать мелодическое намерение из напевания со стилистическими и структурными сигналами от звука инструмента. Пользователи могут напевать мелодию, добавить сигнал управления инструментом и получить полностью аранжированный высококачественный трек.
Архитектура HummingLM спроектирована для эффективности и выразительности. Используя дискретные токенные представления, модель достигает более быстрой сходимости и сниженных вычислительных затрат по сравнению с традиционными подходами на основе волновых форм.
Следующая диаграмма иллюстрирует, как обучается HummingLM и процесс вывода для генерации высококачественной музыки:
Решение: ускорение разработки моделей с AWS Trainium на Amazon SageMaker HyperPod
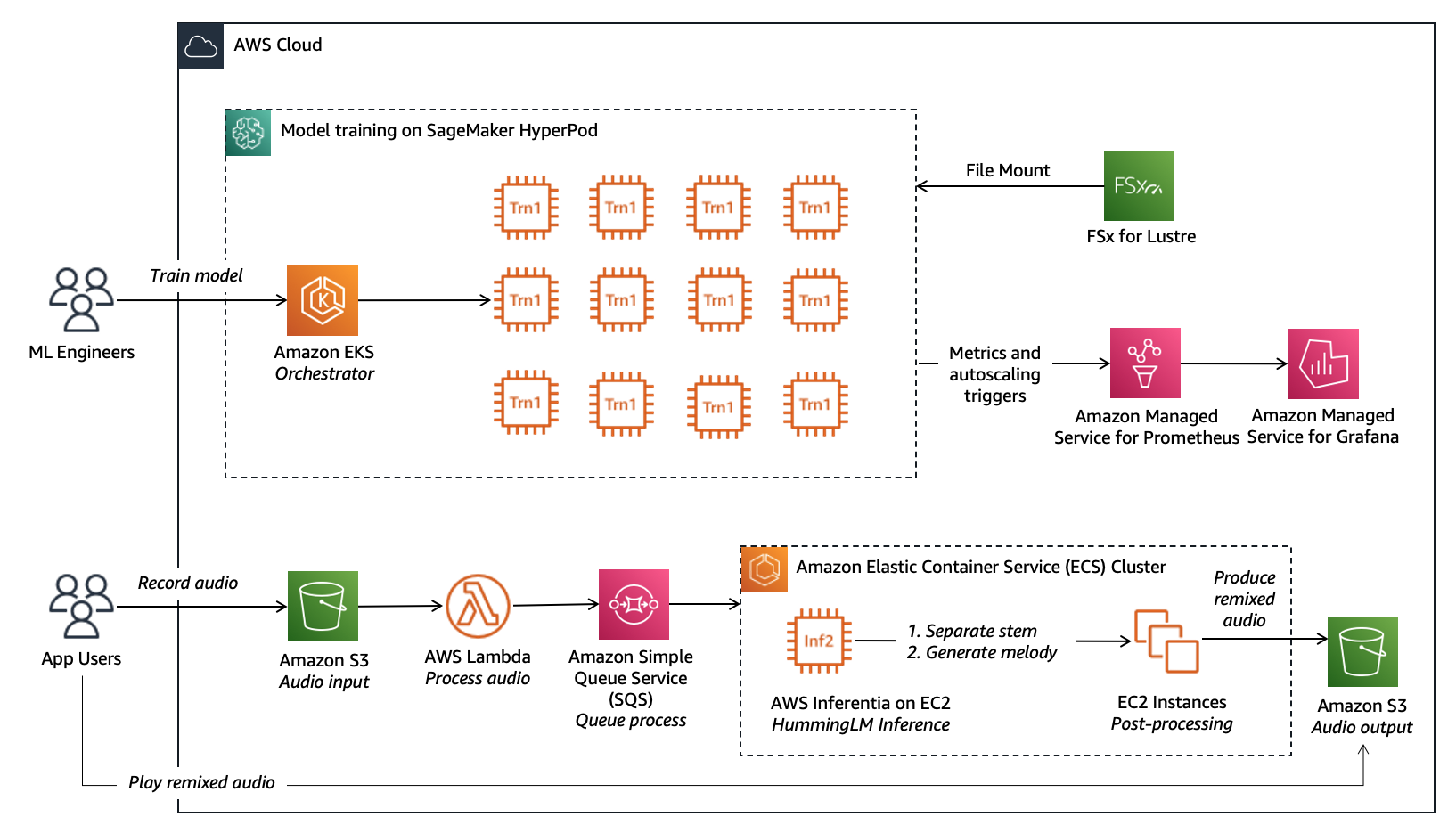
Splash Music сотрудничала с GenAIIC для развития своей фундаментальной модели HummingLM, используя комбинированные возможности Amazon SageMaker HyperPod и чипов AWS Trainium для обучения моделей.
Архитектура Splash Music следует лучшим практикам SageMaker HyperPod, используя Amazon Elastic Kubernetes Service (EKS) в качестве оркестратора, FSx for Lustre для хранения более 2 ПБ данных и экземпляры EC2 на базе AWS Trainium для ускорения. Следующая диаграмма иллюстрирует архитектуру решения:
Интересно наблюдать, как специализированные AI-чипы вроде Trainium начинают вытеснять традиционные GPU даже в таких творческих областях, как генерация музыки. Технически впечатляет подход с дискретными токенными представлениями — это действительно снижает вычислительную сложность по сравнению с работой напрямую с волновыми формами. Хотя остается вопрос: насколько такие модели действительно понимают музыку, а не просто статистически воспроизводят паттерны.
В следующих разделах мы рассмотрим каждый этап жизненного цикла разработки модели, от подготовки набора данных до компиляции для оптимизированного вывода.
Подготовка набора данных
Эффективная подготовка и обработка крупномасштабных аудиоданных является критически важным этапом для обучения качественных музыкальных моделей. Использование инфраструктуры AWS позволяет автоматизировать и ускорить эти процессы.
По сообщению AWS Machine Learning Blog, сотрудничество с AWS позволило Splash Music значительно ускорить инновации и сократить жизненный цикл разработки своих музыкальных генеративных моделей.





Оставить комментарий