
Оглавление
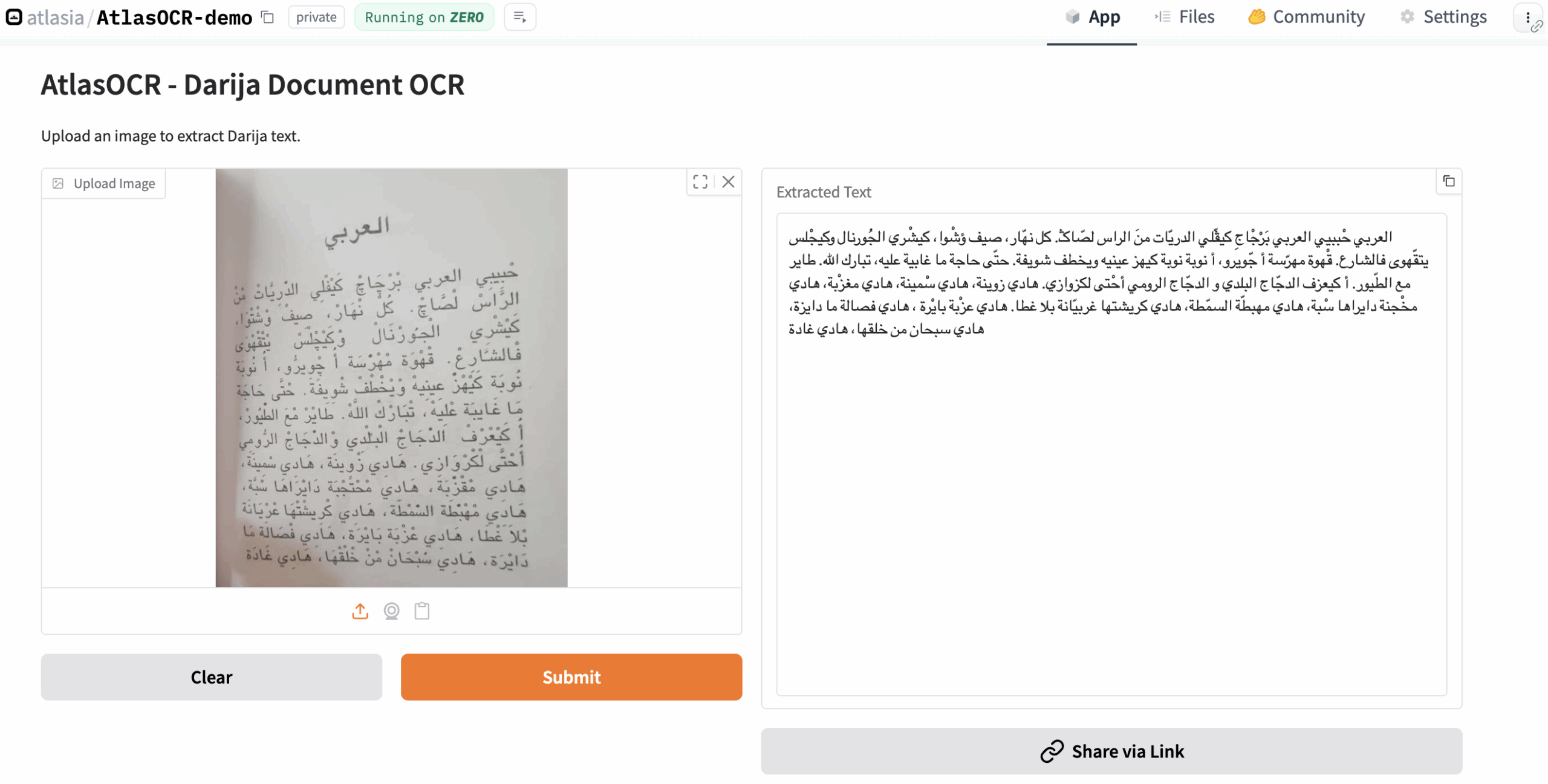
Команда разработчиков представила AtlasOCR — первую открытую модель оптического распознавания текста для марокканского диалекта арабского языка Darija. Модель размером 3 миллиарда параметров построена на базе Vision Language Model и демонстрирует передовые результаты в обработке текстов на этом ранее недоступном для автоматического анализа языке.
Практическое применение AtlasOCR
Использовать модель можно через Hugging Face Space или локально с помощью следующего кода:
from unsloth import FastVisionModel
from PIL import Image
from transformers import TextStreamer
image = Image.open("path/to/your/image.jpg")
model, processor = FastVisionModel.from_pretrained(
"atlasia/AtlasOCR",
device_map="cuda:0",
load_in_4bit=False,
use_gradient_checkpointing="unsloth"
)
FastVisionModel.for_inference(model)
prompt = ("Below is the image of one page of a document written in arabic."
"Just return the plain text representation of this document as if you were reading it naturally. Do not hallucinate.")
messages = [\
{"role": "user", "content": [\
{"type": "image"},
{"type": "text", "text": prompt}
]}
]
input_text = processor.apply_chat_template(messages, add_generation_prompt = True)
inputs = processor(
image,
input_text,
add_special_tokens = False,
return_tensors = "pt",
).to("cuda")
text_streamer = TextStreamer(processor, skip_prompt = True)
_ = model.generate(**inputs, streamer = text_streamer,
use_cache = True, temperature = 1.5, min_p = 0.1)
Значение проекта для цифровой сохранности языка
Darija, марокканский диалект арабского языка, богат визуальным контентом — от постов в соцсетях до рукописных заметок. Однако отсутствие специализированных OCR-инструментов создавало серьезные барьеры для разработчиков и организаций, работающих с марокканским контентом.
Утилитарная ценность OCR для Darija выходит далеко за рамки академического интереса:
- Цифровая сохранность: конвертация исторических документов и манускриптов
- Анализ соцсетей: понимание публичного дискурса и сентимента
- Доступность: обеспечение доступности визуального контента для скринридеров
- Исследования: возможность масштабного текстового анализа марокканского контента
Пока крупные игроки соревнуются в создании универсальных мультиязычных моделей, нишевые решения для конкретных диалектов часто оказываются более эффективными. AtlasOCR — прекрасный пример того, как целенаправленный подход побеждает грубую силу в задачах обработки низкоресурсных языков.
Архитектура Vision Language Models
Vision-language models (VLMs) принимают изображения и текст на вход и генерируют текст на выходе. Они превосходно справляются с генерализацией в режиме zero-shot и поддерживают широкий спектр приложений: визуальные вопросно-ответные системы, понимание документов, генерация подписей к изображениям и интерактивные диалоги о картинках.
Архитектура VLM состоит из трех основных компонентов:
- Визуальный энкодер: преобразует изображение/видео в векторное представление, инкапсулирующее визуальные свойства типа цвета, форм и т.д.
- Модуль проекции модальностей: выравнивает визуальные признаки из предыдущих представлений с пространством представления языковой модели
- Языковая модель: принимает выровненные представления, интегрирует их с текстовым вводом и генерирует осмысленные выходы на естественном языке
Подготовка данных: синтетика и реальный контент
Создание масштабного OCR-датасета для марокканского Darija означало решение одной большой проблемы: реального разнообразия. Целью было захватить это разнообразие при обеспечении достаточного масштаба и качества для обучения надежных моделей.
Для этого комбинировались два взаимодополняющих подхода: синтетическая генерация с помощью собственной библиотеки OCRSmith и тщательно отобранные реальные данные из книг, документов и онлайн-источников.
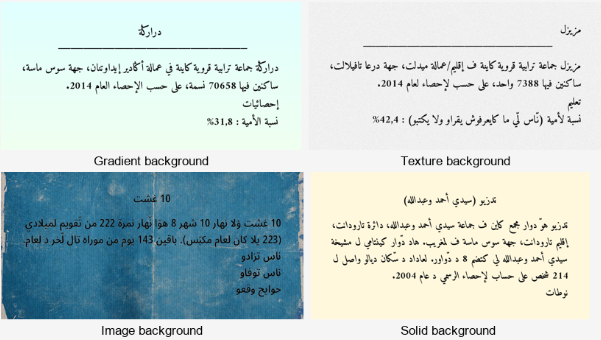
OCRSmith: инструмент для генерации синтетических OCR-данных
Создание высококачественных аннотаций для Darija — трудоемкий и дорогой процесс. Синтетические данные предложили способ быстрого продвижения при сохранении разнообразия. С OCRSmith, нашим opensource инструментарием, мы могли симулировать реальные условия — шрифты, макеты, фоны, искажения — и мгновенно генерировать десятки тысяч размеченных изображений с ограничивающими рамками и метаданными.
Реальные источники данных
Синтетические данные дали масштаб, но реальные изображения дали аутентичность. Мы подобрали широкий микс Darija текста из разных контекстов:
- Сканированные книги: редкие издания на Darija, включая работы Мохаммеда Эль-Мадлауи Эль-Мунабхи и Фарука Эль-Марракчи
- Онлайн-контент: посты из соцсетей, блоги, форумы
- Рукописные материалы: заметки, письма, документы
По материалам Hugging Face Blog





Оставить комментарий