Оглавление
Исследователи из Scale AI разработали новый фреймворк Rubrics as Rewards (RaR), который использует детализированные чек-листы вместо упрощенных оценок «хорошо/плохо» для обучения языковых моделей. Этот подход позволяет моделям понимать, почему ответ считается качественным, а не просто имитировать успешные шаблоны.
Проблемы традиционных методов обучения
Метод обучения с подкреплением на основе человеческих предпочтений (RLHF) страдает от непрозрачных функций вознаграждения, склонных к ложным корреляциям — модели учатся быть убедительными за счет поверхностных качеств, а не глубинного понимания. Альтернативный подход RLVR эффективен для объективных задач вроде математики или программирования, но не подходит для субъективных областей вроде медицины или науки.
Как работает система рубрик
Эффективность RaR зависит от качества самих рубрик, которые строятся по четырем принципам:
- Экспертная основа: рубрики создаются на основе эталонных ответов людей или продвинутых ИИ
- Полное покрытие: учитываются точность фактов, логическая структура и типичные ошибки
- Семантическое взвешивание: каждый критерий имеет приоритет («Важно», «Критично»)
- Самостоятельность: пункты можно оценивать изолированно без дополнительного контекста
Обучение происходит по алгоритму GRPO: модель генерирует ответы, получает оценку по рубрике и сразу обновляется. Ключевое открытие — неявная агрегация (холистическая оценка эксперта) работает лучше явной (механический подсчет баллов).
Проверка на реальных данных
Для тестирования создали два масштабных датасета:
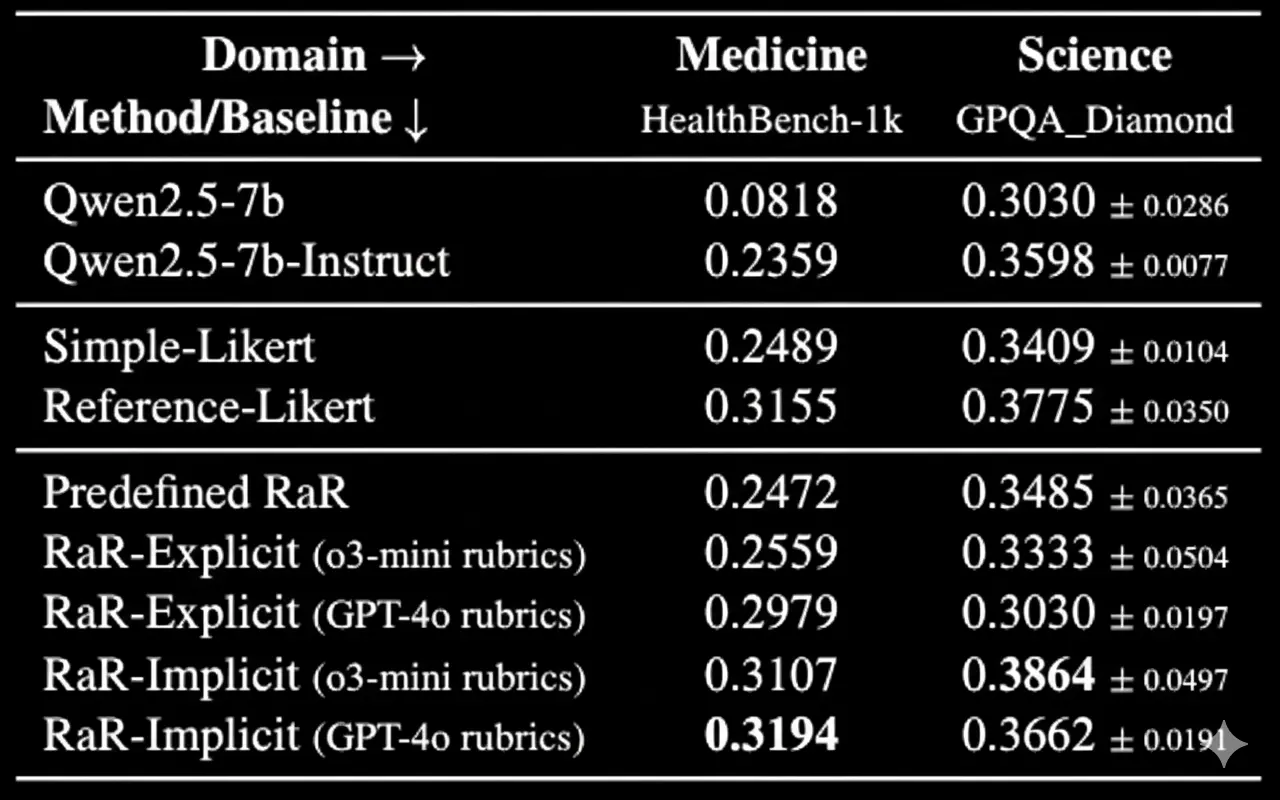
- RaR-Medicine-20k: 20,000 медицинских промптов с акцентом на диагностику (50.3%) и лечение
- RaR-Science-20k</a]: 20,000 научных промптов уровня GPQA Diamond по квантовой механике и биологии
Результаты и эффективность

Метод RaR-Implicit показал 28% улучшение на медицинском бенчмарке HealthBench-1k по сравнению с базовыми методами. Рубрики также делают оценку более эффективной: небольшие модели-судьи с рубриками работают на уровне крупных моделей без них.
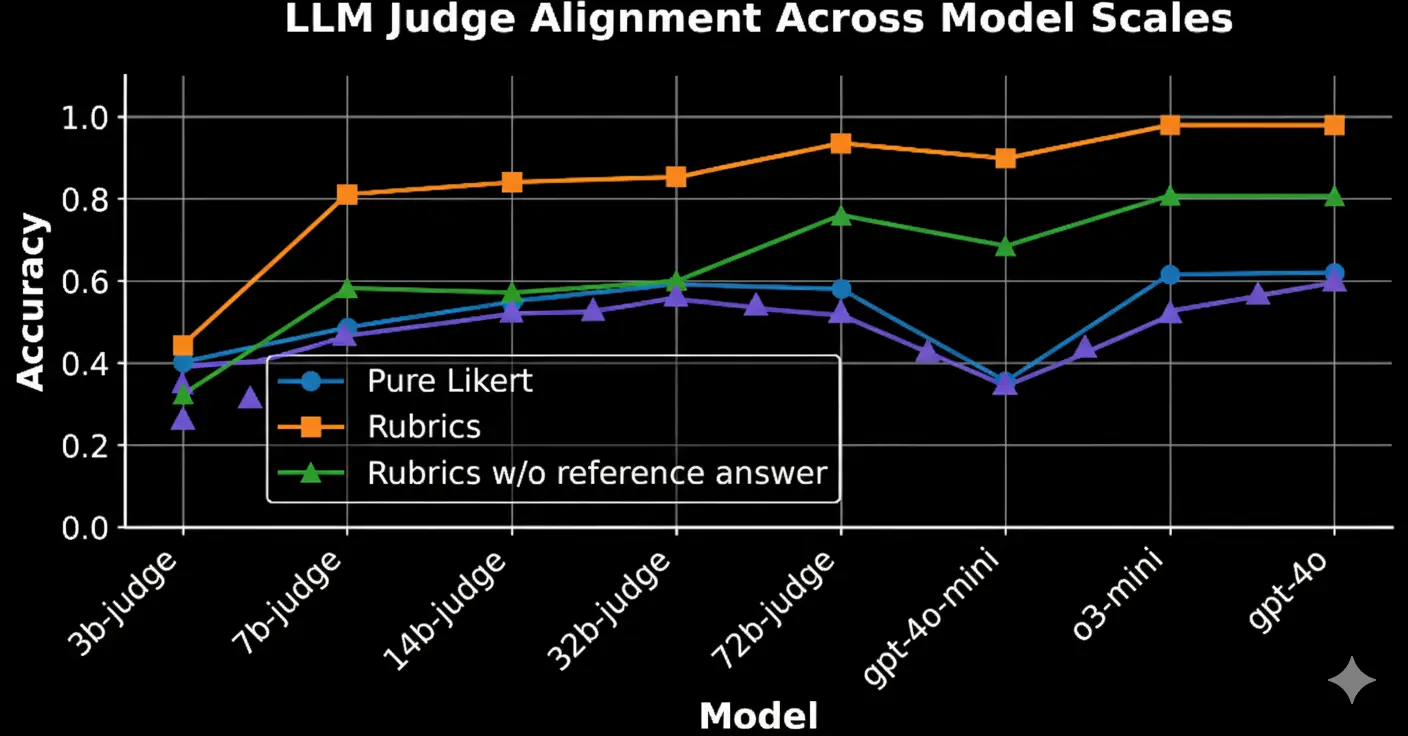
Это именно тот тип работы, который двигает индустрию вперед — вместо черного ящика с наградами мы получаем прозрачную систему критериев. Интересно, что экспертные рубрики от людей все равно превосходят AI-генерированные, что напоминает: настоящий интеллект пока не заменить. Вопрос в масштабировании — сколько экспертов нужно для покрытия всех предметных областей?
Будущее обучения ИИ
RaR представляет собой сдвиг парадигмы: от сбора простых предпочтений к архитектуре экспертных критериев оценки. Метод особенно полезен против взлома вознаграждения и для обучения агентов на сложных многошаговых задачах, где награды редки и распределены во времени.
По материалам Scale.





Оставить комментарий