Команда Salesforce AI Platform раскрыла детали совместного с AWS решения проблемы неэффективного использования GPU при работе с крупными языковыми моделями. Как сообщает AWS Machine Learning Blog, ключевой проблемой было нерациональное распределение ресурсов: большие модели (20-30 ГБ) с низким трафиком простаивали на мощных мульти-GPU инстансах, в то время как средние модели (около 15 ГБ) с высокой нагрузкой требовали избыточного выделения ресурсов.
Технические вызовы инфраструктуры
Salesforce развертывает проприетарные LLM вроде CodeGen и XGen на инстансах Amazon EC2 P4d (с планами перехода на P5en с NVIDIA H200). Основная сложность заключалась в дисбалансе:
- Крупные модели занимали несколько GPU, но не использовали их полностью
- Модели среднего размера требовали низкой задержки, что вело к избыточному выделению ресурсов
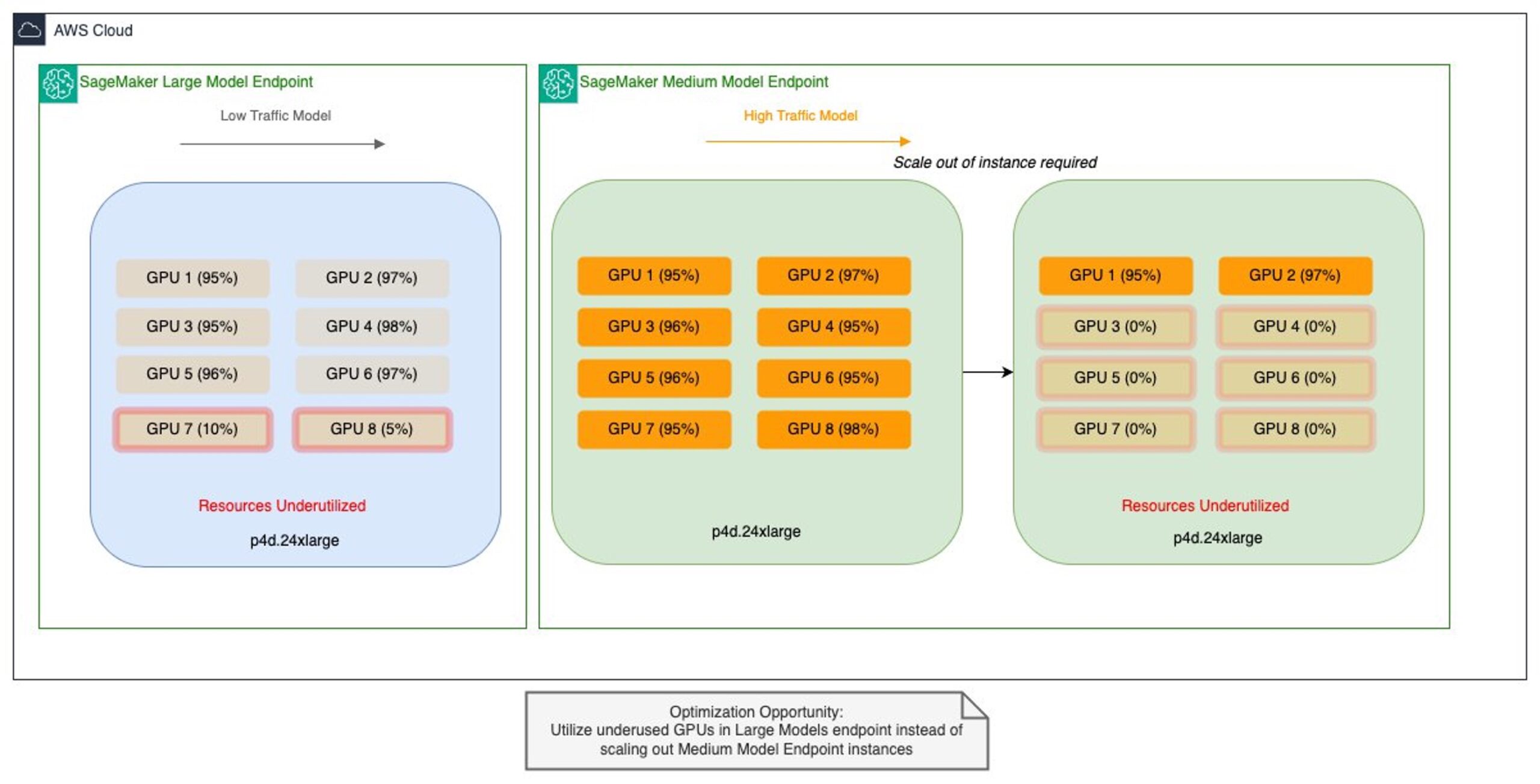
Решение через компоненты инференса SageMaker
Технология SageMaker Inference Components позволила размещать несколько моделей на одном эндпоинте с детальным контролем ресурсов. Ключевые преимущества:
- Динамическое распределение GPU и памяти между моделями
- Индивидуальные политики масштабирования для каждой модели
- Автоматическая оптимизация размещения моделей на инстансах
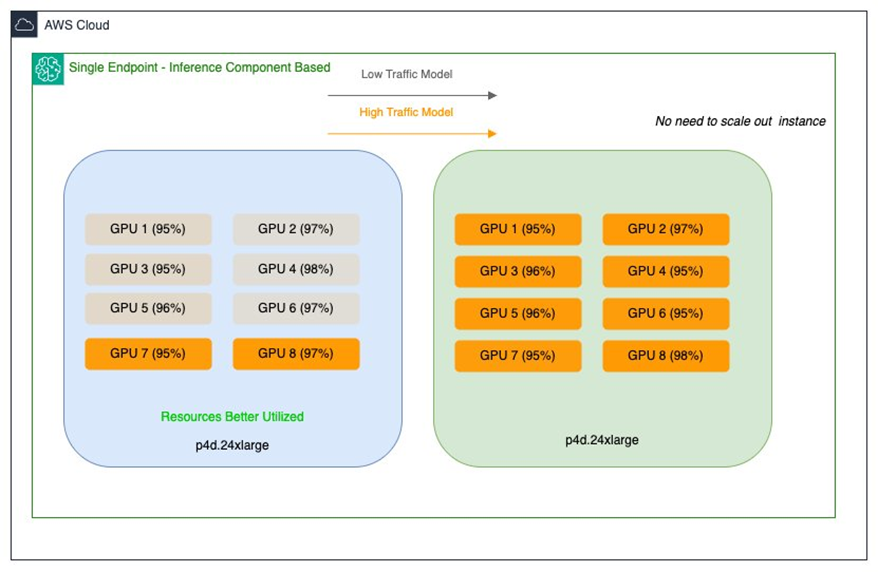
Это устранило проблему «шахматного» распределения моделей по изолированным эндпоинтам. По заявлению Salesforce, подход снизил затраты на инференс в 8 раз для некоторых сценариев.
Решение AWS закрывает критически важный пробел в MLOps — проблему «оскудения GPU», когда дорогостоящие ускорители простаивают из-за статичного выделения ресурсов. Хотя контейнерная оркестрация моделей не нова, SageMaker Inference Components предлагают именно тот уровень гранулярности, который нужен для LLM с их непредсказуемыми паттернами нагрузки. Особенно впечатляет поддержка гетерогенных моделей в одном эндпоинте — это прямой ответ на реальные потребности компаний, развертывающих десятки специализированных LLM. Однако стоит отметить: заявленная 8-кратная экономия достижима лишь при идеальном балансировании нагрузки, что требует глубокой интеграции с мониторингом. Для многих команд переход к такой архитектуре потребует пересмотра пайплайнов развертывания.
По материалам: AWS Machine Learning Blog





Оставить комментарий