
Оглавление
Компания RunwayML разработала инновационную диффузионную визуально-языковую модель A2D-VL 7B, которая преобразует существующие авторегрессионные модели в параллельные диффузионные декодеры. Этот подход позволяет достичь компромисса между скоростью и качеством генерации без необходимости обучения с нуля.
Проблемы существующих диффузионных моделей
Визуально-языковые модели (VLM) анализируют изображения и видео через языковое взаимодействие, обеспечивая работу таких приложений, как генерация подписей к изображениям и визуальные вопросы-ответы. Традиционные авторегрессионные VLM генерируют токены последовательно, что исключает параллелизацию и ограничивает пропускную способность вывода.
Существующие диффузионные VLM сталкиваются с несколькими серьезными проблемами:
- Высокая стоимость обучения — диффузионное языковое моделирование требует до 16 раз больше вычислительных ресурсов по сравнению с предсказанием следующего токена
- Устаревшие архитектуры — отсутствие поддержки современных компонентов, таких как нативные визуальные разрешения и мультимодальные позиционные кодирования
- Деградация качества в длинных ответах — качество генерации ухудшается при создании развернутых текстов
- Отсутствие KV кэширования — затрудняет эффективное вычисление внимания
Инновационный подход A2D-VL
Модель A2D-VL 7B создана путем дообучения существующей авторегрессионной модели Qwen2.5-VL на задаче диффузионного языкового моделирования. Исследователи применили маскированный диффузионный фреймворк, где токены «зашумляются» через маскирование и «очищаются» через предсказание оригинальных токенов.
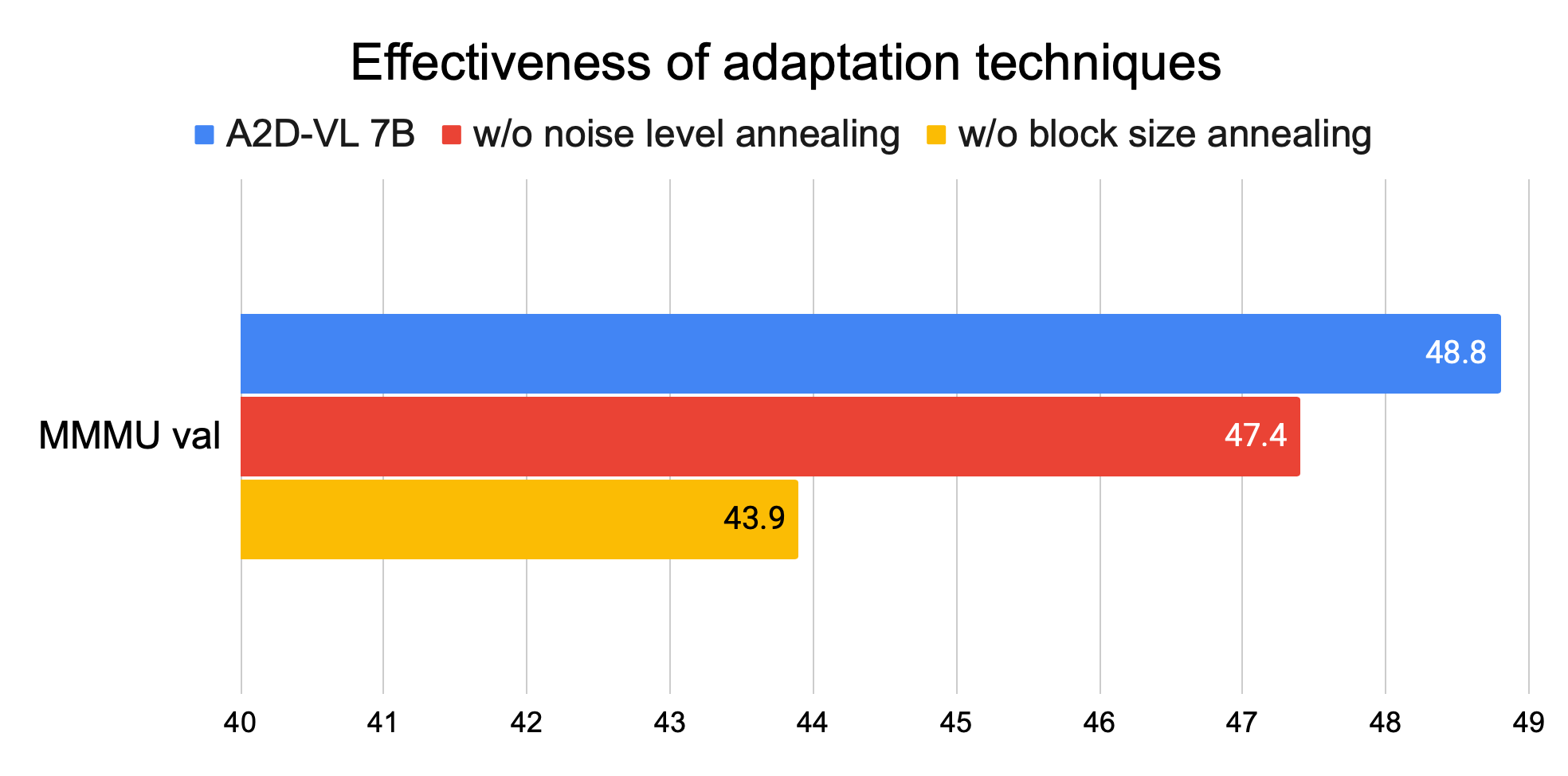
Ключевые адаптационные техники включают:
- Аннелинг размера блоков — постепенное увеличение окна предсказания диффузии
- Аннелинг уровня шума — позиционно-зависимое маскирование для плавного перехода между задачами
Переход от последовательной к параллельной генерации — это как перейти от ручной сборки к конвейерному производству. Техника аннелинга напоминает обучение с постепенным увеличением сложности: сначала модель учится предсказывать короткие последовательности, затем переходит к полноценной параллельной генерации. Особенно впечатляет экономия данных — 400 тысяч пар против 12 миллионов у конкурентов. Это демонстрирует, что эффективное преобразование архитектур возможно без колоссальных вычислительных затрат.
Преимущества новой архитектуры
Модель A2D-VL 7B демонстрирует значительные улучшения по сравнению с предыдущими решениями:
- Эффективное обучение — требуется всего 400 тысяч визуальных пар вопросов-ответов против 12+ миллионов у LLaDA-V 8B
- Современная архитектура — унаследовала современные компоненты Qwen2.5-VL
- Улучшенное качество длинных ответов — использование диффузионного декодирования блоками по 8 токенов
Диффузионные языковые модели предлагают гибкий компромисс между скоростью и качеством. Ключевым элементом управления этим балансом является порог уверенности, который адаптивно контролирует параллелизм. При высоком пороге уверенности (например, 90%) модель отдает приоритет точности, генерируя несколько токенов только при высокой уверенности. При низком пороге (например, 30%) она отдает приоритет скорости, допуская большую неопределенность для достижения большего параллелизма.
По материалам RunwayML





Оставить комментарий