Оглавление
Квантование — это набор методов для уменьшения точности представления чисел в моделях глубокого обучения, что позволяет сократить их размер и ускорить обучение. По сообщению Hugging Face, современные подходы к квантованию открывают новые возможности для развертывания больших языковых моделей на ограниченном железе.
Что такое точность и зачем нужно квантование
Точность определяет количество значащих цифр или битов, используемых для представления числа. В глубоком обучении веса обычно представляются в формате с плавающей точкой (FP32/16/8). Хотя FP32 обеспечивает высокую точность, это приводит к увеличению размера модели и замедлению вычислений.
Простой метод квантования — масштабирование большего диапазона типа данных к меньшему, например, из FP32 в int8:
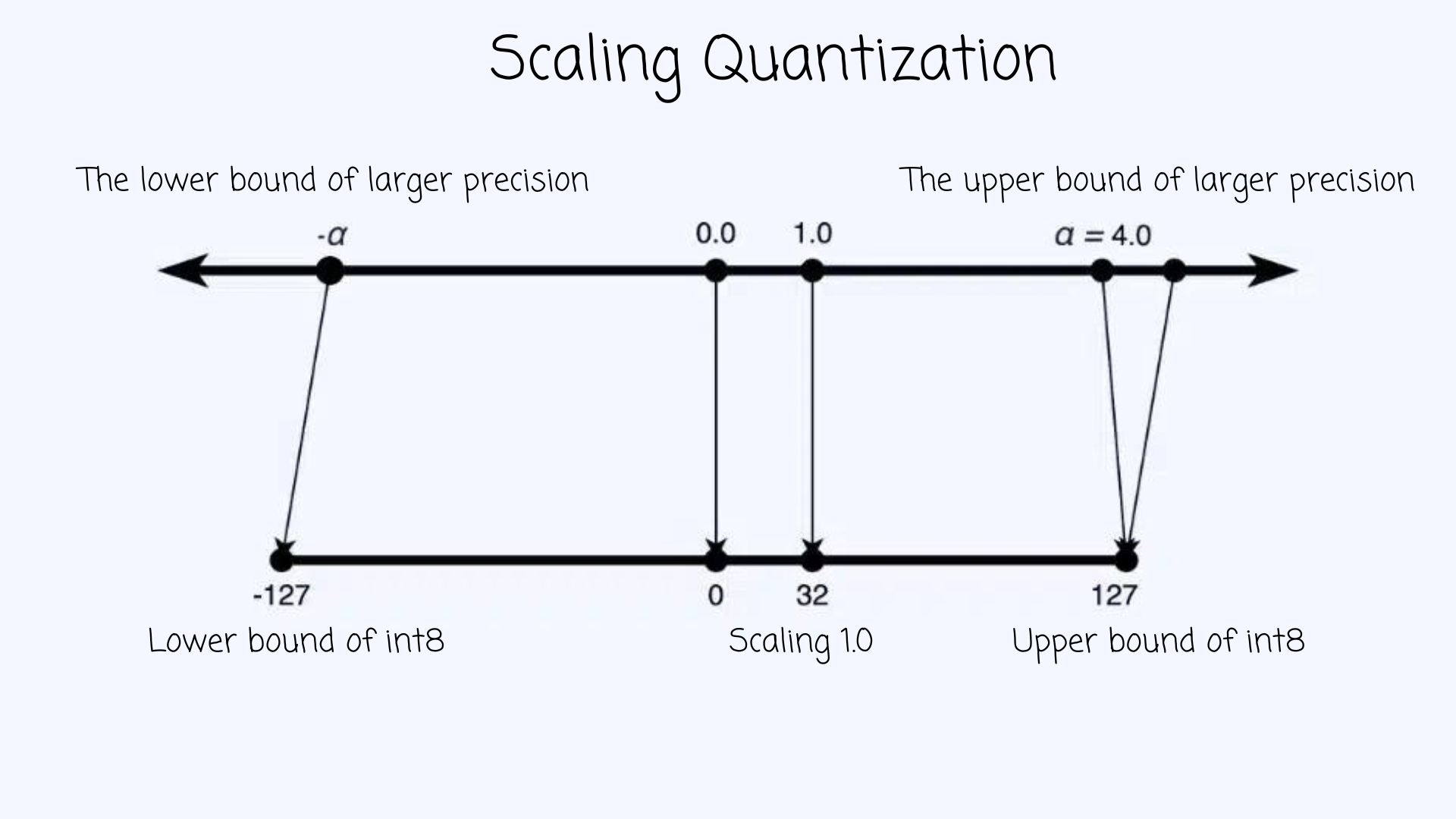
Существует два основных подхода:
- Квантование после обучения — уменьшение точности уже обученной модели
- Квантование во время обучения — позволяет дообучить модель для снижения потерь от квантования
Современные методы квантования — это не просто компрессия, а сложная инженерия, требующая глубокого понимания математики и аппаратных ограничений. GPTQ и bitsandbytes демонстрируют, как можно сохранить 95-99% производительности при 4-кратном уменьшении размера модели.
GPTQ квантование
GPTQ — это метод пост-обучающего квантования, который использует калибровочный датасет для нахождения сжатой версии весов с минимальной среднеквадратичной ошибкой. Основное преимущество — одновременное сокращение памяти и ускорение вывода.
Библиотека AutoGPTQ интегрирована в экосистему и позволяет:
- Запускать готовые GPTQ-модели с Hugging Face Hub
- Квантовать любые модели transformers
- Дообучать квантованные модели с помощью PEFT
- Обслуживать модели через текстовый интерфейс
Пример установки и использования:
pip install auto-gptq pip install transformers optimum peft
from transformers import AutoModelForCausalLM, AutoTokenizer, GPTQConfig model_id = "facebook/opt-125m" tokenizer = AutoTokenizer.from_pretrained(model_id) quantization_config = GPTQConfig(bits=4, dataset = "c4", tokenizer=tokenizer) model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto", quantization_config=quantization_config)
4/8-битное квантование с bitsandbytes
Библиотека bitsandbytes применяет 8-битное и 4-битное квантование как во время обучения, так и перед выводом. 8-битное квантование работает по трехэтапному процессу:

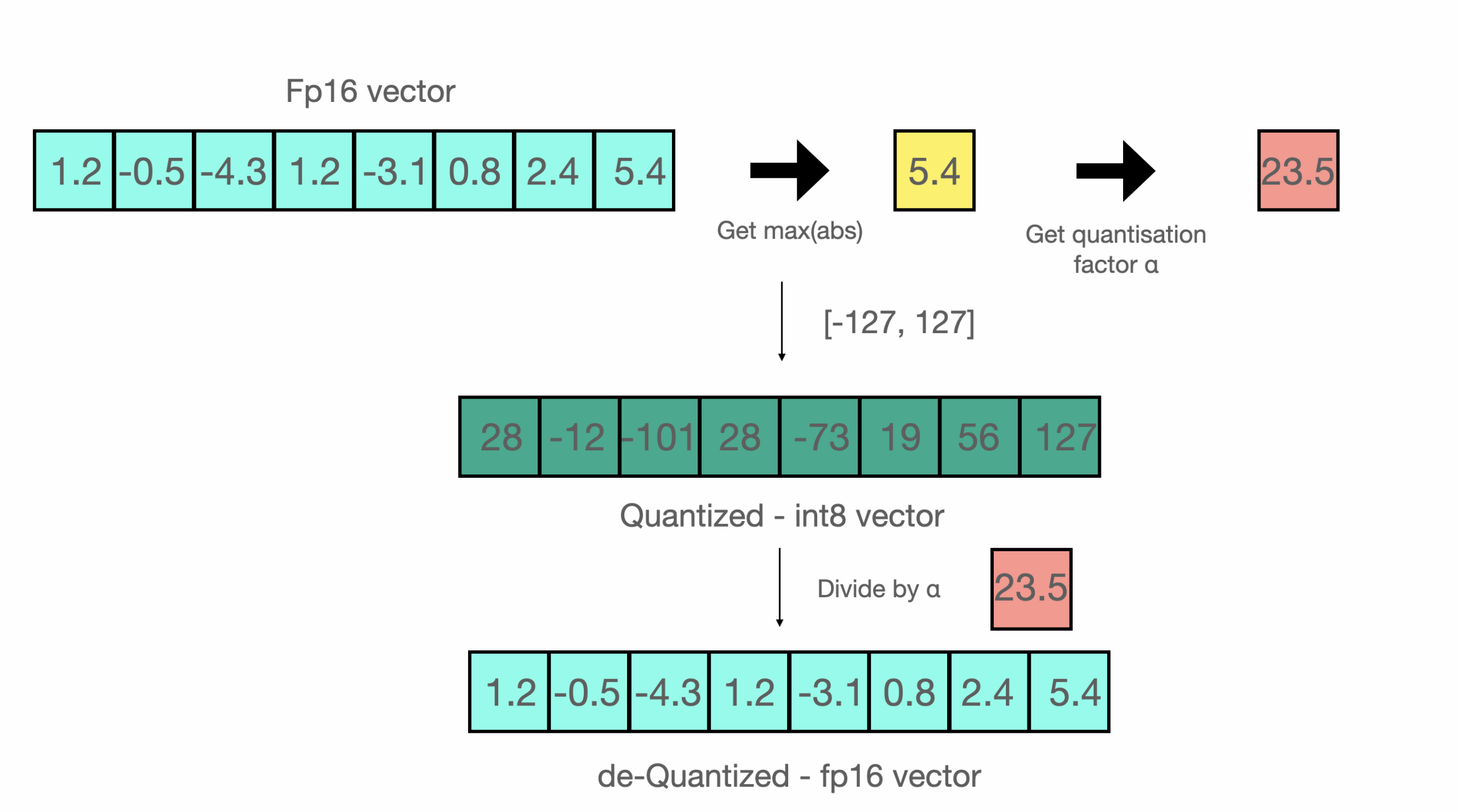
Установка и использование:
pip install bitsandbytes
from transformers import AutoModelForCausalLM, AutoTokenizer import torch model_8bit = AutoModelForCausalLM.from_pretrained(name, device_map="auto", load_in_8bit=True) tokenizer = AutoTokenizer.from_pretrained(name) encoded_input = tokenizer(text, return_tensors='pt') output_sequences = model.generate(input_ids=encoded_input['input_ids'].cuda()) print(tokenizer.decode(output_sequences[0], skip_special_tokens=True))
Важное замечание: 4-битный NormalFloat (NF4), представленный в статье QLoRA, показывает лучшую производительность по сравнению с FP4, но требует тщательной калибровки.
Хотя bitsandbytes обеспечивает значительное сокращение памяти, скорость вывода может быть ниже по сравнению с GPTQ, что создает пространство для дальнейшей оптимизации методов квантования.





Оставить комментарий