
Оглавление
Консорциум исследователей из Hugging Face, Nvidia, Кембриджского университета и Mistral AI представил Open ASR Leaderboard — первую масштабную платформу для сравнительного анализа систем автоматического распознавания речи. Как сообщает The Decoder, в тестировании участвовали более 60 моделей от 18 компаний, включая как открытые, так и коммерческие решения.
Методология оценки
Платформа оценивает модели по трем ключевым направлениям: транскрипция на английском языке, многоязычное распознавание (немецкий, французский, итальянский, испанский, португальский) и работа с длинными аудиофайлами свыше 30 секунд. Для объективности сравнения используются две основные метрики:
- Word Error Rate (WER) — процент словесных ошибок (чем меньше, тем лучше)
- Inverse Real-Time Factor (RTFx) — коэффициент скорости обработки
Перед оценкой все транскрипции нормализуются: удаляются пунктуация и заглавные буквы, числа записываются словами, исключаются слова-паразиты. Этот стандарт соответствует подходу, используемому в OpenAI Whisper.
Компромисс между точностью и скоростью
Результаты демонстрируют четкую зависимость: системы на основе больших языковых моделей показывают наивысшую точность, но требуют больше времени на обработку. Лидером в английской транскрипции стала модель Nvidia Canary Qwen 2.5B с показателем WER 5,63%.
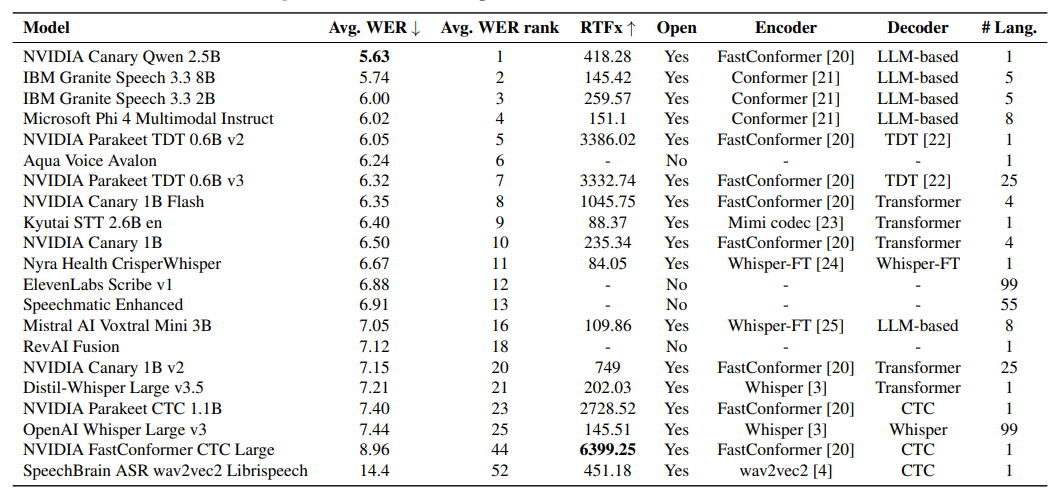
При этом более простые архитектуры вроде Nvidia Parakeet CTC 1.1B обрабатывают аудио в 2728 раз быстрее реального времени, но занимают лишь 23-е место по точности.
Классическая дилемма машинного обучения — точность против скорости — здесь проявляется в полной мере. Интересно, что индустрия до сих пор не нашла серебряной пули: либо жертвуешь качеством ради мгновенного отклика, либо терпишь задержки ради идеальной транскрипции. Особенно забавно, что в эпоху LLM простые модели всё ещё находят свою нишу там, где каждая миллисекунда на счету.
Многоязычные модели теряют в специализации
Тесты на нескольких языках подтвердили ожидаемый компромисс: узкоспециализированные модели, обученные на одном языке, превосходят универсальные решения в своей области, но беспомощны за её пределами. Например, Whisper-модели, тренированные только на английском, обходят мультиязычный Whisper Large v3 в английской транскрипции, но не справляются с другими языками.
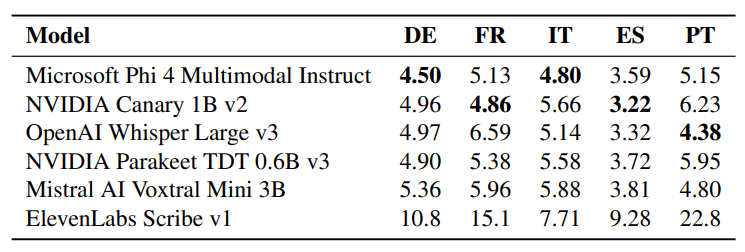
В мультиязычных тестах лидирует Microsoft Phi-4 multimodal instruct в немецком и итальянском. Nvidia Parakeet TDT v3 поддерживает 25 языков против одного у версии v2, но более широкая модель показывает худшие результаты на английском по сравнению со специализированной.
Открытый код против коммерческих решений
На коротких аудиозаписях открытые модели занимают верхние позиции рейтинга. Лучшая коммерческая система Aqua Voice Avalon находится лишь на шестом месте. Сравнение скорости платных сервисов не вполне объективно — на результаты влияют факторы вроде времени загрузки файлов.
На длинных аудио коммерческие провайдеры демонстрируют преимущество: Elevenlabs Scribe v1 (4,33% WER) и RevAI Fusion (5,04%) возглавляют список благодаря оптимизации под длинный контент и развитой инфраструктуре.
Весь код и данные проекта доступны на GitHub, а датасеты размещены в Hugging Face Hub. Разработчики могут добавлять новые модели через скрипты, работающие с официальным тестовым набором.
В будущих обновлениях планируется добавить больше языков, приложений и метрик, включая тестирование новых комбинаций системных компонентов. С распространением больших языковых моделей ожидается, что всё больше систем распознавания речи будут использовать эту технологию.





Оставить комментарий