
Оглавление
На Hugging Face вышел новый материал о том, как современные модели компьютерного зрения радикально изменили возможности обработки документов. Открытые модели предлагают лучшую экономическую эффективность и конфиденциальность данных по сравнению с проприетарными решениями.
Эволюция OCR: от простого текста к сложным документам
Оптическое распознавание символов (OCR) — одна из старейших задач компьютерного зрения. С появлением визуально-языковых моделей возможности OCR значительно расширились. Сегодняшние системы могут не просто преобразовывать текст, но и понимать сложные элементы документов.
Современные возможности обработки документов
Транскрипция
Современные модели преобразуют различные типы контента в машиночитаемый формат:
- Рукописный текст
- Различные системы письма (латиница, арабский, японские символы)
- Математические выражения
- Химические формулы
- Теги изображений и структуры страниц
Работа со сложными компонентами
Продвинутые модели распознают:
- Изображения
- Диаграммы
- Таблицы
Некоторые модели, такие как OlmOCR от AllenAI или PaddleOCR-VL от PaddlePaddle, определяют расположение изображений в документе, извлекают их координаты и корректно встраивают между текстами. Другие модели генерируют подписи к изображениям и размещают их в соответствующих местах.
Диаграммы могут преобразовываться в различные форматы — например, столбчатая диаграмма конвертируется в маркдаун-таблицу или JSON.

Аналогично для таблиц: ячейки преобразуются в машиночитаемый формат с сохранением контекста заголовков и столбцов.

Форматы вывода данных
Разные модели OCR используют различные форматы вывода:
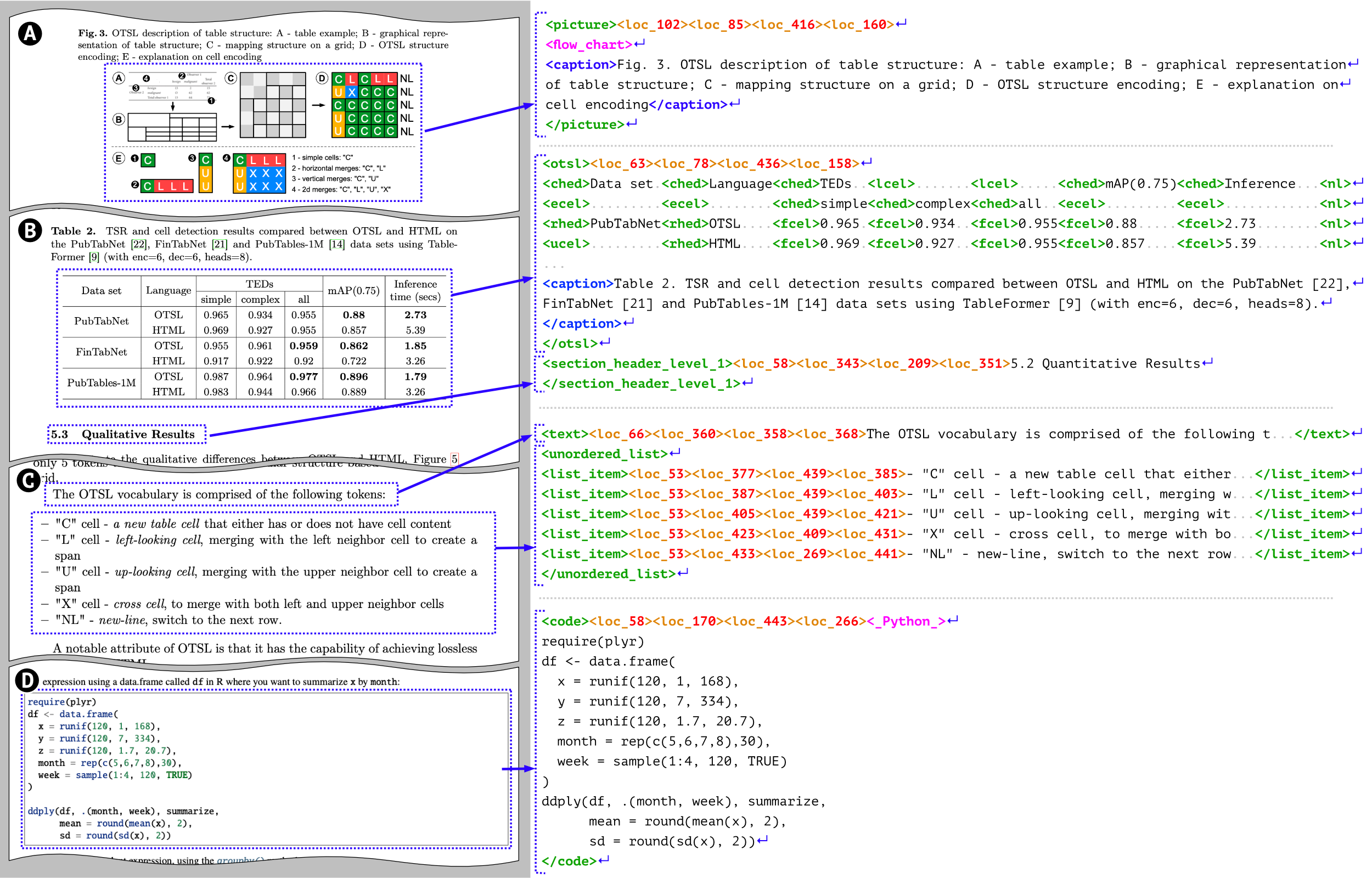
DocTag
XML-подобный формат для документов, который выражает расположение, формат текста, информацию на уровне компонентов и многое другое. Этот формат используется открытыми моделями Docling.
HTML
Один из самых популярных форматов для парсинга документов, поскольку он правильно кодирует структуру и иерархическую информацию.
Markdown
Наиболее читаемый для человека формат. Проще чем HTML, но менее выразительный — например, не может представлять таблицы с разделенными колонками.
JSON
Не используется моделями для всего вывода целиком, но может применяться для представления информации в таблицах или диаграммах.
Выбор модели напоминает подбор инструмента для конкретной задачи: для цифровой реконструкции документов нужны форматы с сохранением структуры, для работы с языковыми моделями — более естественные представления. Ирония в том, что мы возвращаемся к основам: правильный формат важнее, чем самая продвинутая модель. Открытые решения демонстрируют, что качественная обработка документов стала доступной технологией, а не эксклюзивной прерогативой крупных вендоров.
Практические рекомендации по выбору
Правильный выбор модели зависит от планируемого использования её результатов:
- Цифровая реконструкция: для восстановления цифровых копий документов выбирайте модели с форматами, сохраняющими структуру (DocTags или HTML)
- Ввод в языковые модели или вопросы-ответы: если результаты будут передаваться в LLM, выбирайте модели с выводом в Markdown и подписями к изображениям
- Программное использование: для интеграции в программные системы важны структурированные форматы вывода
Открытые модели OCR предлагают прозрачность, контроль над данными и возможность адаптации под конкретные задачи, что делает их привлекательной альтернативой проприетарным решениям.





Оставить комментарий