
Всего через два месяца после первого релиза NVIDIA расширяет свой открытый датасет для обучения моделей компьютерного зрения почти втрое — с 3 до 11 миллионов образцов. Новый выпуск Nemotron VLM Dataset V2 добавляет 8 миллионов высококачественных примеров для задач оптического распознавания символов (OCR), анализа изображений и видео, а также цепочек рассуждений.
Что нового в датасете
Команда NVIDIA Nemotron сосредоточилась на трех ключевых направлениях развития:
- Новые модальности данных — добавлены задачи анализа видео, понимания интерфейсов, сложных диаграмм и схем
- Усиление логического мышления — расширены данные для обучения цепочек рассуждений, что помогает моделям не просто давать ответы, но и понимать процесс их получения
- Инструменты для генерации OCR-данных — открыт конвейер для создания обучающих данных из LaTeX-документов
Технологические инновации в создании данных
Особый интерес представляет подход NVIDIA к генерации данных для оптического распознавания символов (OCR). Вместо традиционных методов конвертации в HTML, которые теряют структуру и семантику, компания разработала специализированный конвейер компиляции LaTeX. Эта система патчит TeX-движок для извлечения точных позиций глифов и семантического контекста, создавая богато аннотированные датасеты с изображениями PDF-страниц, 2D-ограничивающими рамками, форматированным текстом в Markdown и семантическими классами.
NVIDIA открывает исходный код этого конвейера, а также предоставляет инструменты аугментации для создания разнообразных макетов, шрифтов и многоязычного контента.
Это действительно стратегический ход — вместо того чтобы просто выпускать очередную модель, NVIDIA дает сообществу инструменты для создания собственных обучающих данных. Особенно впечатляет подход с LaTeX-компиляцией: большинство компаний ограничиваются сканированием готовых PDF, а здесь предлагается методологически правильный способ генерации структурированных данных с сохранением семантики. Похоже, NVIDIA понимает, что в эпоху больших языковых моделей (LLM) настоящая ценность — не в моделях, а в качественных данных для их обучения.
Структура и применение
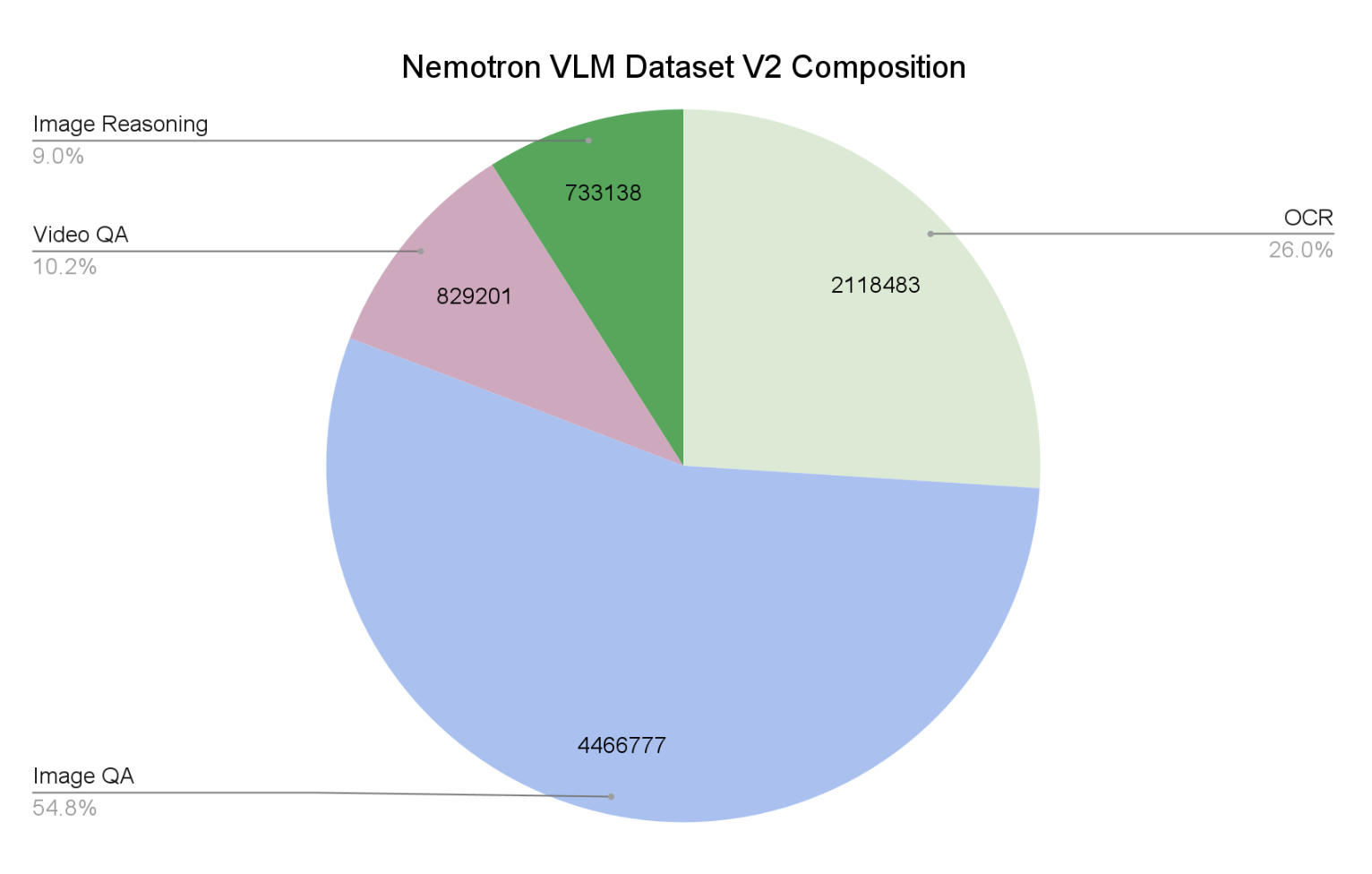
Nemotron VLM Dataset V2 состоит из:
- 55% — образцы вопрос-ответ по изображениям
- 25% — данные оптического распознавания символов (OCR)
- 10% — анализ видео
- 10% — логические рассуждения на основе изображений
OCR-компонент включает многоязычные данные для десяти языков, что значительно расширяет возможности моделей для международного применения.
Разработчики могут использовать датасет целиком или дополнительно курировать его с помощью NVIDIA NeMo Curator для создания специализированных наборов данных под конкретные задачи.
NVIDIA провела комплексные проверки безопасности и соответствия для этого датасета, включая верификацию разрешенных источников данных и сканирование на предмет токсичного контента. Датасет готов к коммерческому использованию и предназначен для поддержки корпоративных сценариев и разработки production-решений на основе ИИ.
По материалам Hugging Face.





Оставить комментарий