
Оглавление
По сообщению Hugging Face, NVIDIA представила Nemotron-Personas-USA — масштабный набор полностью синтетических данных, имитирующих американское население. Это первый в своем роде открытый датасет, построенный на статистике Бюро переписи США, но не содержащий реальных персональных данных.
Что внутри датасета
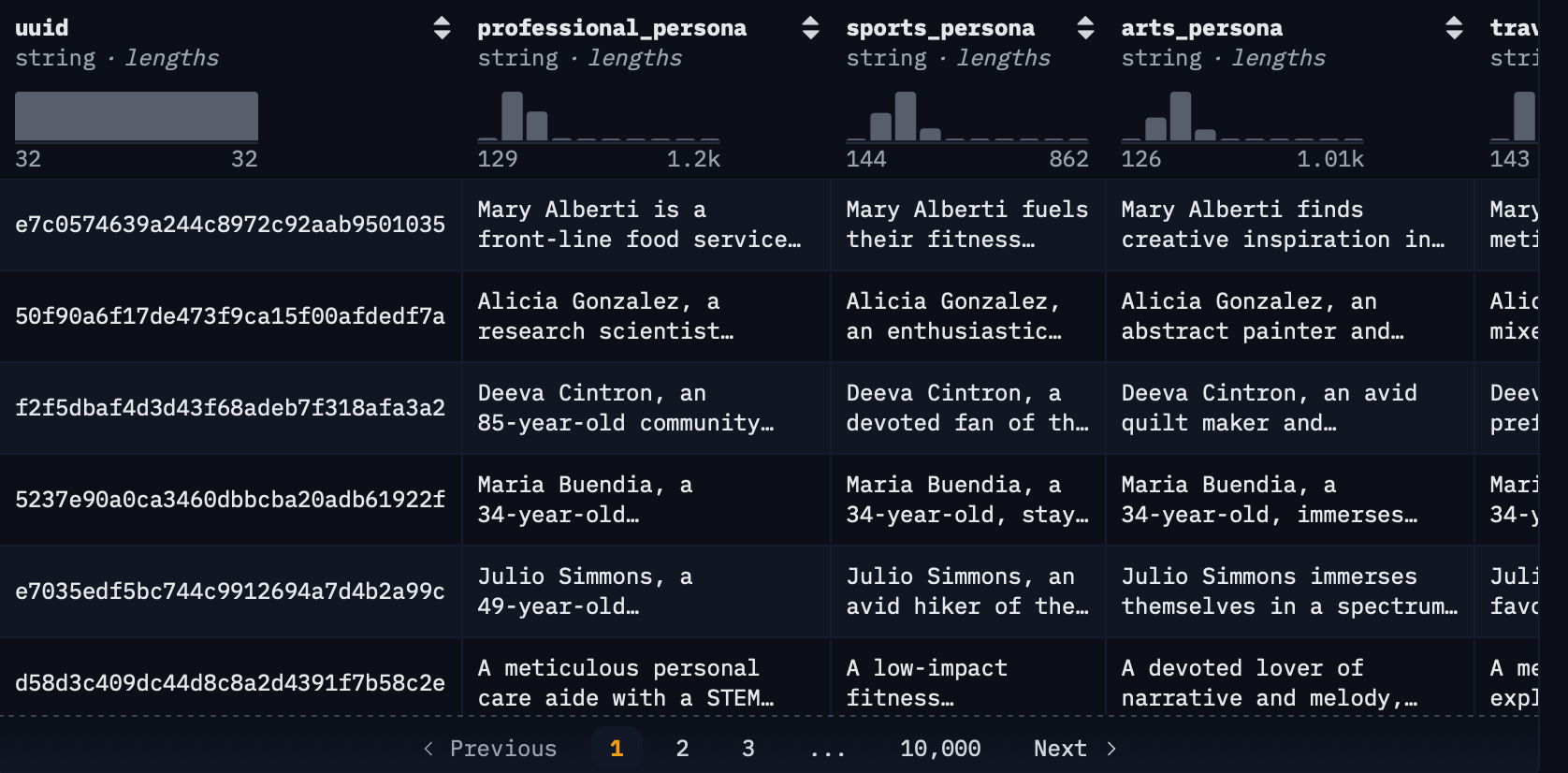
Набор данных включает 6 миллионов синтетических персонажей, распределенных по всем 50 штатам и территориям США. Каждый профиль содержит демографические, профессиональные и поведенческие характеристики, отражающие реальное разнообразие населения.
- 6 миллионов персонажей, соответствующих статистике Бюро переписи США и Бюро трудовой статистики
- ~936 миллионов токенов (~371 миллион токенов персонажей)
- 970 тысяч уникальных полных имен (53.7 тысяч имен | 43.2 тысячи отчеств | 118 тысяч фамилий)
- 560+ профессий, основанных на реальных распределениях
- 18.7 тысяч почтовых индексов и 9.5 тысяч городов
- Охват недостаточно представленных групп по возрасту, географии, образованию и этнической принадлежности
- 100% синтетические данные → нулевой риск нарушения конфиденциальности
- Лицензия: CC BY 4.0 (открыта для исследований и коммерческого использования)
Технология создания
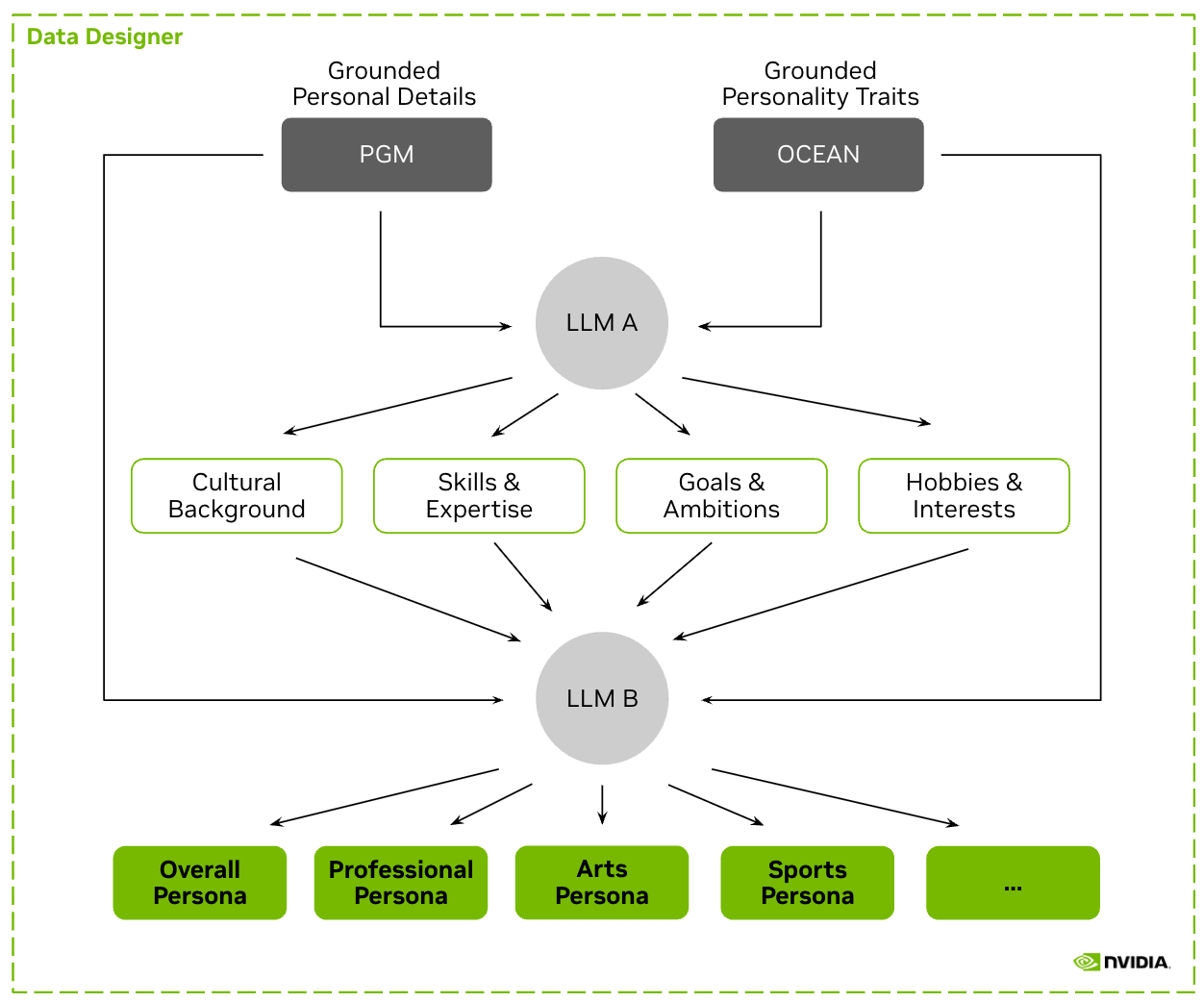
Датасет создан с использованием NVIDIA NeMo Data Designer — комплексного микросервиса для генерации синтетических данных в больших масштабах.
Конвейер генерации данных
Система поддерживает шаблоны Jinja, валидацию Pydantic, структурированные выходные данные, автоматические повторные попытки и несколько бэкендов генерации.
Основные методики:
- Вероятностные графические модели (Apache-2.0) для статистической основы
- Ансамбль нескольких языковых моделей для семантической и контекстной согласованности
- Моделирование личности (OCEAN) для поведенческого разнообразия
Конфиденциальность по дизайну
Все персонажи полностью синтетические. Хотя они основаны на агрегированной статистике США, ни одна запись не связана с реальным человеком. Это позволяет разработчикам безопасно обучать системы ИИ без рисков для конфиденциальности или регуляторных барьеров.
Этот подход кардинально меняет правила игры в области данных для ИИ. Вместо бесконечных споров о том, какие данные можно скрапить из интернета, мы получаем готовое решение, которое изначально соответствует требованиям конфиденциальности. Особенно ценно то, что NVIDIA не просто генерирует случайные профили, а делает это на основе реальной статистики — получается своего рода «цифровой двойник» населения без рисков деанонимизации.
Практическое применение
Разработчики могут комбинировать данные Nemotron-Personas с другими инструментами NeMo для создания сквозных конвейеров данных:
- Обучение и оценка экспертных ИИ-агентов для финансов, здравоохранения и государственных услуг
- Минимизация рисков при работе с чувствительными данными при разработке моделей или API
- Создание симуляций «что если» для прогнозирования политики или рынков
- Предотвращение дрейфа данных и коллапса моделей через непрерывное синтетическое обновление
Почему это важно
Надежный ИИ зависит от надежных данных. Традиционная анонимизация часто не соответствует современным стандартам конфиденциальности или воспроизводимости. В отличие от этого, полностью синтетические наборы данных предлагают:
- Доказуемая конфиденциальность и соответствие — нет связи с реальными людьми
- Прозрачное происхождение — воспроизводимый конвейер генерации
- Культурную основу — соответствие региональной и демографической статистике США
- Высокую полезность — производительность на уровне реальных данных в последующих задачах
Начало работы
Для начала экспериментов сегодня:
from datasets import load_dataset
# Американские персонажи
nemotron_personas_us = load_dataset("nvidia/Nemotron-Personas-USA")
Расширенная версия Nemotron-Personas-USA (включая синтетические адреса, иерархии профессий и диапазоны доходов) доступна через NVIDIA NeMo Data Designer.





Оставить комментарий