
Оглавление
Компания NVIDIA представила открытый синтетический датасет Nemotron-Personas-India, содержащий 21 миллион виртуальных персонажей, отражающих демографическое, географическое и культурное разнообразие Индии. Этот шаг направлен на решение проблемы дефицита качественных данных для обучения искусственного интеллекта в многоязычной среде.
Открытые данные для будущего ИИ в Индии
Индия представляет один из крупнейших мировых рынков для искусственного интеллекта — более 700 миллионов пользователей интернета, множество языков и быстрорастущая экосистема разработчиков. Однако большинство открытых датасетов отражают западные нормы и англоязычные контексты, создавая пробел в данных, который ограничивает внедрение ИИ в многоязычной среде Индии.
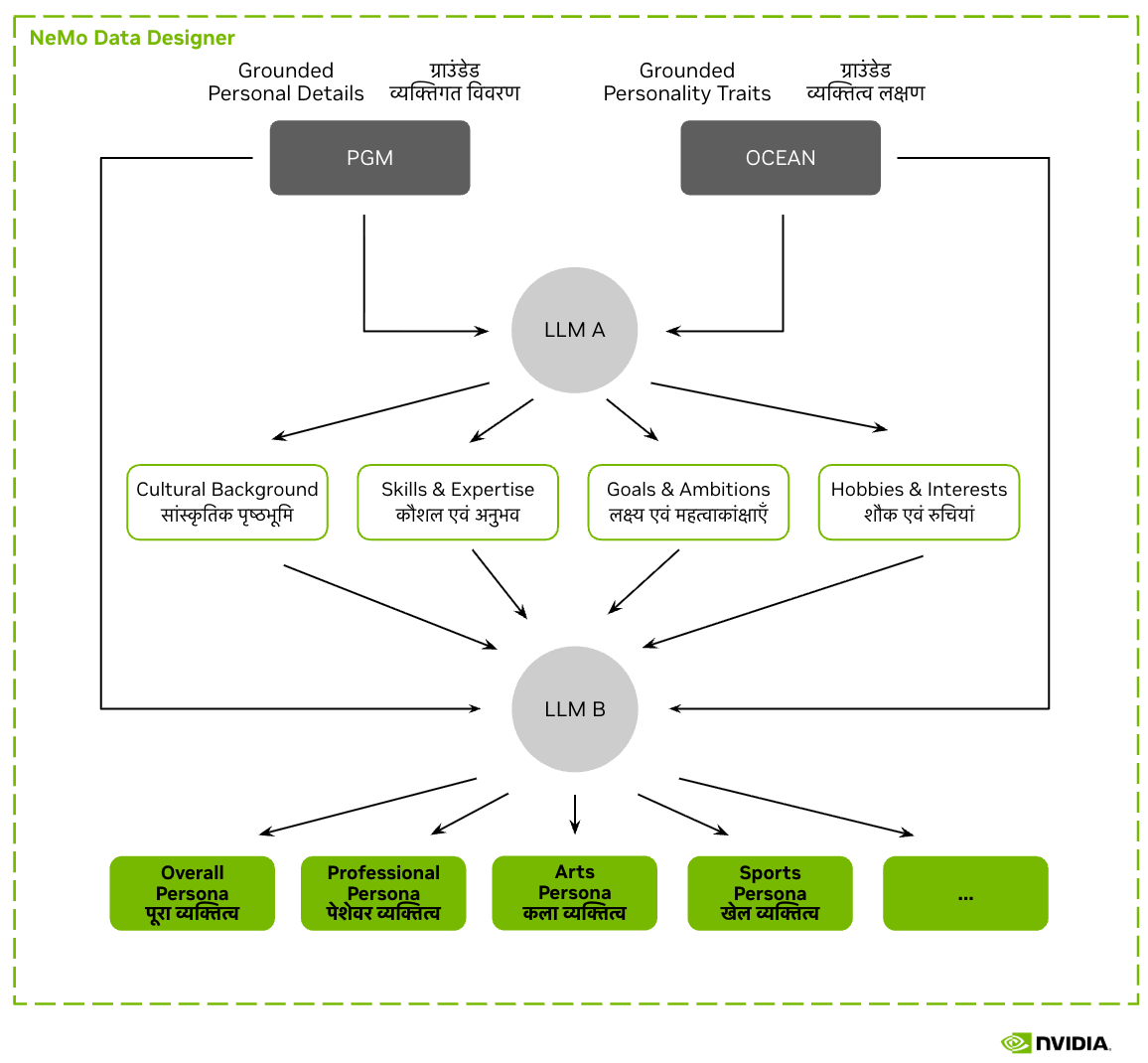
Новый датасет, созданный с помощью NeMo Data Designer, предлагает приватный и регуляторно-совместимый фундамент для масштабирования ИИ-систем, отражающих индийское общество — без использования чувствительных персональных данных.
Содержание датасета
- 21 миллион персонажей (3 млн записей × 7 персонажей каждая)
- Многоязычная поддержка: английский и хинди в деванагари и латинице
- 27 полей на запись: характеристики персонажей + контекстные атрибуты, основанные на официальной переписи и статистике труда
- 7.7 миллиардов токенов, включая 2.9 млрд токенов персонажей
- ~560 тысяч уникальных полных имен, отражающих языковое разнообразие Индии
- 2.9 тысячи профессиональных категорий, включая неформальный, формальный и традиционный секторы
- Все 36 штатов Индии и 640 округов представлены
- Лицензия CC BY 4.0 для коммерческого и некоммерческого использования
Техническая реализация
Датасет создан с использованием комплексного подхода искусственного интеллекта:
- Вероятностная графическая модель для статистического обоснования
- GPT-OSS-120B для генерации нарративов на английском, хинди (деванагари) и хинди (латиница)
Культурный контекст был выровнен по официальным демографическим распределениям из переписи 2011 года и расширен для включения атрибутов, необходимых для достоверного обучения ИИ.
Синтетические данные — это не просто обходной путь для приватности, а стратегический актив в регионах с разнообразными культурными и языковыми ландшафтами. NVIDIA демонстрирует, что можно создавать реалистичные демографические профили без риска реидентификации, что особенно важно в свете ужесточающегося регулирования данных. Ирония в том, что для обучения «умных» систем нам приходится создавать «искусственных» людей — но именно это позволяет избежать реальных проблем с приватностью.
Безопасность и приватность
Все персонажи полностью синтетические. Хотя они основаны на реальных распределениях из переписи 2011 года и индийских избирательных списков, никакие данные не привязаны к реальным людям. Это позволяет разработчикам безопасно обучать ИИ-системы без рисков для приватности или регуляторных барьеров.
Датасет интегрируется с моделями Nemotron и другими открытыми языковыми моделями, упрощая тонкую настройку ИИ-систем для индийских сценариев использования — от многоязычных чат-ботов до культурно-обоснованных специализированных ассистентов.
Этот релиз дополняет ранее выпущенные наборы данных для оценки на хинди, поддерживая полный цикл от генерации синтетических данных до строгой оценки моделей для индийских ИИ-систем.
По материалам Hugging Face





Оставить комментарий