
Оглавление
В мире машинного обучения появился радикально новый подход к улучшению языковых моделей — прямое манипулирование тензорами на бинарном уровне, минуя традиционное обучение. Эксперимент с моделью Qwen-0.6B показал впечатляющие результаты: всего 44 целенаправленных изменения в весах повысили производительность в 5 раз.
Нестандартный подход к улучшению ИИ
В то время как большинство исследователей сосредоточены на тонкой настройке и обучении с подкреплением, разработчик TensorSlay предложил альтернативную методологию. Вместо традиционных градиентных методов он предложил рассматривать веса нейронных сетей как бинарные данные, которые можно анализировать и модифицировать напрямую.
Традиционные методы улучшения языковых моделей включают:
- Контролируемую тонкую настройку: обучение на специализированных наборах данных
- Обучение с подкреплением: оптимизация под человеческие предпочтения
- Инженерию промптов: создание улучшенных стратегий ввода
Все эти подходы требуют значительных вычислительных ресурсов, времени и дополнительных данных.
Идея напоминает взлом программного обеспечения — вместо переписывания кода мы патчим уже скомпилированный бинарник. Только в случае с нейросетями «бинарником» выступают веса модели, а «патчем» — целенаправленные изменения тензоров.
Фреймворк Tensor Slayer
Методология основана на использовании более крупной и мощной ИИ-системы для анализа архитектуры целевой модели и генерации рекомендаций по улучшению. Процесс состоит из трех этапов:
- Архитектурный анализ: парсинг структуры модели и распределения весов
- Планирование улучшений с помощью ИИ: использование большой языковой модели для анализа данных и предложения модификаций
- Целевое применение: внесение рекомендованных изменений с полной трассируемостью
Кейс-стади: улучшение Qwen-0.6B
Для эксперимента была выбрана модель Qwen-0.6B благодаря управляемой сложности, современной архитектуре и хорошо документированной базовой производительности.
Стратегия улучшения от ИИ
Система анализа сгенерировала комплексную стратегию из 44 пунктов улучшения. Примечательно не только содержание модификаций, но и сложная аргументация для каждой рекомендации.
Улучшение встраивания и вывода
Для тензора model.embed_tokens.weight ИИ рекомендовал масштабирование в 1.02 раза с обоснованием: «Небольшое увеличение масштаба входных эмбеддингов может улучшить начальное представление токенов, делая модель более чувствительной к нюансам ввода и улучшая раннее извлечение признаков для общего рассуждения.»
Для тензора lm_head.weight предложено масштабирование в 1.03 раза: «Увеличение масштаба весов финального линейного слоя может привести к более четким и уверенным предсказаниям, напрямую улучшая способность модели выводить связные и точные ответы на основе внутреннего рассуждения.»
Систематическое улучшение средних слоев
ИИ выявил последовательный паттерн в слоях 10-27, рекомендовав систематические улучшения компонентов внимания и MLP:
- Масштабирование проекций запросов в слоях внимания на 1.02x
- Оптимизация нисходящих проекций в MLP слоях на 1.02x
Для тензора model.layers.15.self_attn.k_norm.weight предложено ограничение диапазона [-0.0032958984375, 20.0] для экстремальных выбросов: «Ограничение верхних выбросов весов нормализации ключей предотвращает доминирование чрезмерно больших значений ключей в оценках внимания, способствуя более сбалансированному распределению внимания и улучшая устойчивость в взвешивании признаков.»
Результаты валидации
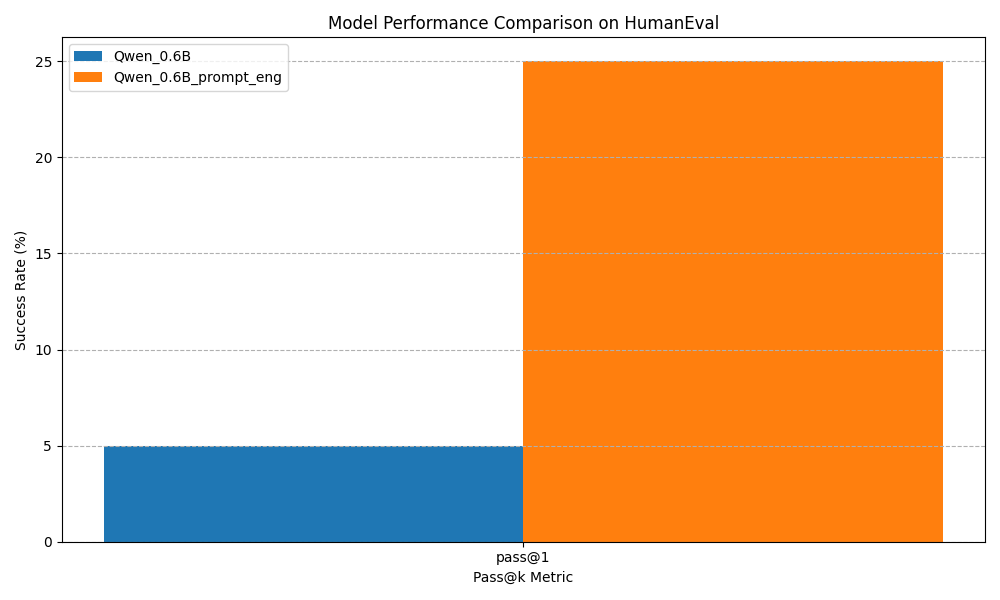
Для оценки эффективности модификаций тестировались как оригинальная, так и улучшенная модели на бенчмарке HumanEval — стандартном наборе данных для оценки возможностей генерации кода в языковых моделях.
Результаты превзошли ожидания:
| Версия модели | Pass@1 Rate | Улучшение |
|---|---|---|
| Оригинальная Qwen-0.6B | 5% | — |
| Улучшенная Qwen-0.6B | 25% | +400% |
Это представляет собой 5-кратное улучшение способности модели генерировать корректные решения кода. Особенно впечатляет то, что:
- Без дополнительного обучения: улучшения получены исключительно за счет 44 модификаций тензоров
- Целенаправленные изменения: каждая модификация была обоснована и имела конкретную цель
- Измеримый результат: производительность проверена на стандартном бенчмарке
Если этот метод окажется воспроизводимым для других моделей, мы можем увидеть рождение новой парадигмы в оптимизации ИИ — не обучение моделей, а их «настройка» через прямое редактирование весов. Это напоминает эпоху, когда программисты перешли от ассемблера к языкам высокого уровня, но в случае с нейросетями мы только начинаем понимать, как «дизассемблировать» их внутреннюю структуру.
По материалам HuggingFace.





Оставить комментарий