
Оглавление
Обучение современных больших языковых моделей требует масштабируемых вычислительных ресурсов. Как сообщает AWS Machine Learning Blog, для тренировки Meta Llama 3 потребовалось 16,000 графических процессоров NVIDIA H100, что заняло более 30.84 миллионов GPU-часов. Amazon Elastic Kubernetes Service (EKS) предоставляет управляемый сервис для развертывания и масштабирования Kubernetes-кластеров, способных справиться с такими нагрузками.
Проблемы конфигурации распределенного обучения
Основная сложность при настройке кластеров для распределенного обучения заключается в правильной конфигурации GPU в инстансах Amazon EC2. Существует два семейства GPU-инстансов:
- G-семейство (например, G6 с NVIDIA L4) — для бюджетного инференса и легкого обучения
- P-семейство (например, P6 с NVIDIA GB200 NVL72) — для масштабных распределенных задач
Один инстанс P5 содержит 8 H100 GPU с 640 GB HBM3 и обеспечивает сетевую пропускную способность 3,200 Gbps через Elastic Fabric Adapter (EFA), что делает его идеальным для обучения моделей с миллиардами параметров.
При всей мощи P-инстансов, их настройка требует ювелирной точности в конфигурации сетей, хранилищ и GPU-топологий. Это классическая проблема современного ML-инжиниринга: мощное железо превращается в бесполезный металл без правильной конфигурации. Особенно забавно наблюдать, как команды тратят недели на отладку сетевых задержек, забывая проверить базовые настройки NCCL.
Системный подход к настройке кластера
Решение включает несколько ключевых шагов:
- Сборка Docker-образа с необходимыми зависимостями на основе AWS Deep Learning Containers
- Запуск инфраструктуры в стабильном GPU-готовом кластере Amazon EKS
- Установка специфичных плагинов для GPU-устройств, поддержки EFA, фреймворков распределенного обучения и постоянного файлового хранилища
- Выполнение проверок работоспособности для верификации готовности узлов и правильной конфигурации NVIDIA и EFA плагинов
- Запуск тестового задания обучения для проверки всей системы
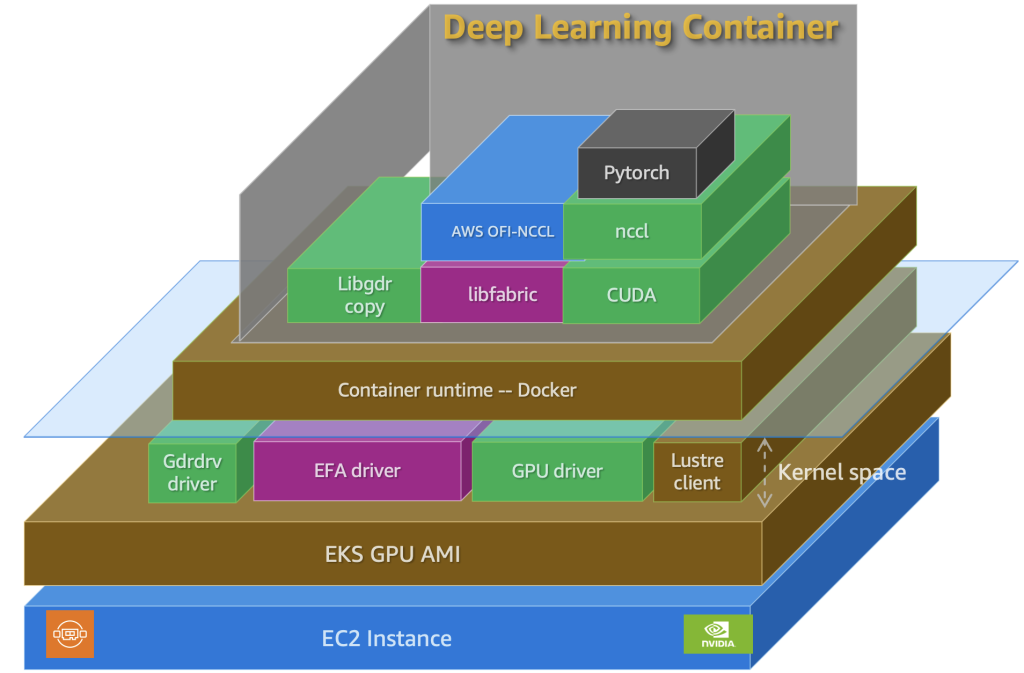
Преимущества AWS Deep Learning Containers
DLC предоставляют предварительно собранные, оптимизированные для производительности Docker-образы, которые упрощают запуск популярных фреймворков вроде PyTorch на AWS. Каждый контейнер поставляется с полностью интегрированным стеком, включающим совместимые версии CUDA, cuDNN и NCCL, плюс опциональную поддержку EFA для распределенного обучения с высокой пропускной способностью и низкой задержкой.
Эти контейнеры валидированы для работы на Amazon EC2, Amazon ECS и Amazon EKS, обеспечивая стабильную производительность на GPU-инстансах G- и P-семейств. Единообразная среда критически важна для распределенных рабочих нагрузок, где даже незначительные несоответствия версий могут привести к деградации пропускной способности, остановке операций all-reduce или ошибкам CUDA/NCCL.
Практическая реализация
В статье демонстрируется процесс создания пользовательского Docker-контейнера путем добавления дополнительных Python-библиотек к PyTorch 2.7.1 Training DLC для запуска задания обучения с моделью Meta Llama 2 7B. Используется флот из двух инстансов p4d.24xlarge, потребляемых из резерва мощности.
Хотя можно собирать тренировочные контейнеры с нуля, делать это в промышленном масштабе утомительно: драйверы GPU, CUDA, NCCL и сетевые библиотеки должны быть согласованы со строгими требованиями к версиям и оборудованию. DLC упрощают этот процесс, предоставляя безопасные, регулярно обновляемые образы, уже оптимизированные для инфраструктуры AWS.





Оставить комментарий