Как сообщает Hugging Face, представлена Model2Vec — метод создания сверхбыстрых и компактных эмбеддингов из больших языковых моделей. Технология позволяет уменьшить размер моделей в 15 раз и ускорить их работу в 500 раз, сохраняя при этом конкурентное качество векторизации текста.
Проблема ресурсоемкости современных моделей
Большие языковые модели стали стандартом для извлечения признаков из текста, но их использование сопряжено с высокими требованиями к вычислительным ресурсам, энергопотреблению и времени обработки. Хотя существуют методы оптимизации вроде квантования и специализированных ядер, модели остаются относительно медленными, особенно на CPU.
Model2Vec предлагает решение: статические эмбеддинги, которые сочетают экологичность, аппаратную эффективность и достойное качество. Метод не требует обучающих данных — только исходную модель и опционально словарь.
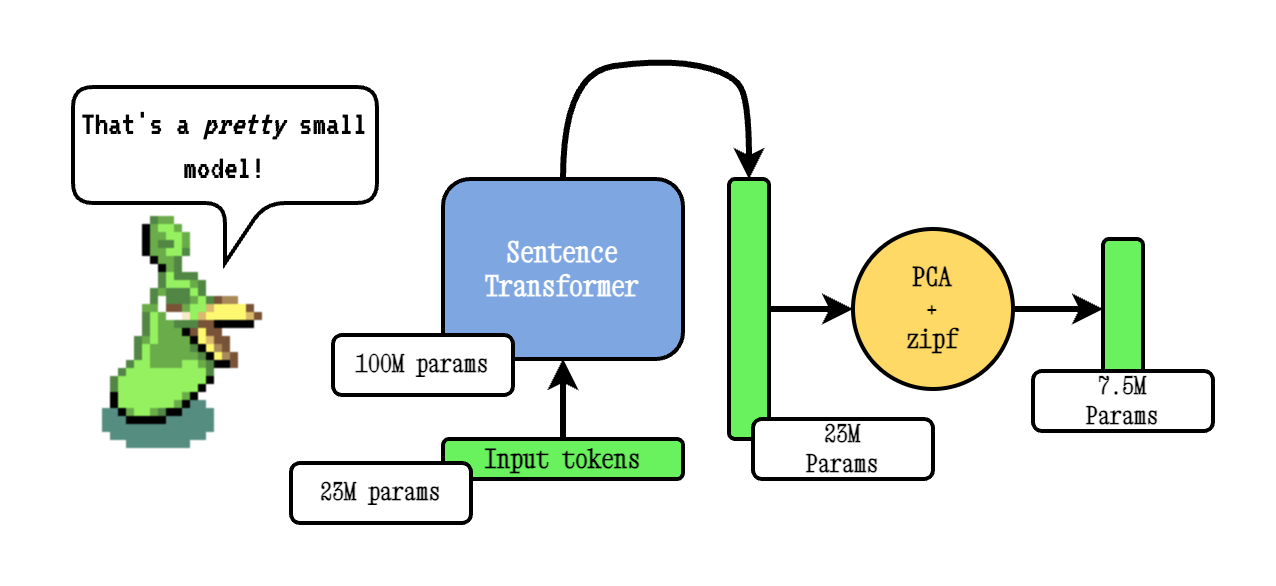
Как работает Model2Vec
Техника работает в три этапа:
- Пропускает словарь модели через Sentence Transformer для получения токенных эмбеддингов
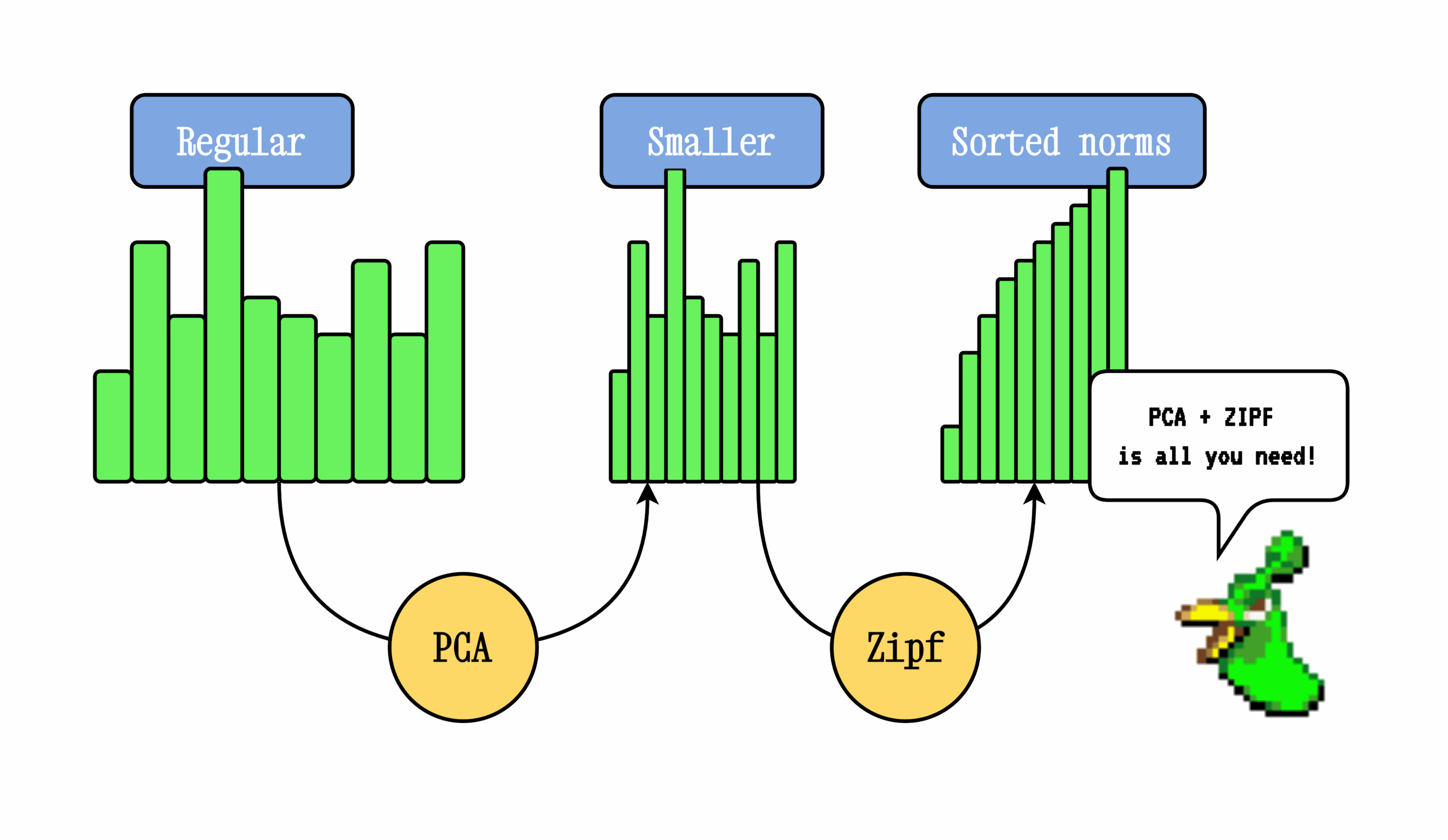
- Снижает размерность с помощью PCA
- Применяет взвешивание на основе закона Ципфа для нормализации частотных слов
Во время инференса система просто усредняет эмбеддинги всех токенов в предложении. Важно отметить, что полученные представления неконтекстуализированы — один и тот же токен всегда будет иметь одинаковое векторное представление независимо от окружения.
Ирония в том, что уменьшение размерности через PCA неожиданно улучшает качество — видимо, алгоритм вычищает шум и смещения в исходном векторном пространстве. Zipf-взвешивание же элегантно решает проблему частотных слов без необходимости доступа к корпусу текстов. Гениально просто, хотя и жертвует контекстуальностью ради скорости.
Практическое применение
Библиотека поддерживает три режима дистилляции:
- Выходной: использует субсловный токенизатор, быстрый в создании (30 секунд на CPU) и компактный (30 МБ)
- Словарь (слово): позволяет использовать собственный словарь для доменно-специфичных данных
- Словарь (субслово): комбинирует пользовательский словарь с субсловной токенизацией
Model2Vec интегрируется с экосистемой Sentence Transformers, что позволяет использовать его в pipelines LangChain и LlamaIndex. Технология особенно полезна для:
- Поисковых систем с жесткими временными ограничениями
- Систем RAG с ограниченными ресурсами
- Кластеризации и классификации текста
- Приложений, работающих на CPU или мобильных устройствах
При всей своей простоте, Model2Vec показывает удивительную эффективность. Хотя отсутствие контекстуализации выглядит как серьезный компромисс, для многих практических задач этого оказывается достаточно — особенно когда на кону скорость обработки и экономия ресурсов.





Оставить комментарий