
Оглавление
Исследователи Microsoft Research разработали RenderFormer — первую нейросетевую архитектуру, способную полностью заменить традиционный конвейер 3D-рендеринга. Модель показывает, что нейросети могут обрабатывать произвольные 3D-сцены с глобальным освещением без использования лучевой трассировки или растеризации. Работа принята на SIGGRAPH 2025 и доступна в открытом исходном коде.
Архитектура, основанная на токенах
RenderFormer представляет всю 3D-сцену с помощью треугольных токенов, каждый из которых кодирует пространственное положение, нормаль поверхности и физические свойства материала: диффузный цвет, зеркальный цвет и шероховатость. Освещение также моделируется как треугольные токены со значениями эмиссии.
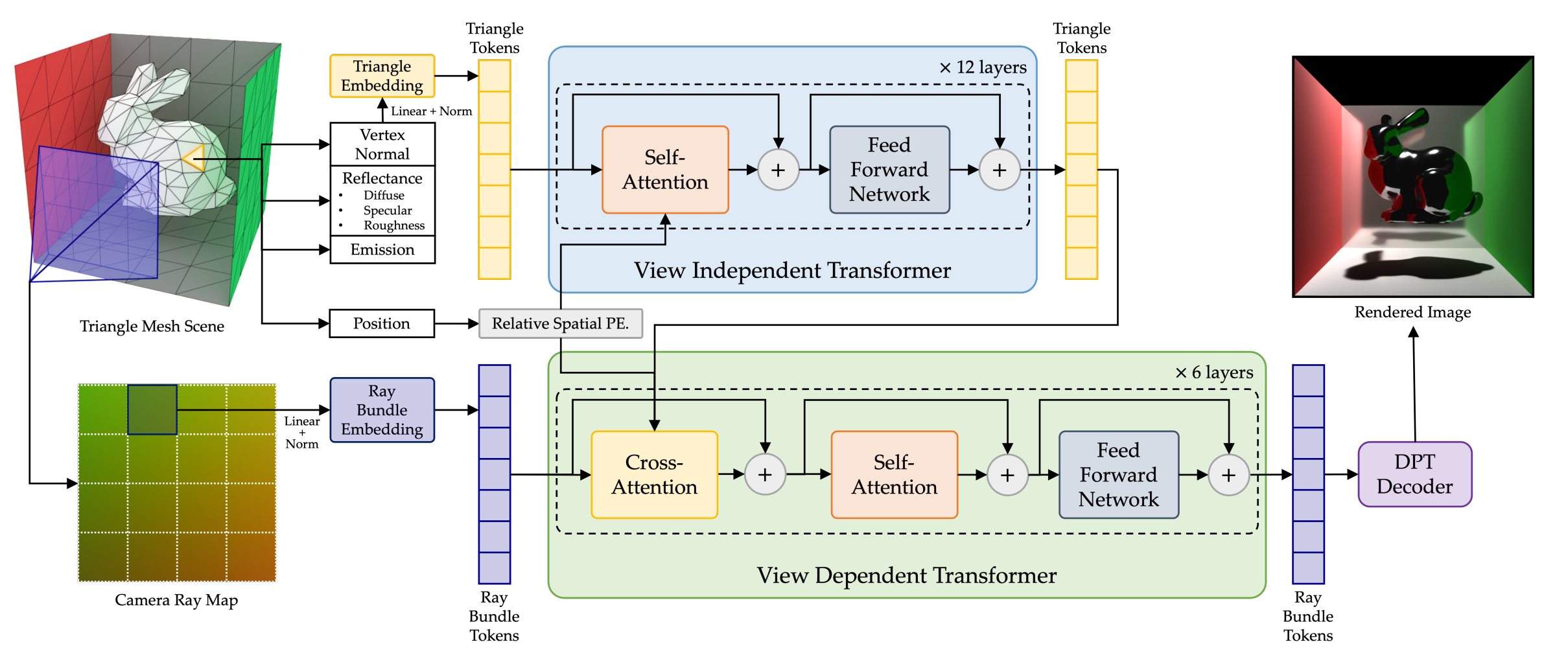
Для описания направления обзора модель использует токены лучевых пучков, производные от карты лучей — каждый пиксель выходного изображения соответствует одному из этих лучей. Для повышения вычислительной эффективности пиксели группируются в прямоугольные блоки, что позволяет обрабатывать все лучи в блоке одновременно.
Двухкомпонентная архитектура трансформера
Архитектура RenderFormer построена вокруг двух трансформеров: для независимых от вида и зависимых от вида эффектов.
- Независимый от вида трансформер захватывает информацию сцены, не связанную с точкой обзора, такую как тени и диффузный транспорт света, используя самовнимание между треугольными токенами
- Зависимый от вида трансформер моделирует эффекты видимости, отражений и бликов через перекрестное внимание между треугольными и лучевыми токенами
Дополнительные эффекты в пространстве изображения, такие как сглаживание и экранные отражения, обрабатываются с помощью самовнимания среди токенов лучевых пучков.
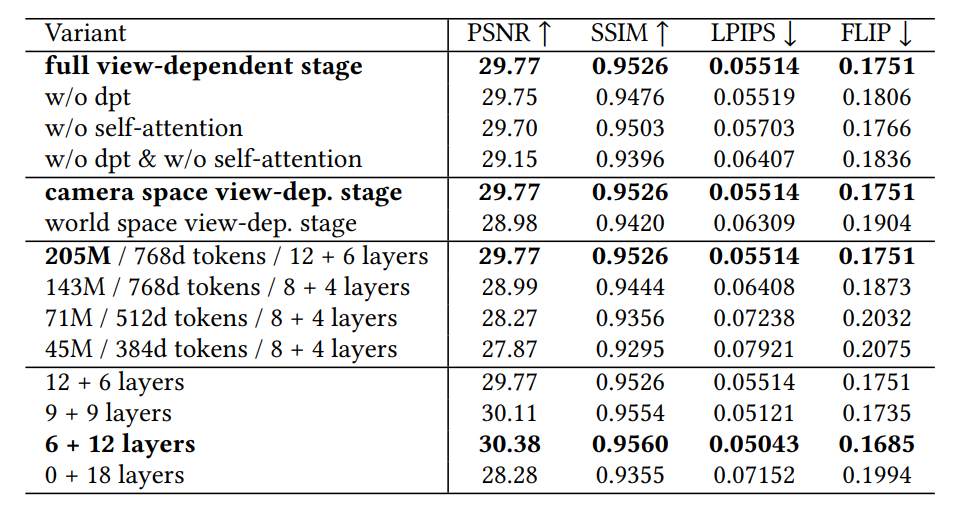
Это первый случай, когда нейросеть учится полному конвейеру рендеринга, а не просто дорисовывает детали или улучшает существующее изображение. Технически впечатляет, но практическое применение пока под вопросом — 205 миллионов параметров и требования к вычислениям делают технологию доступной только для крупных студий с серьезным железом.
Методология обучения и данные
RenderFormer обучался на наборе данных Objaverse, содержащем более 800 000 аннотированных 3D-объектов. Исследователи создали четыре шаблона сцен, заполняя каждый 1-3 случайно выбранными объектами и материалами. Сцены рендерились в высоком динамическом диапазоне с использованием рендерера Blender Cycles при различных условиях освещения и углах камеры.
Базовая модель из 205 миллионов параметров обучалась в две фазы с использованием оптимизатора AdamW:
- 500 000 шагов при разрешении 256×256 с до 1536 треугольников
- 100 000 шагов при разрешении 512×512 с до 4096 треугольников

Модель поддерживает произвольный треугольный ввод и хорошо обобщается на сложные реальные сцены. Как показано на иллюстрациях, она точно воспроизводит тени, диффузное затенение и зеркальные блики.
По сообщению Microsoft Research, работа открывает новые возможности для нейросетевого рендеринга и может найти применение в игровой индустрии, архитектурной визуализации и кинопроизводстве.





Оставить комментарий