
Оглавление
Исследователи Scale разработали метод Rubrics as Rewards (RaR), который позволяет небольшим языковым моделям превосходить крупные модели вроде GPT-4 на специализированных задачах. Технология решает фундаментальную проблему обучения ИИ для сложных корпоративных задач, где нет однозначных ответов.
Как работает метод RaR
В основе RaR лежит двухмодельная архитектура обучения с подкреплением:
- Студенческая модель получает полную постановку задачи и генерирует цепочку рассуждений и вывод в структурированной форме
- Модель-судья оценивает результат студента по детализированной рубрике, возвращая общий балл и оценки по каждому критерию
- Числовая оценка служит сигналом награды для алгоритма GRPO (Generalized Reinforcement Policy Optimization)
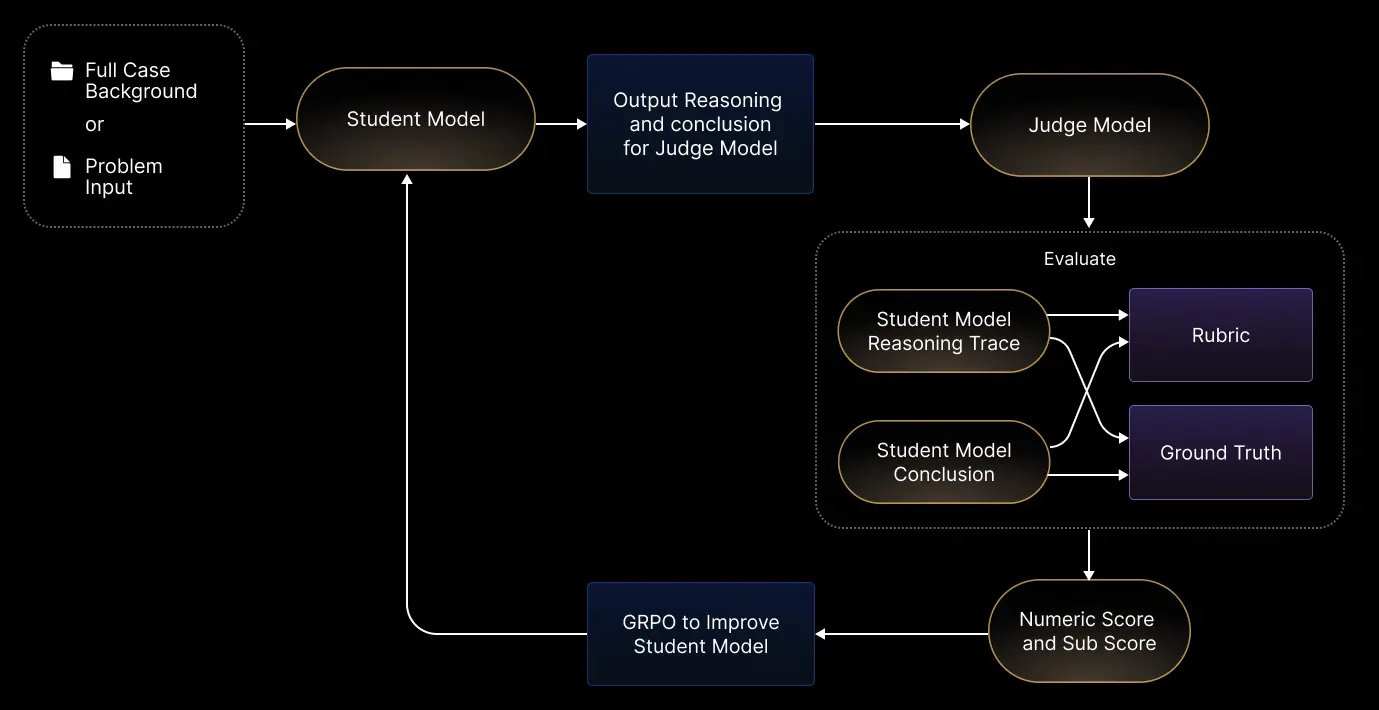
Рубрики структурированы и интерпретируемы — каждая содержит от 7 до 20 пунктов, организованных в четыре категории:
- Существенные (критически важные для корректности)
- Важные (ключевые рассуждения и полнота)
- Опциональные (полезные, но не обязательные)
- Типичные ошибки (распространенные промахи, которых следует избегать)
В отличие от популярных методов обучения на предпочтениях, где модели учатся на туманных сравнениях «А лучше Б», рубричное обучение обеспечивает полную прослеживаемость каждого сигнала награды к конкретным, понятным человеку критериям. Это возвращает нас к классическому инжинирингу признаков, но на уровне рассуждений — элегантное решение проблемы черного ящика в ИИ.
Практическое применение: обучение ИИ-юриста
Для демонстрации метода исследователи обучили небольшую открытую модель Qwen3-4B-Instruct генерировать юридические анализы дел с использованием структуры IRAC (Issue, Rule, Application, Conclusion). Эксперимент проводился на небольшом наборе из 51 обучающего и 41 тестового случая.
Модель-судья оценивала результаты по специализированной юридической рубрике, включавшей критерии:
- Корректность: правильно ли определен исход дела
- Применение законодательства: точность ссылок на кодексы
- Основной аргумент: объяснение «истинной цели» услуги
- Полнота: упоминание всех релевантных фактов
Результаты: маленький, но точный
На тестовом наборе из 41 дела рубрично-обученная модель показала впечатляющие результаты:
- Qwen3-4B-Instruct (zero-shot): 71.79% точности
- GPT-4.1 (zero-shot): 76.92% точности
- Qwen3-4b-instruct-rubric (fine-tuned): 79.49% точности
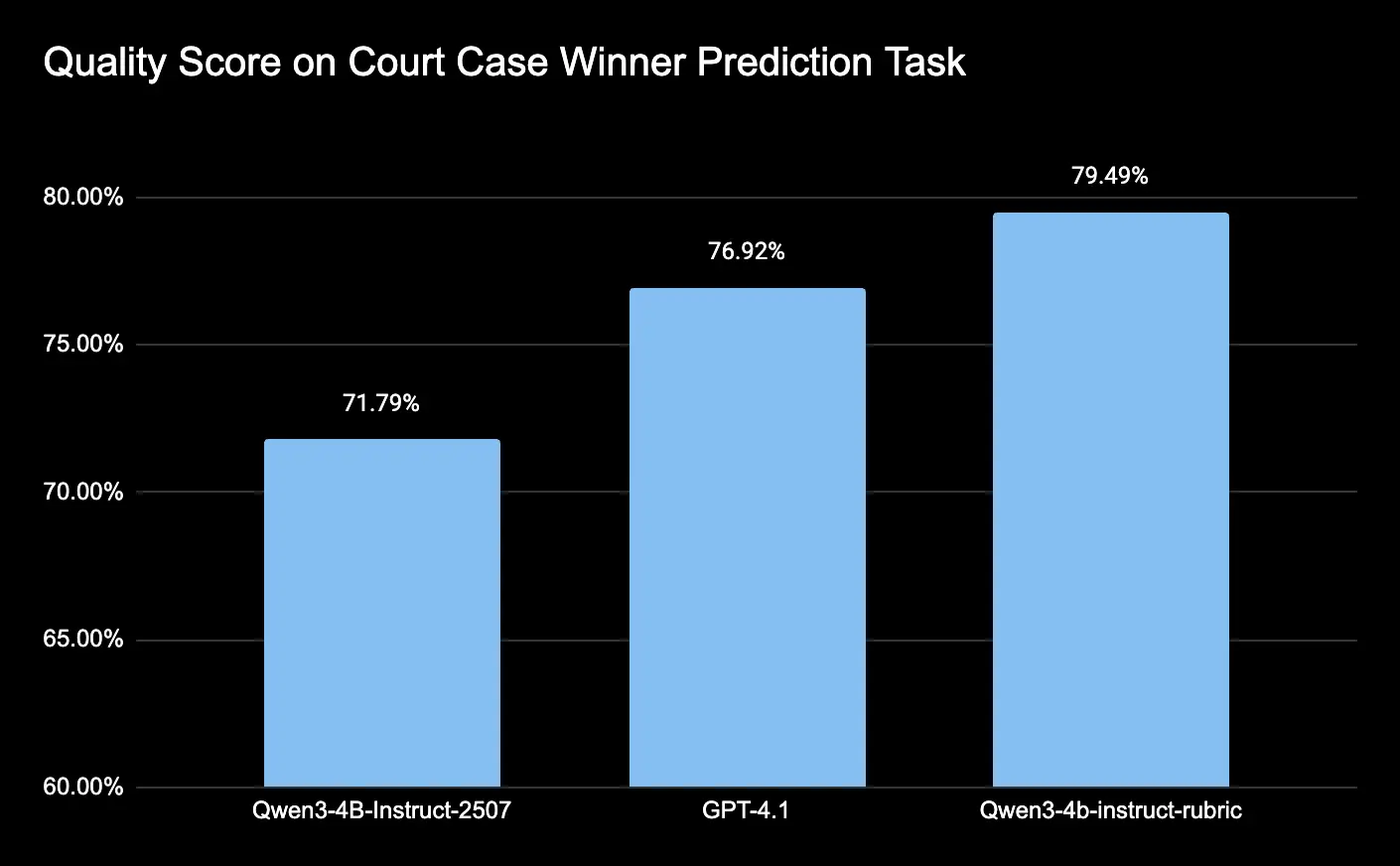
Небольшая модель, настроенная с доменно-специфичной рубрикой, не только улучшила собственную точность, но и превзошла значительно более крупную GPT-4.1 в задаче юридического анализа.
Это классический пример того, как специализация бьет масштаб. Вместо того чтобы гоняться за все более крупными моделями, мы видим, что тщательно настроенная маленькая модель может эффективно решать узкоспециализированные задачи — и делать это с большей прозрачностью и контролем, чем черный ящик размером в триллионы параметров.
Широкие возможности применения
Метод RaR доказал свою эффективность не только в юриспруденции. В отдельном эксперименте по определению налогооблагаемости бизнес-транзакций аналогично обученная небольшая модель достигла точности около 98%, значительно превзойдя крупные модели общего назначения.
В масштабном исследовании метод показал улучшение на 28% на медицинском бенчмарке HealthBench-1k и значительный прогресс на научном GPQA-Diamond, демонстрируя кросс-доменную применимость подхода.
По материалам Scale





Оставить комментарий