
Оглавление
Компания LightOn представила специализированную модель компьютерного зрения LightOnOCR-1B для оптического распознавания текста, которая устанавливает новый стандарт эффективности в своем классе. Модель не только превосходит по производительности более крупные общие модели, но и работает значительно быстрее конкурентов.
Ключевые преимущества LightOnOCR-1B
Новая модель демонстрирует исключительную производительность при компактном размере — всего 1 миллиард параметров. По данным разработчиков, LightOnOCR-1B работает в 6,49 раза быстрее, чем dots.ocr, в 2,67 раза быстрее PaddleOCR-VL-0.9B и в 1,73 раза быстрее DeepSeekOCR.
В отличие от большинства современных подходов, которые используют сложные нетренируемые пайплайны, LightOnOCR-1B является полностью сквозной тренируемой моделью. Это позволяет легко дообучать ее для конкретных языков или доменов, что особенно важно для адаптации под специфические требования.
Технические характеристики и производительность
Модель способна обрабатывать 5,71 страниц в секунду на одном GPU H100, что эквивалентно примерно 493 тысячам страниц в день. При текущих облачных тарифах это составляет менее $0,01 за 1000 страниц, делая решение в несколько раз дешевле запуска более крупных OCR-систем.
LightOnOCR построена на базе сильного визуального трансформера с облегченной языковой частью и дистиллирована из высококачественных открытых VLM-моделей. Модель успешно справляется со сложными макетами, включая таблицы, формы, чеки и научные обозначения.
Также доступны две дополнительные версии модели с сокращенным словарем на 32k и 16k токенов, которые предлагают дополнительное ускорение для европейских языков при сохранении практически той же точности.
Результаты тестирования
Качество распознавания
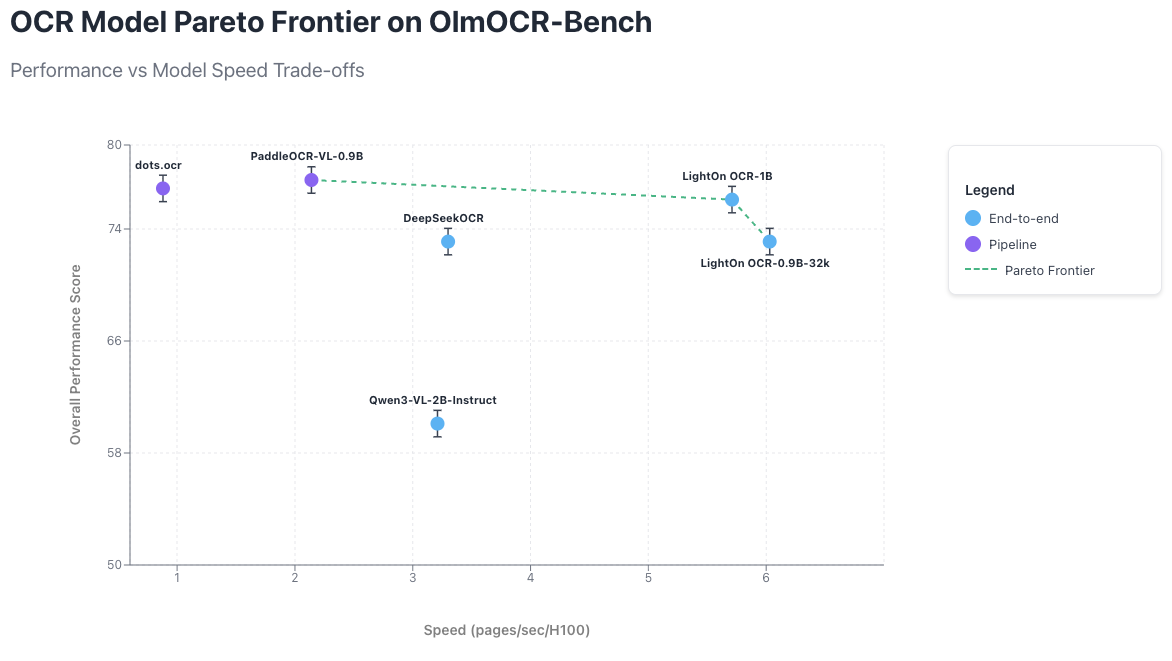
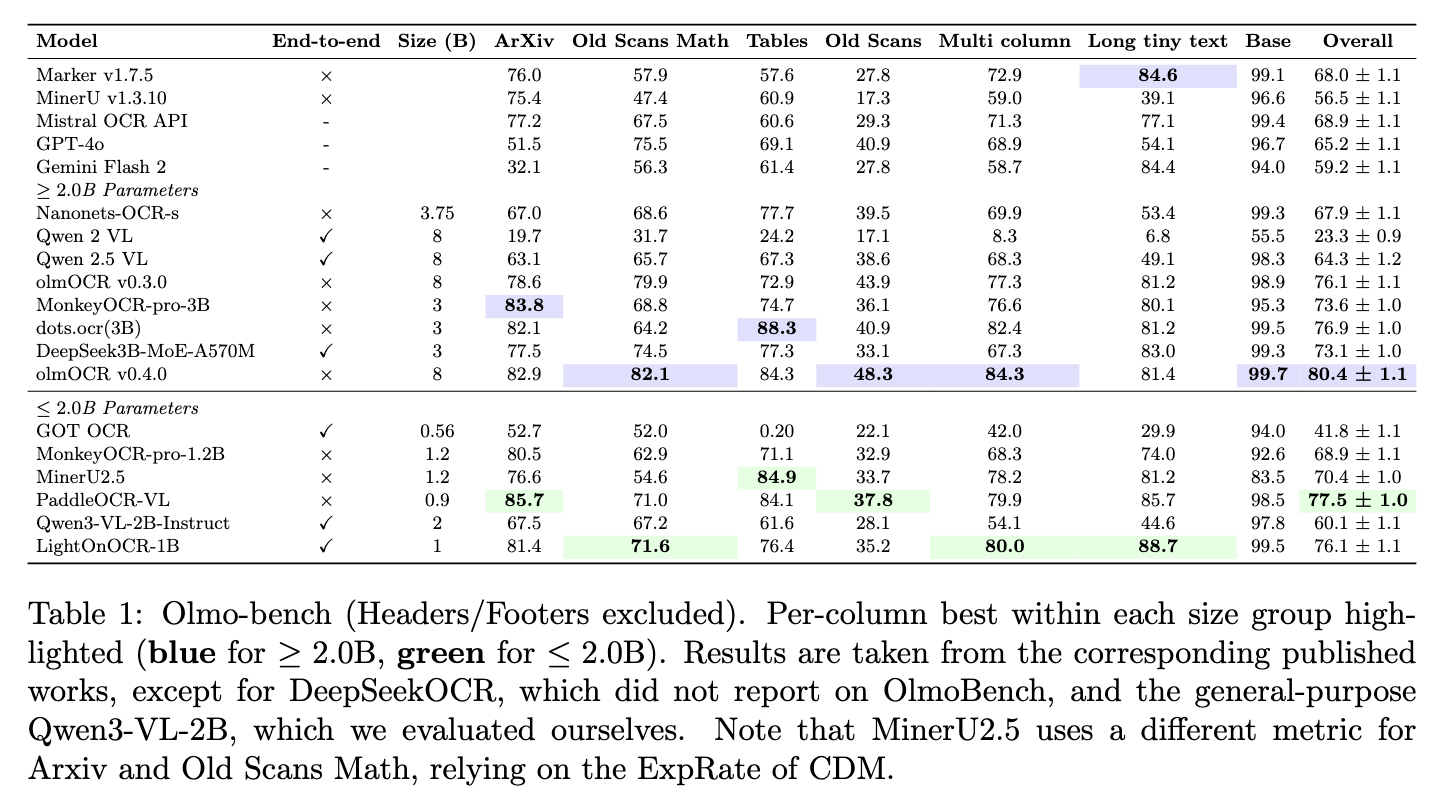
LightOnOCR демонстрирует результаты на уровне последних систем оптического распознавания текста. Модель достигает рекордной производительности на бенчмарке Olmo-Bench для своего размера и превосходит или близко соответствует значительно более крупным общим VLM-моделям — без какой-либо дообучки на данных OlmoOCR-mix.
LightOnOCR заметно обходит DeepSeek OCR и работает наравне с dots.ocr, несмотря на то, что последняя примерно в три раза больше. Модель также остается в пределах погрешности пайплайн-подхода PaddleOCR-VL и превосходит более крупную Qwen3-VL-2B на 16 общих баллов.
Скорость работы
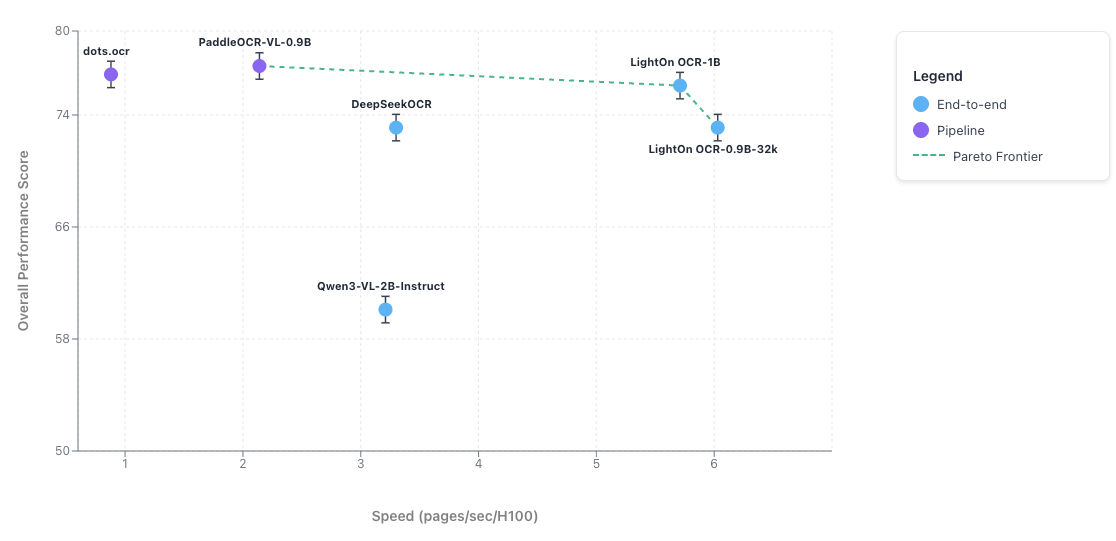
Для оценки компромисса между скоростью и качеством различных OCR-моделей использовался набор данных Olmo-Bench, содержащий 1402 PDF-документа. Все эксперименты проводились на одном GPU H100 (80 ГБ) с использованием vLLM для согласованности.
Пайплайн-подходы, такие как dots.ocr или PaddleOCR-VL, требуют множественных вызовов модели на страницу и вводят дополнительные накладные расходы на обрезку и предобработку. В отличие от них, наша сквозная модель выполняет один вызов на страницу и не использует логику повторных попыток или исправлений.
Простота развертывания
Разработчики предоставляют простую команду для развертывания модели через vLLM:
pip install -U vllm \
--torch-backend=auto \
--extra-index-url https://wheels.vllm.ai/nightly \
--prerelease=allow
vllm serve lightonai/LightOnOCR-1B-1025 \
--limit-mm-per-prompt '{"image": 1}' \
--async-scheduling
Специализированные модели для конкретных задач снова доказывают свою эффективность против универсальных решений. LightOnOCR демонстрирует, что для OCR не нужны гигантские модели — важнее правильная архитектура и качественные данные для обучения. Интересно, что эта тенденция наблюдается и в других областях компьютерного зрения, где узкоспециализированные модели часто превосходят более крупных собратьев. Особенно впечатляет стоимость обработки — менее цента за тысячу страниц открывает возможности для массовой оцифровки архивов и документов.
Разработчики обещают вскоре выпустить с открытой лицензией разнообразный крупномасштабный корпус PDF-документов, использованный для обучения модели, что может стать ценным ресурсом для сообщества.
По материалам Hugging Face.





Оставить комментарий