Оглавление
По сообщению Google Research, представлен CTCL — метод генерации дифференциально приватных синтетических данных без дообучения миллиардных LLM. Технология использует 140-миллионную модель и тематическую кластеризацию, решая ключевую проблему компромисса между приватностью, качеством данных и вычислительными затратами.
Как работает CTCL
Фреймворк разбит на три этапа:
- Предподготовка компонентов на публичных данных: CTCL-Topic (тематическая модель на 6 млн документов Wikipedia) выделяет 1K тем по 10 ключевых слов. CTCL-Generator (140M параметров, на базе BART-base) обучается на 430M пар «описание-текст», сгенерированных Gemma-2-2B.
- Анализ приватного датасета: CTCL-Topic строит тематическую гистограмму с применением дифференциальной приватности. CTCL-Generator дообучается с DP на парах «ключевые слова — документ».
- Генерация данных: Модель создаёт тексты по ключевым словам, пропорционально темам из DP-гистограммы. Благодаря свойству постобработки DP, объём синтетики неограничен без новых затрат приватности.
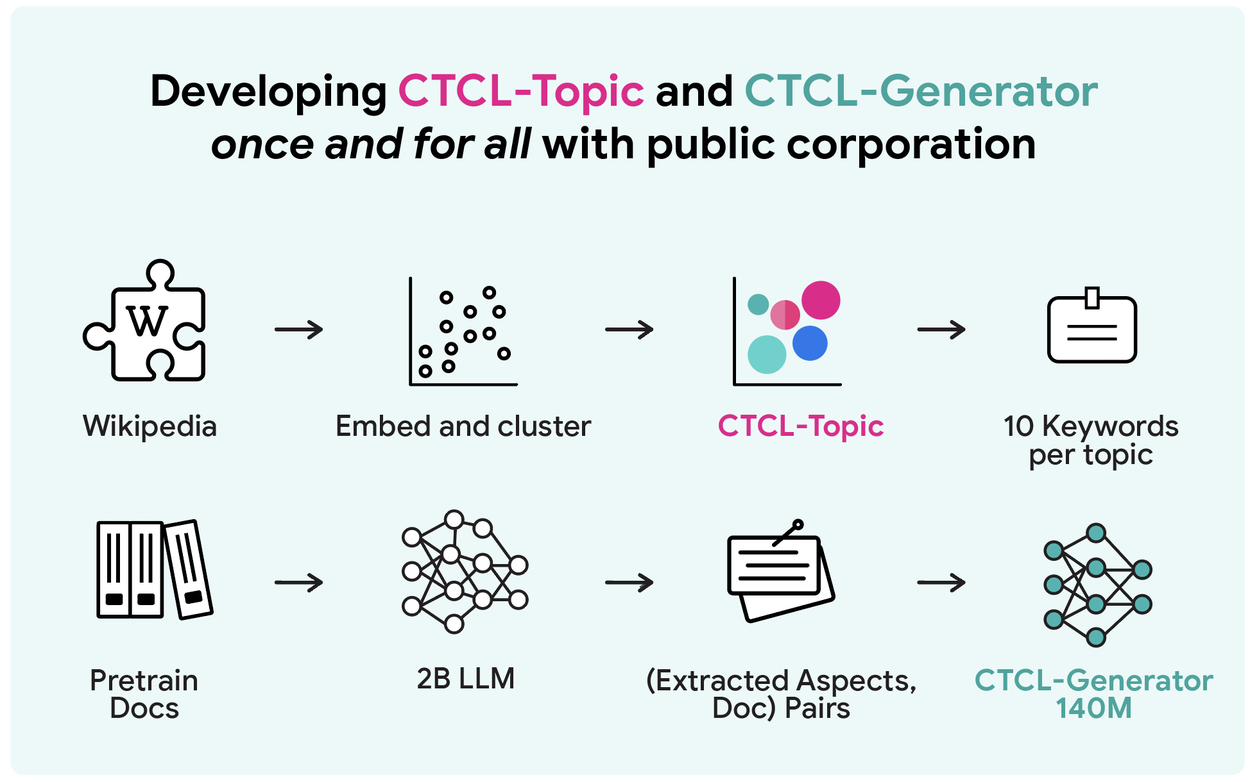
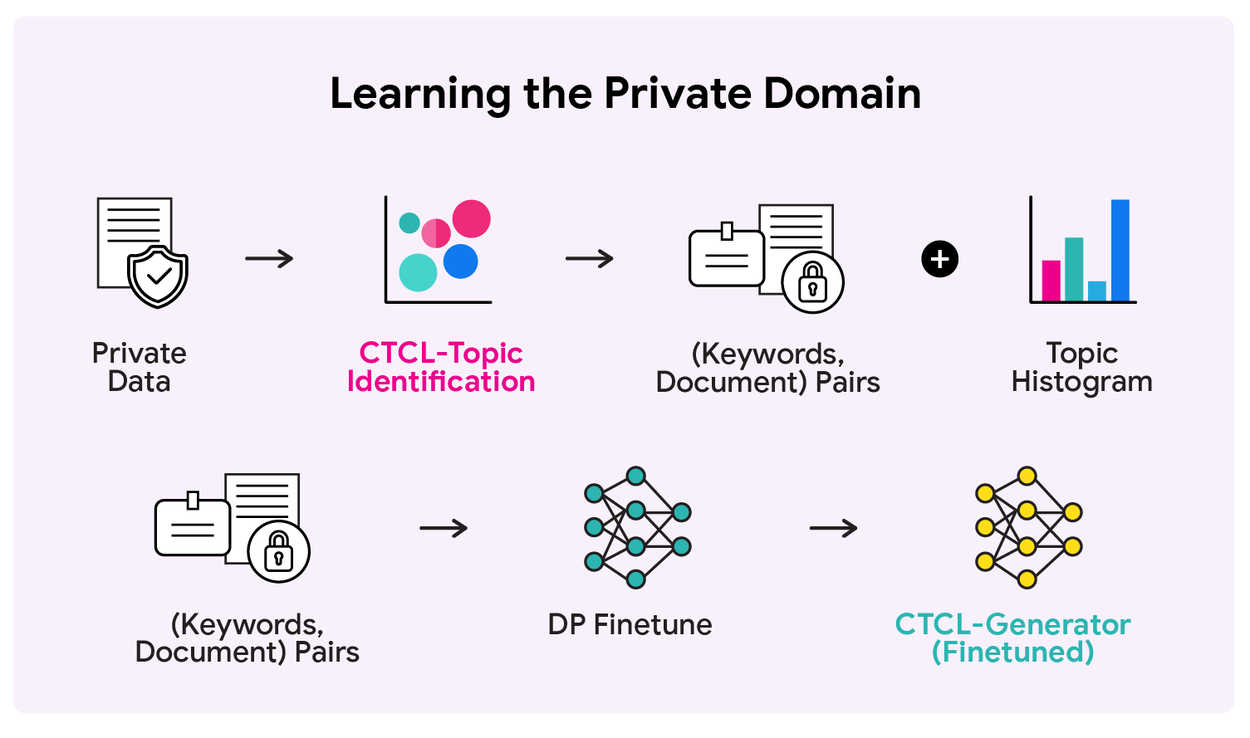
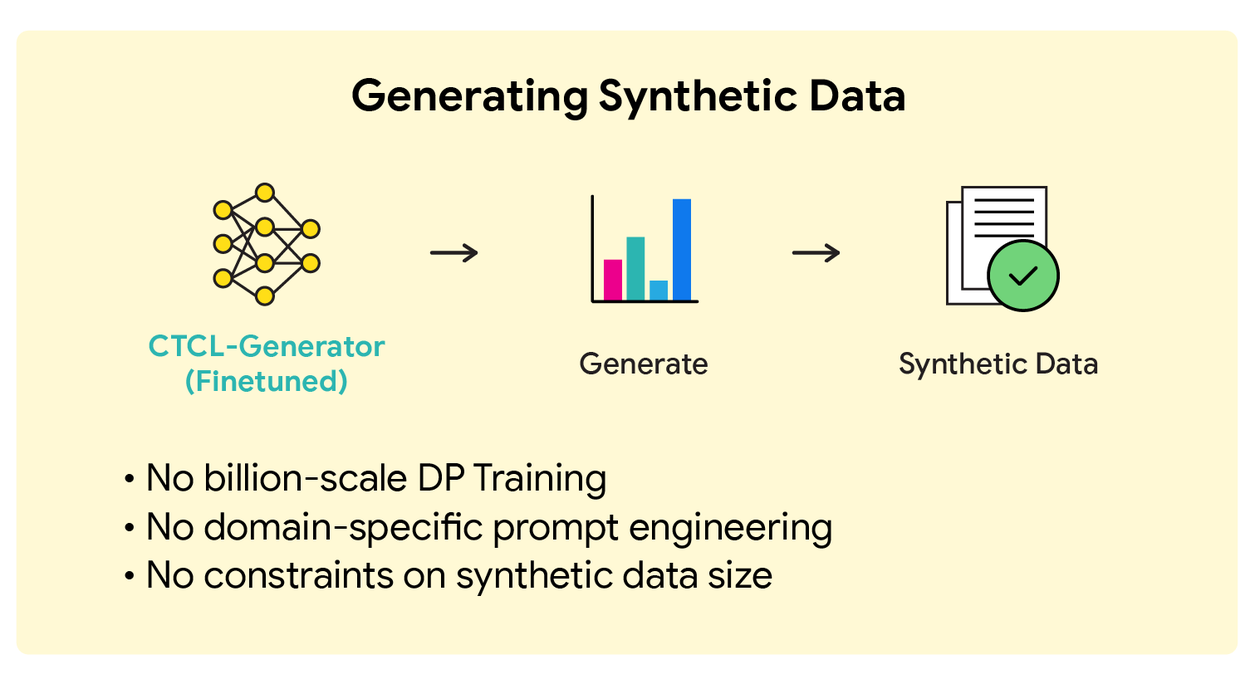
Результаты тестирования
Сравнение с аналогами (Aug-PE, Pre-Text) на четырёх датасетах:
- Генеративные задачи: CTCL на 12-18% точнее в предсказании токенов при высоких гарантиях приватности.
- Классификация: Стабильное сохранение связей «метка-текст».
- Производительность: В 4.7× меньше GPU-часов vs Aug-PE.
Это не просто оптимизация — это смена парадигмы. Вместо адаптации LLM-монстров Google предлагает контролируемую генерацию через лёгкую модель, что критично для медицинских или финансовых приложений с ограниченными ресурсами. Но вопрос масштабируемости остаётся: 1K тем хватит для Wikipedia, но для узкоспециальных данных? Ирония в том, что сам генератор обучен на выходе 2B-параметровой Gemma — зависимость от больших моделей никуда не делась. Тактика «маленький, но умный» работает, но проверка на реальных продуктах покажет, не потеряем ли мы детализацию в погоне за эффективностью.





Оставить комментарий