
Оглавление
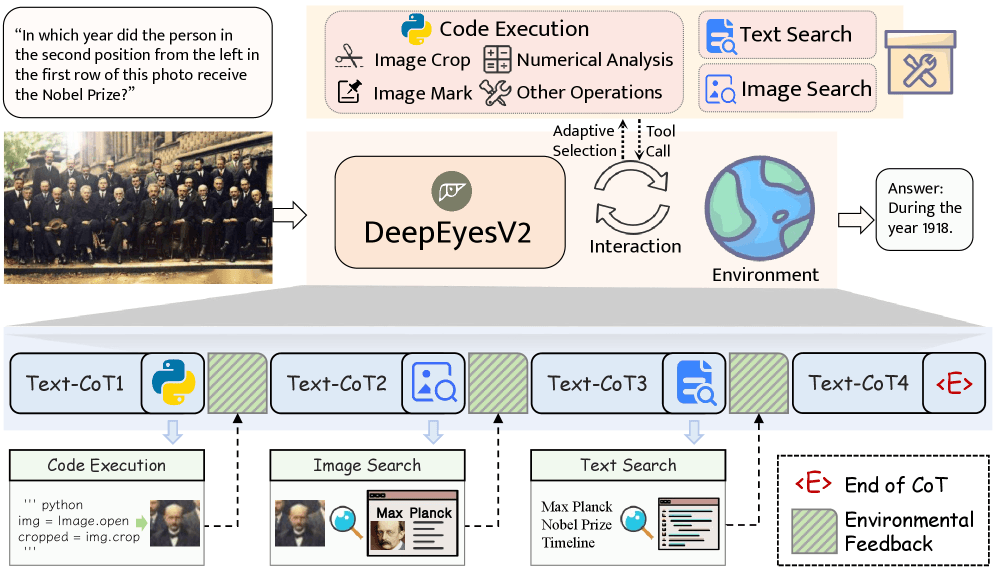
Китайские исследователи создали мультимодальную модель искусственного интеллекта, которая анализирует изображения, выполняет код и ищет информацию в интернете. Вместо того чтобы полагаться исключительно на знания, полученные во время обучения, DeepEyesV2 повышает производительность за счет интеллектуального использования внешних инструментов, что позволяет ей во многих случаях превосходить более крупные модели.
Во время ранних экспериментов команда исследователей из Xiaohongshu столкнулась с фундаментальной проблемой. Одного лишь обучения с подкреплением оказалось недостаточно для стабильного использования инструментов в мультимодальных задачах. Модели изначально пытались писать код на Python для анализа изображений, но часто генерировали ошибочные фрагменты. По мере продолжения обучения они и вовсе начали пропускать использование инструментов.
Почему мультимодальным моделям нужен новый подход к обучению
Эти трудности привели команду к разработке двухэтапного конвейера обучения. Фаза холодного старта учит модель связывать понимание изображений с использованием инструментов, за чем следует обучение с подкреплением для оттачивания этих поведенческих паттернов.

Для создания высококачественных демонстраций команда использовала ведущие модели, такие как Gemini 2.5 Pro, GPT-4o и Claude Sonnet 4, для генерации траекторий использования инструментов. Они сохраняли только те демонстрации, которые содержали правильные ответы и чистый код. Система вознаграждения при обучении с подкреплением была намеренно упрощена — награды привязывались к точности ответов и формату вывода.
DeepEyesV2 использует три категории инструментов для мультимодальных задач:
- Выполнение кода обрабатывает анализ изображений и численные вычисления
- Поиск изображений находит визуально похожий контент
- Текстовый поиск добавляет контекст, который не виден на изображении

Новый бенчмарк тестирует координацию изображений и инструментов
Для оценки этого подхода исследователи создали RealX-Bench — бенчмарк, предназначенный для тестирования того, насколько хорошо модели координируют визуальное понимание, веб-поиск и логические рассуждения. Один пример из исследования показывает, насколько сложными могут быть эти задачи. Когда модель просят определить тип цветка на картинке, она сначала обрезает релевантную область для захвата деталей. Затем она запускает визуальный веб-поиск с использованием обрезанного изображения для поиска похожих цветов и, наконец, объединяет эти результаты для определения вида.
Результаты демонстрируют значительный разрыв между моделями ИИ и человеческой производительностью. Даже самая сильная проприетарная модель достигла точности всего 46 процентов, тогда как люди показали результат в 70 процентов.
Задачи, требующие всех трех навыков, особенно сложны. Согласно исследованию, точность Gemini упала с 46 процентов в целом до всего лишь 27,8 процента, когда распознавание, логические рассуждения и поиск должны были работать вместе. Это падение подчеркивает, что современные модели могут справляться с отдельными навыками, но испытывают трудности с их интеграцией.

DeepEyesV2 достигла общей точности 28,3 процента. Это ставит ее выше базовой модели Qwen2.5-VL-7B с показателем 22,3 процента, хотя все еще позади версий с 32 и 72 миллиардами параметров. Но DeepEyesV2 превзошла другие модели с открытым исходным кодом в задачах, требующих координации всех трех возможностей.
Анализ также показал, что инструменты поиска играют важную роль в повышении точности, причем текстовый поиск обеспечивает наибольший прирост. Это говорит о том, что многие модели все еще испытывают трудности с осмысленным использованием информации только из визуального поиска.
Как использование инструментов помогает меньшим моделям конкурировать
DeepEyesV2 демонстрирует наибольшие успехи в специализированных бенчмарках. В задачах математических рассуждений она набрала 52,7 процента на MathVerse — улучшение на 7,1 пункта по сравнению с базовой моделью.
Модель также хорошо справляется с поисковыми задачами. Она достигла 63,7 процента на MMSearch, превзойдя специализированную модель MMSearch-R1 с показателем 53,8 процента. И в задачах повседневного понимания изображений модель DeepEyesV2 с 7 миллиардами параметров даже превзошла Qwen2.5-VL-32B, несмотря на то, что имеет более чем в четыре раза меньше параметров.
Эти результаты свидетельствуют о том, что хорошо структурированное использование инструментов может компенсировать ограничения меньших моделей. Вместо того чтобы полагаться на дополнительные параметры, DeepEyesV2 улучшает производительность за счет более эффективного привлечения внешних ресурсов.
Как DeepEyesV2 адаптирует стратегию к различным задачам
Анализ команды показывает четкие паттерны в том, как модель выбирает инструменты:
- Для задач визуального восприятия она часто обрезает изображение для выделения релевантной области
- Для математических задач на основе диаграмм она сочетает анализ изображений с численными вычислениями
- Для вопросов знаний с визуальной привязкой она запускает целенаправленные веб-поиски
Этот подход напоминает старую добрую стратегию «умный, а не сильный» — вместо наращивания параметров модель учится эффективно использовать доступные инструменты. Особенно впечатляет, что 7-миллиардная модель обходит 32-миллиардную в реальных задачах. Китайские исследователи демонстрируют, что в гонке ИИ качество архитектуры и методологии может быть важнее грубой вычислительной мощности. Хотя до человеческого уровня еще далеко, такие разработки делают ИИ более практичным и экономически эффективным.
Сообщает The Decoder.





Оставить комментарий